一种基于自监督深度学习的地貌知识图谱构建方法
本发明涉及地貌知识图谱研究,具体地说是一种基于自监督深度学习的地貌知识图谱构建方法。
背景技术:
1、地貌是最重要的自然地理要素之一,影响着地表气候、生态环境和自然资源的空间分布。地貌研究是地理学的一个重要分支,对了解地球表面的形态、结构、分布变化和规律具有重要作用,并且为人类的生存和发展提供科学依据。随着科技的发展,地貌学的研究日益信息化、智能化。上世纪九十年代末,随着地学信息图谱概念的提出,地貌学领域的学者们突破地貌信息提取、分类等关键技术,构建了地貌形态特征、地貌发育等信息图谱,实现对一系列地貌知识的总结和凝练。
2、当前知识图谱(knowledgegraph)成为信息领域的研究热点。知识图谱以结构化的有向图的形式表示知识,以节点和连边表示实体以及实体之间的关系,通过知识表示学习(knowledgegraph embedding)将实体和关系的语义映射到低维连续的向量空间,从而可以通过向量或矩阵操作实现知识推理和预测,因而知识图谱具有强大的语义计算能力,在语义检索、智能问答、个性推荐方面得到广泛应用,地学研究的多个领域也已开展领域知识图谱构建。
3、具体到地貌学领域,由于地貌本身存在边界模糊、类型难确定、多尺度的问题,使得地貌分类困难,地貌分类体系多样,不同体系之间难以统一,构建地貌知识本体存在困难。且地貌本身边界模糊难确定,目前的地貌类型划分均是以人的认知为核心,不是面向机器计算、以机器理解为核心的体系,难以实现计算机可理解并利用的定量表达和计算。
4、现有技术中的国内外研究需要专家知识,自上而下构建本体层,自动化程度不高,且现有地貌分类体系多样,难以构建统一的知识本体,根据本体从文本中抽取的三元组难以提供充足的各种地貌类型实体及其特征。
5、因此,为了解决上述问题,本申请提出了一种基于自监督深度学习的地貌知识图谱构建方法,通过深度学习领域自监督深度学习发展迅速。基于自监督学习策略的预训练模型在大量数据上进行训练,可在没有领域专家知识的情况下自动提取数据中的通用特征,形成适合dem数据的自监督深度学习模型和训练策略,达到能够充分学习地貌语义和空间特征的目的,探究人工智能视角下的地貌分类体系,实现自下而上自动化构建计算机可理解、可计算的地貌知识图谱。
技术实现思路
1、本发明的目的是填补现有技术的空白,提供了一种基于自监督深度学习的地貌知识图谱构建方法,通过深度学习领域自监督深度学习发展迅速。基于自监督学习策略的预训练模型在大量数据上进行训练,可在没有领域专家知识的情况下自动提取数据中的通用特征,形成适合dem数据的自监督深度学习模型和训练策略,达到能够充分学习地貌语义和空间特征的目的,探究人工智能视角下的地貌分类体系,实现自下而上自动化构建计算机可理解、可计算的地貌知识图谱。
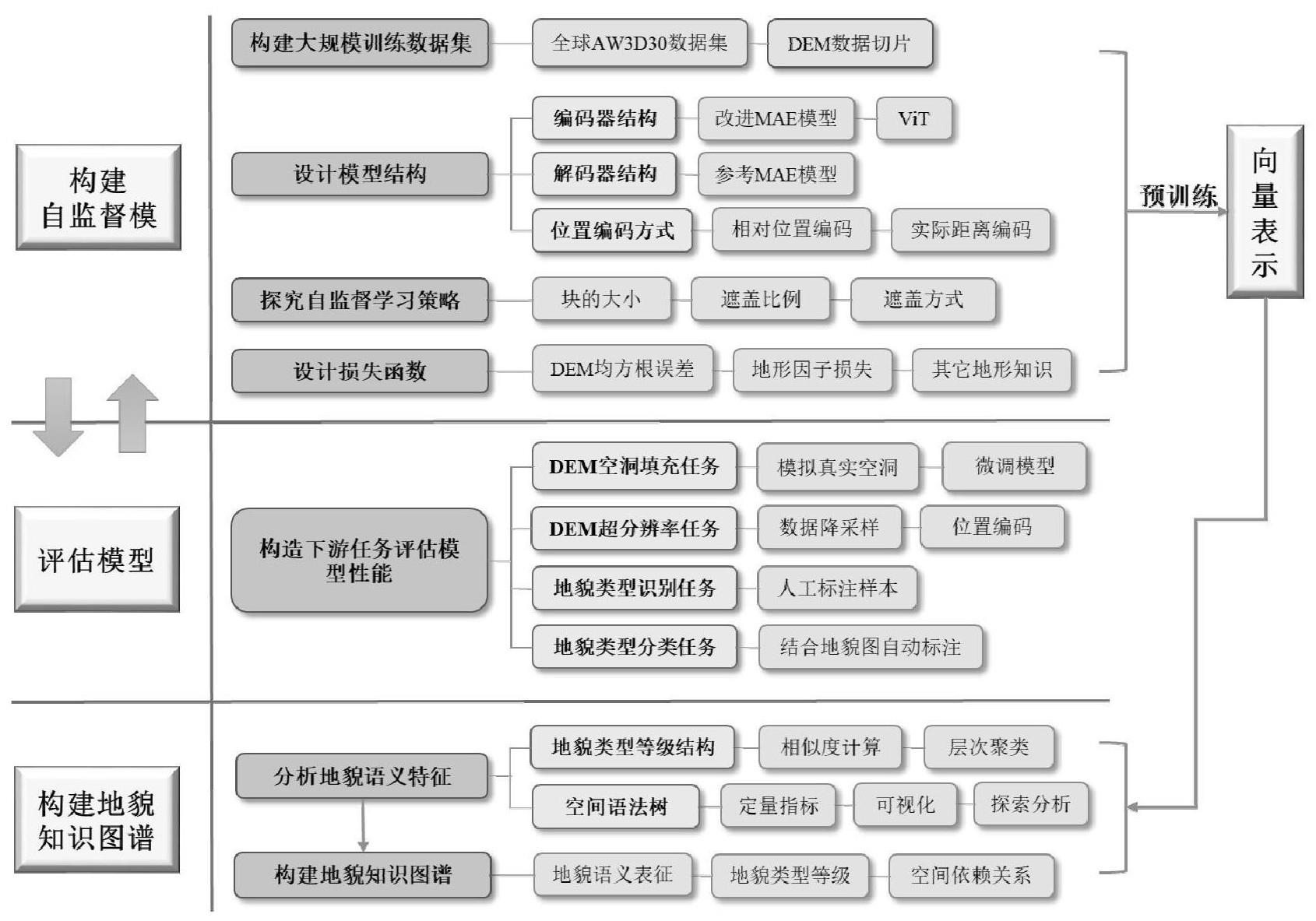
2、为了达到上述目的,本发明提供一种基于自监督深度学习的地貌知识图谱构建方法,包括自监督预训练模型构建、自监督预训练模型的评估和语义分析与知识图谱构建;
3、自监督预训练模型构建:完善自监督学习的策略,包括构建训练数据集、设计模型结构、探究学习策略和设计损失函数,并进行模型训练;
4、自监督预训练模型的评估:将预训练模型应用到下游任务中,评估模型的学习性能和迁移性能,并发现问题反馈到预训练模型,调节模型参数;
5、语义分析与知识图谱构建:对预训练得到的地貌向量表征进行语义分析,构建地貌知识图谱;
6、自监督预训练模型构建具体包括:
7、s1,预训练数据集:
8、利用现有不同分辨率的全球dem产品,构建大规模的预训练数据集的数据来源,随机选择部分区域构建预训练数据集,将数据切割为统一大小的栅格图幅,构建数据规模总量在900,000~1,000,000幅的预训练数据集,将较小比例的数据划分为验证集,其余作为训练集;
9、s2,模型设计:
10、构建自监督的dem深度学习模型,设计编码器和解码器的结构,选用mae模型的掩码结构以及基于vit模型的基本架构,将对比不同vit模型结构的性能,以及其他卷积神经网络模型的性能,通过多组对比实验,选定最佳模型,解决编码关键技术;
11、改变编码器数据输入方式,采用同一区域多分辨率数据同步输入的方法,使得模型同步学习不同分辨率特征;由于同样图幅不同分辨率数据的像素不一致,改变mae的像素位置编码方式,借鉴scale-mae的绝对距离编码方式,针对不同图幅之间地形的相关性,设计合适的位置编码方式,使得不同分辨率数据的位置信息保持一致,既要避免绝对位置编的信息泄露问题,又在一定程度上反映地形特征的周期性模式,并通过调整解码器结构,提高模型的对不同尺度数据的通用性;
12、s3,自监督学习策略:
13、完善自监督学习策略,探究不同超参数的设置,自监督学习采用图像掩码的方式,随机对dem图幅进行一定比例的遮盖,将未被遮盖的部分作为预训练模型的输入,通过编码器和解码器后得到恢复的图像,与原始图像相比计算损失,对模型进行优化;尝试不同数据遮盖方式或者以随机生成的任意形状遮盖数据,尝试不同的遮盖比例,探索最佳比例;
14、s4,损失函数:
15、设计合理的损失函数,在自监督学习过程中,最直接的指标是恢复的数值与真实数值之间的数值差异,引入地形因子控制模型的训练效果,并在损失函数中加入这些因子的损失值,使模型在优化时考虑地形因素;
16、语义分析与知识图谱构建具体包括:
17、s10,监督学习模型将地貌特征用向量表示,通过对向量的相似性计算,将特征相似且空间邻近的地块合并成地貌单元,一个地貌单元就是一个地貌类型实体;
18、s20,通过层次聚类,得到地貌类型的等级结构;
19、s30,通过自监督学习的注意力机制,得到每两个地块相互之间的注意力得分,构建注意力得分矩阵,计算地块之间的相互依赖程度,采用可视化分析,探索不同地貌实体之间的相互依赖关系,研究地貌类型分布空间模式,并构建地貌空间语法树;
20、s40,形成包含地貌类型等级结构、地貌实体语义表征和地貌类型空间关系的地貌知识图谱。
21、本发明同现有技术相比,在全球多分辨率dem数据上,学习多尺度的地貌类型语义和空间特征,形成以机器计算为目的的地貌特征向量表示。
22、通过探索,形成适合dem数据的自监督深度学习模型和训练策略,达到能够充分学习地貌语义和空间特征的目的;通过地貌特征向量表示的分析和计算,探究人工智能视角下的地貌分类体系,实现自下而上自动化构建计算机可理解、可计算的地貌知识图谱。
技术特征:
1.一种基于自监督深度学习的地貌知识图谱构建方法,其特征在于,包括自监督预训练模型构建、自监督预训练模型的评估和语义分析与知识图谱构建;
技术总结
本发明涉及地貌知识图谱研究技术领域,具体地说是一种基于自监督深度学习的地貌知识图谱构建方法,包括自监督预训练模型构建、自监督预训练模型的评估和语义分析与知识图谱构建,本发明同现有技术相比,在全球多分辨率DEM数据上,学习多尺度的地貌类型语义和空间特征,形成以机器计算为目的的地貌特征向量表示,构建一套计算机可理解、可计算、可推理的地貌知识图谱。
技术研发人员:许珺,杨家齐
受保护的技术使用者:中国科学院地理科学与资源研究所
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!