基于带有闭集噪声和开集噪声标签的鲁棒学习方法
本发明涉及一种基于带有闭集噪声和开集噪声标签的鲁棒学习方法。
背景技术:
1、深度神经网络(dnn)在各种任务中取得了显著的成功,例如图像分类、物体检测、语音识别和机器翻译。但需要注意的是,这样的成功主要归因于大量高质量注释的数据,而在实践中收集这些数据是昂贵甚至不可行的。事实上,现有的大部分基准数据集都是从搜索引擎或网络爬虫中收集的,这不可避免地涉及到噪声标记。
2、鉴于dnn的强大学习能力,模型最终将过度拟合噪声标记,导致泛化性能差。为了缓解这个问题,开发能够学习噪声标记的强大模型具有重要意义,而在存在闭集噪声的同时也存在开集噪声,因此,在这个问题中对开集噪声的处理至关重要。
3、曾有研究表明模型在训练过程中面对开集样本的行为,并观察到一些开集类别与多个闭集类别集成在一起,称之为class expansion。具体来说,对带标记的闭集样本进行训练,并对开集示例生成伪标记以促进学习,这种方法不会损害模型学习,甚至一些特定的开放集类别的示例得到了很好的分类。此外,其他开集示例均匀分布在多个封闭集类别中。另外,在训练过程中添加适当的开集示例甚至可以提高模型的性能。
技术实现思路
1、本发明的目的在于提出一种基于带有闭集噪声和开集噪声标签的鲁棒学习方法,该方法针对数据集中存在闭集噪声和开集噪声的问题,旨在最大限度地减少闭集错误标记示例的负面影响的同时,最大化有用的开集示例对模型学习过程中带来的收益。
2、本发明为了实现上述目的,采用如下技术方案:
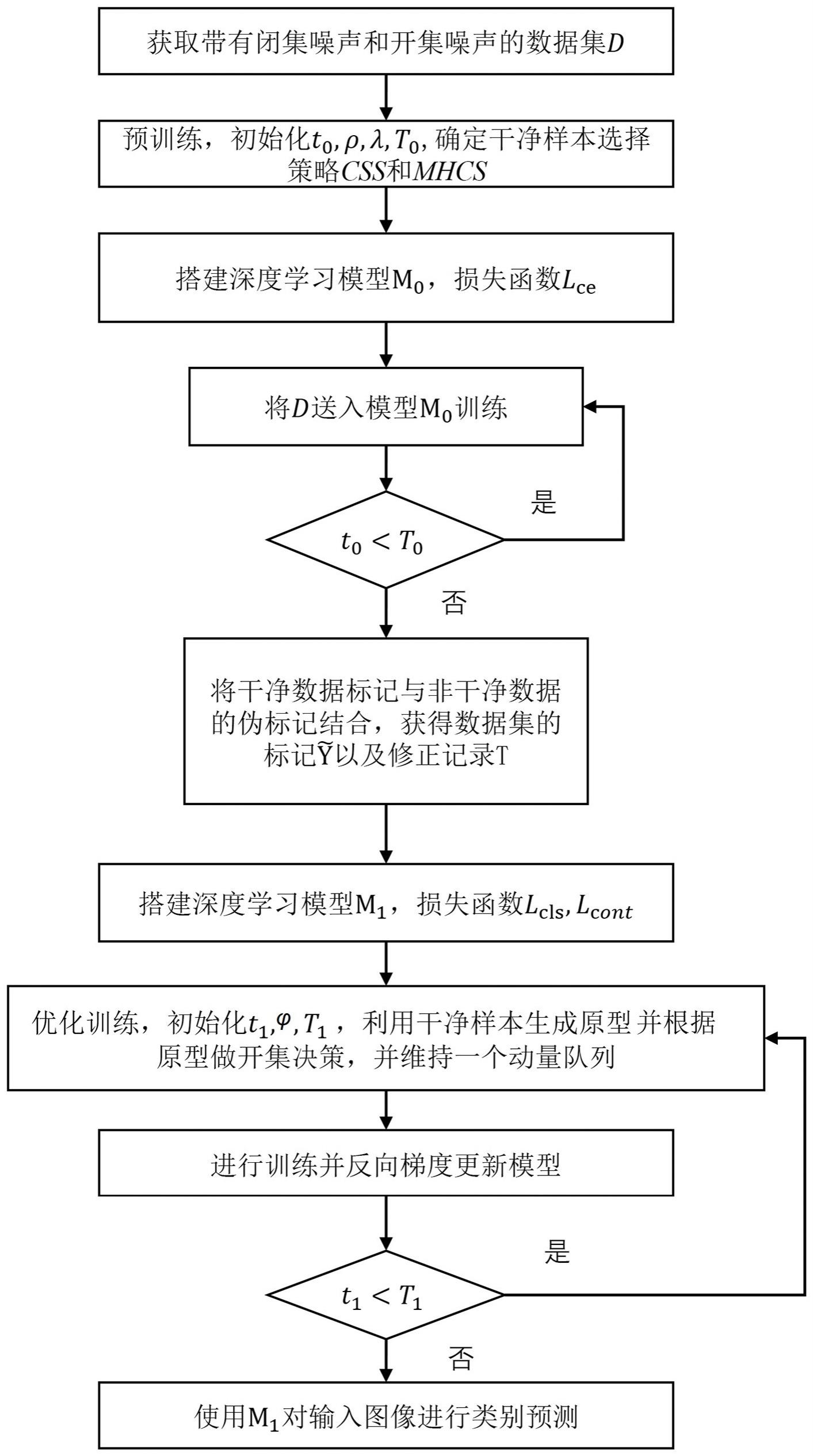
3、基于带有闭集噪声和开集噪声标签的鲁棒学习方法,包括以下步骤:
4、步骤1. 获取带有闭集噪声和开集噪声的数据集;其中, d表示由图像 x i以及对应的噪声标记 y i组成的数据集, n为 d中的样本总数, i=1,…, n;
5、步骤2. 开始预训练,并初始化当前预训练次数 t0和预训练总次数 t0;确定干净样本挑选方法,并初始化干净样本筛选率参数 ρ和 λ;
6、步骤3. 搭建深度学习模型 m0以及损失函数 l ce;
7、步骤4. 将数据集 d中图像 x i和对应的标记 y i输入到模型 m0进行预训练,训练 t0轮,在预训练阶段样本输入模型后获得对应的输出,并结合标记计算出样本的交叉熵损失;
8、步骤5. 判断当前预训练次数 t0是否达到预训练总次数 t0;
9、若当前预训练次数 t0未达到预训练总次数 t0,返回步骤4继续训练;否则进行如下处理:
10、对得到的数据集 d上所有样本的交叉熵损失从小到大进行升序排列,然后根据干净样本挑选方法选择干净样本参与训练,并为非干净样本打上伪标记;
11、将干净样本作为有监督数据集 d clean,将非干净样本作为无监督数据集 d dirty;
12、步骤6. 将干净样本标记与非干净样本的伪标记结合,获得数据集 d上的更为精确的标记以及修正记录 t,用于下述步骤8中的优化训练阶段;
13、步骤7. 重新搭建深度学习模型 m1以及分类损失 l cls、对比损失 l cont;其中,分类损失 l cls用于帮助模型分类,对比损失 l cont用于帮助模型获得更优的表征学习能力;
14、步骤8. 开始优化训练,并初始化当前训练次数 t1和训练总次数 t1,利用干净样本生成类别原型;并根据原型做开集决策;并维持一个动量队列;
15、步骤9. 判断当前训练次数 t1是否达到训练总次数 t1;若当前训练次数 t1未达到训练总次数 t1,则返回步骤8继续训练;否则转到步骤10;
16、步骤10. 模型训练完成后,得到能够在数据集上执行分类预测任务的深度学习模型 m1,利用该训练好的深度学习模型 m1对输入图像进行类别预测。
17、本发明具有如下优点:
18、如上所述,本发明述及了一种基于带有闭集噪声和开集噪声标签的鲁棒学习方法,该方法提出了一个两步学习框架来解决开集噪声标记学习问题,旨在利用有用的开集示例,同时最大限度地减少闭集错误标记示例的负面影响。在第一步中,本发明采用成熟的方法来处理噪声标记,并保持闭合集类别的基本概念,为了进一步提高模型的预测准确性,本发明采用改良过的对比学习方案,在第二步训练过程中包括选择的开集示例,此外,本发明使用其余被忽略的开集示例作为分界点,以增强模型的表示学习能力。
技术特征:
1.基于带有闭集噪声和开集噪声标签的鲁棒学习方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于带有闭集噪声和开集噪声标签的鲁棒学习方法,其特征在于,所述步骤2中,干净样本挑选方法包括css以及mhcs样本选择方法。
3.根据权利要求1所述的基于带有闭集噪声和开集噪声标签的鲁棒学习方法,其特征在于,所述步骤2中,ρ用于控制每类挑选样本数量均衡,λ为挑选样本的置信度阈值。
4.根据权利要求1所述的基于带有闭集噪声和开集噪声标签的鲁棒学习方法,其特征在于,所述步骤4中,深度学习模型m0包括特征提取器f以及分类器g;
5.根据权利要求1所述的基于带有闭集噪声和开集噪声标签的鲁棒学习方法,其特征在于,所述步骤6具体为:
6.根据权利要求1所述的基于带有闭集噪声和开集噪声标签的鲁棒学习方法,其特征在于,所述步骤7具体为:
7.根据权利要求6所述的基于带有闭集噪声和开集噪声标签的鲁棒学习方法,其特征在于,所述步骤8具体为:
技术总结
本发明公开了一种基于带有闭集噪声和开集噪声标签的鲁棒学习方法,该方法旨在利用有用的开集示例,同时最大限度地减少闭集错误标记示例的负面影响。本发明分为两个阶段,第一阶段中,利用干净样本选择策略做训练初始化,并记录下来样本修正标记以及标记修正记录供第二阶段优化;在第二阶段中,利用Class Expansion的思想,将部分开集样本融入已知类进行训练,将剩余的具有判别性的开集样本进一步帮助模型提升其判别性。本发明方法针对数据集中存在闭集噪声和开集噪声的问题,使用了类扩展的思想,接纳了一部分开集类别样本,并且充分利用了剩余的开集样本,进一步提升了深度学习模型的准确率。
技术研发人员:李绍园,万文海,陈松灿
受保护的技术使用者:南京航空航天大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!