一种低延迟高性能实时数据仓库搭建的方法和系统与流程
本发明涉及的是数据仓库领域,特别涉及一种低延迟高性能实时数据仓库的搭建方法。
背景技术:
1、随着大数据时代的到来,从海量数据中挖掘出有效的信息来指导人们做决策分析已成为越来越重要的应用场景。业内现有的olap大数据分析系统一般是采用lambda架构构建实时数据仓库来完成的。然而,依照现有的技术方案所构建出的实时数仓还存在诸多缺点,主要包括:
2、结构化数据采集延时较大。传统的大数据平台在采集结构化数据(例如关系数据库)时,需要用sql语句去数据库中抽取需要的数据,当数据量较大时,sql执行的性能很差,一般存在几秒到几分钟的延迟,导致数据分析的计算结果也存在一定的延迟;
3、结构化数据实现增量采集限制条件较多。传统大数据平台进行数据增量采集时,需要原始表结构拥有数据最后更新时间标记,再配合定时任务完成增量数据采集。如果原始数据表没有最后更新时间则无法进行数据增量同步。并且,这种采集方式无法捕获数据删除操作也是数据同步中的一大痛点。
4、数据分析实时性不高。在传统的lambda架构中,维护了一条离线数据分析管道,由于离线计算往往需要执行几分钟到几小时不等,当天全量的数据统计结果需要等到第二天才能看到,这种t+1的设计对用户体验非常不好,达不到立竿见影的效果。
技术实现思路
1、鉴于上述问题,提出了本发明提供一种克服上述问题或者至少部分地解决上述问题的一种低延迟高性能实时数据仓库搭建的方法和系统。
2、为了解决上述技术问题,本申请实施例公开了如下技术方案:
3、本发明公开了一种低延迟高性能实时数据仓库搭建的方法,包括:
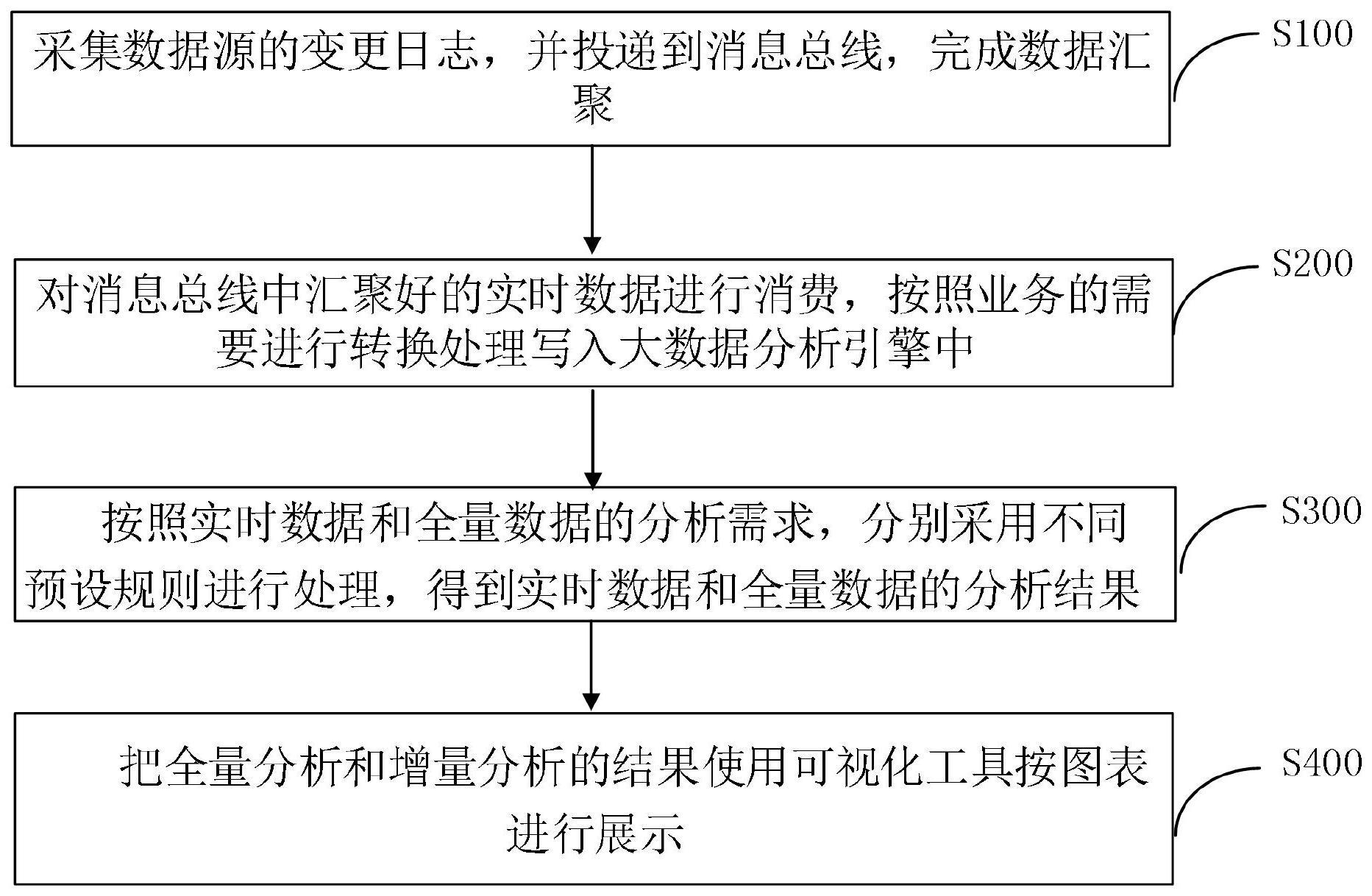
4、s100.采集数据源的变更日志,并投递到消息总线,完成数据汇聚;
5、s200.对消息总线中汇聚好的实时数据进行消费,按照业务的需要进行转换处理写入大数据分析引擎中;
6、s300.按照实时数据和全量数据的分析需求,分别采用不同预设规则进行处理,得到实时数据和全量数据的分析结果;
7、s400.把全量分析和增量分析的结果使用可视化工具按图表进行展示。
8、进一步地,s100中,采集数据源的写入日志,具体包含数据的修改、新增和删除操作,将数据变更日志按照一定的格式组装好投递到消息总线。
9、进一步地,s100中,采集数据源变更日志的每条消息应当包含原始数据的前值和现值。对于新增操作,前值为空;删除操作,现值为空;修改操作两者都不为空。
10、进一步地,s200中,采用实时计算框架flink消费kafka中的实时数据,并将消费后的实时数据写入到olap引擎elasticsearch或clickhouse中。
11、进一步地,s300中,对于实时数据的统计分析,具体为时间窗口计算、当日增量数据分析需求时,直接消费消息总线中的数据进行实时计算,把计算结果写入内存数据库中,满足业务中实时分析频繁读写的需要。
12、进一步地,s300中,对于全量数据分析需求,直接向大数据分析引擎发送查询请求得到统计结果。
13、本发明一种低延迟高性能实时数据仓库搭建的系统,包括:数据汇聚单元、实时数据消费单元、实时数据和全量数据分析单元和全量分析和增量分析结果展示单元;其中:
14、数据汇聚单元,用于采集数据源的变更日志,并投递到消息总线,完成数据汇聚;
15、实时数据消费单元,用于对消息总线中汇聚好的实时数据进行消费,按照业务的需要进行转换处理写入大数据分析引擎中;
16、实时数据和全量数据分析单元,用于按照实时数据和全量数据的分析需求,分别采用不同预设规则进行处理,得到实时数据和全量数据的分析结果;
17、全量分析和增量分析结果展示单元,用于把全量分析和增量分析的结果使用可视化工具按图表进行展示。
18、进一步地,数据汇聚单元,采集数据源的写入日志,具体包含数据的修改、新增和删除操作,将数据变更日志按照一定的格式组装好投递到消息总线;采集数据源的变更日志的每条消息应当包含原始数据的前值和现值。对于新增操作,前值为空;删除操作,现值为空;修改操作两者都不为空。
19、进一步地,实时数据和全量数据分析单元,对于实时数据的统计分析,具体为时间窗口计算、当日增量数据分析需求时,直接消费消息总线中的数据进行实时计算,把计算结果写入内存数据库中,满足业务中实时分析频繁读写的需要;对于全量数据分析需求,直接向大数据分析引擎发送查询请求得到统计结果。
20、本发明还公开了一种电子设备,包括:
21、存储器,用于存储可由处理器执行的指令;
22、处理器,用于执行所述指令以实现一种低延迟高性能实时数据仓库搭建的方法。
23、本发明实施例提供的上述技术方案的有益效果至少包括:
24、本发明公开的一种低延迟高性能实时数据仓库搭建的方法和系统,在整个过程中,全量数据的统计分析交给了高性能大数据分析引擎来完成,用于替代lambda架构中的离线计算,通常获取查询结果只需要数秒钟。在整个实时数仓的架构中,实时计算框架起到了承上启下的作用,一方面提供etl能力,将消息总线中的数据按照业务逻辑的需要进行转换清洗写入大数据分析引擎;另一方面提供增量数据的实时计算能力,把实时分析的结果写入内存数据库。把实时分析的业务需求交给实时计算框架来做,也可以减少大数据分析引擎的查询压力,让整个系统的性能更佳。
25、本发明提供的实时数仓搭建方法与lambda架构中传统的做法相比,具有以下优点:
26、1.低延迟。本发明采集数据时并非直接抽取原始数据来实现,而是巧妙地采集数据源的变更日志进行重放。整个过程不需要执行sql语句,只需要捕获日志文件的行,让数据抽取变得更加轻便。因为这个过程不直接读取数据源,所以不会影响线上系统的运行。这种数据采集方式能够将采集数据的延迟从几秒钟或几分钟缩短到毫秒级,延迟降低了十几倍。
27、2.采集数据更简便。传统的数据采集方式抽取的是数据源本身,难以捕获删除的数据,对于新增和更新的记录需要打上数据最后更新时间标记,较为繁琐。而现有的增量数据采集模式可以捕获数据的删除操作,而且不需要打数据修改时间标记,实现更加简单。并且,本发明提出的数据采集方式既可以用于结构化数据,也可以用于半结构化的数据,只要有数据操作日志就可以达到效果。
28、3.性能高。对于全量数据的统计分析,传统的解决方案在lambda架构中使用离线计算来完成,一般需要几分钟到几小时才能得到计算结果。本发明使用高性能的大数据分析引擎做全量数据分析,一般三秒钟之内就能得出分析结果,分析性能提升了几十到几百倍。全量数据分析的查询方式从t+1提前至t+0,大大提升了用户体验。
29、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
技术特征:
1.一种低延迟高性能实时数据仓库搭建的方法,其特征在于,包括:
2.如权利要求1所述的一种低延迟高性能实时数据仓库搭建的方法,其特征在于,s100中,采集数据源的写入日志,具体包含数据的修改、新增和删除操作,将数据变更日志按照一定的格式组装好投递到消息总线。
3.如权利要求2所述的一种低延迟高性能实时数据仓库搭建的方法,其特征在于,s100中,采集数据源的变更日志的每条消息应当包含原始数据的前值和现值。对于新增操作,前值为空;删除操作,现值为空;修改操作两者都不为空。
4.如权利要求1所述的一种低延迟高性能实时数据仓库搭建的方法,其特征在于,s200中,采用实时计算框架flink消费kafka中的实时数据,并将消费后的实时数据写入到olap引擎elasticsearch或clickhouse中。
5.如权利要求1所述的一种低延迟高性能实时数据仓库搭建的方法,其特征在于,s300中,对于实时数据的统计分析,具体为时间窗口计算、当日增量数据分析需求时,直接消费消息总线中的数据进行实时计算,把计算结果写入内存数据库中,满足业务中实时分析频繁读写的需要。
6.如权利要求1所述的一种低延迟高性能实时数据仓库搭建的方法,其特征在于,s300中,对于全量数据分析需求,直接向大数据分析引擎发送查询请求得到统计结果。
7.一种低延迟高性能实时数据仓库搭建的系统,其特征在于,包括:数据汇聚单元、实时数据消费单元、实时数据和全量数据分析单元和全量分析和增量分析结果展示单元;其中:
8.如权利要求7所述的一种低延迟高性能实时数据仓库搭建的系统,其特征在于,数据汇聚单元,采集数据源的写入日志,具体包含数据的修改、新增和删除操作,将数据变更日志按照一定的格式组装好投递到消息总线;采集数据源的变更日志的每条消息应当包含原始数据的前值和现值。对于新增操作,前值为空;删除操作,现值为空;修改操作两者都不为空。
9.如权利要求7所述的一种低延迟高性能实时数据仓库搭建的系统,其特征在于,实时数据和全量数据分析单元,对于实时数据的统计分析,具体为时间窗口计算、当日增量数据分析需求时,直接消费消息总线中的数据进行实时计算,把计算结果写入内存数据库中,满足业务中实时分析频繁读写的需要;对于全量数据分析需求,直接向大数据分析引擎发送查询请求得到统计结果。
10.一种电子设备,其特征在于,包括:
技术总结
本发明公开了一种低延迟高性能实时数据仓库搭建的方法和系统,所述方法包括:采集数据源的变更日志,并投递到消息总线,完成数据汇聚;对消息总线中汇聚好的实时数据进行消费,按照业务的需要进行转换处理写入大数据分析引擎中;按照实时数据和全量数据的分析需求,分别采用不同预设规则进行处理,得到实时数据和全量数据的分析结果;把全量分析和增量分析的结果使用可视化工具按图表进行展示。本发明公开的一种低延迟高性能实时数据仓库搭建的方法,与Lambda架构中传统的做法相比,不但大大降低了数据延迟,而且大幅提升了全量分析的查询性能,为低延迟高性能的大数据分析提供了技术解决方案。
技术研发人员:王深湛,万龙,彭康,孙涛
受保护的技术使用者:南斗六星系统集成有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!