基于Transformer的视频多注意力机制的时序动作检测方法
本发明涉及深度学习视频理解,具体指一种基于transformer的视频多注意力机制的时序动作检测方法。
背景技术:
1、视频市场的快速增长受益于移动互联网和智能数字设备等方面的技术创新。如今,智能移动设备可存储数千个视频,移动应用程序允许用户通过移动互联网方便地访问数百视频网站。因此,视频理解在许多领域都变得愈发重要。而对于时序动作检测则可以用于视频分析,或在海量的视频数据中进行视频检索等等方面。而随着视频多样性的增加,传统的手工特征方法的效率和效果都已达不到相应的要求,于是深度学习的方法开始逐步取代传统的方法。
2、在当前的人工智能深度学习方法中,时序动作检测通常使用两种方式来实现。第一种就是基于卷积神经网络(cnns)的方法。卷积神经网络(cnns)多年来一直在视觉领域发挥着重要作用。在视频理解任务中也是如此。3d卷积网络可以像视频一样自然地处理3d数据,因此许多3d卷积网络在这项任务中取得了巨大突破。然而,这种3d网络往往具有大量的参数,而卷积网络有限的感受野使这些网络无法捕捉长期的时空依赖关系。因此,在视频内容日益多样化的今天,卷积网络模型相对就越来越受限制。第二类是基于transformer的方法。最初用于自然语言处理领域的transformer模型已逐渐应用于视觉领域并取得了显著成果。然而,这种方法有一个缺点就是当模型的输入序列过长时,这些模型所需要的代价就非常昂贵,主要是因为transformer模型中核心的自注意力机制需要消耗大量的计算资源。因此,针对这一问题,设计出一个有效的方法来提升动作检测准确率的同时能够降低传统transformer方法的计算消耗是很有必要的。
技术实现思路
1、针对现有技术所存在的上述技术问题,本发明提出一种基于transformer的视频多注意力机制的时序动作检测方法,能够提升动作检测的准确率,同时效率比传统的transformer模型更高。
2、为了解决上述技术问题,本发明的技术方案为:
3、一种基于transformer的视频多注意力机制的时序动作检测方法,包括如下步骤:
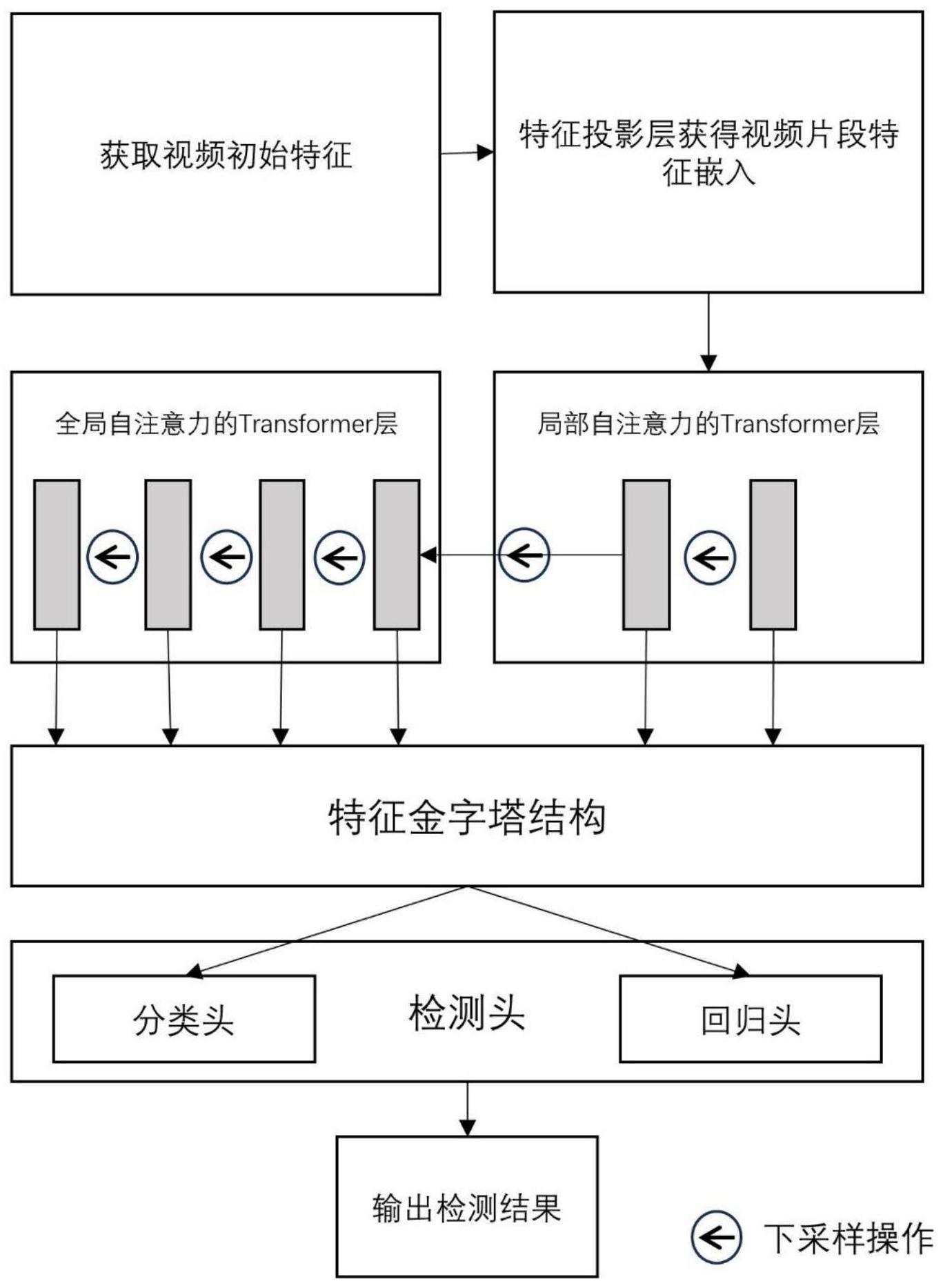
4、s1、获取待检测的视频图像,将视频帧经过预训练的视频模型提取初始视频特征,作为基于transformer的多自注意力机制的时序动作检测模型的输入;
5、s2、将所述视频特征输入到一个浅层卷积网络进行投影得到视频片段特征嵌入;
6、s3、将所述所有特征嵌入输入到局部自注意力的transformer模块(latm)输出其局部样式特征;
7、s4、将所述的局部样式特征输入到全局自注意力的transformer模块(gatm)对长期依赖进行建模;
8、s5、将所述的每个transformer层的输出经过下采样后输入到下一个transformer层,最终每个transformer层的输出构建为特征金字塔结构;
9、s6、将特征金字塔的每一层输入到检测头中,检测头中包括回归头和分类头,分别输出最终动作的时序边界和类别。
10、作为优选,在步骤s2中,一个用于投影的浅层卷积网络,具体包括:两层卷积核大小为3,步长为1的一维卷积网络;最后通过一个relu激活函数。
11、作为优选,在s3步骤中,通过局部自注意力的transformer模块(latm)获得局部样式特征,具体包括:
12、设置latm模块中transformer的层数l;
13、在transformer结构中,分别经过层归一化、多头局部自注意力操作、残差连接、层归一化、多层感知机、残差连接操作获得局部样式信息;
14、作为优选,在步骤s4中,通过全局自注意力的transformer模块(gatm)获得长期依赖信息,具体包括:
15、设置gatm模块中transformer的层数g;
16、在transformer结构中,分别经过层归一化、多头全局自注意力操作、残差连接、层归一化、多层感知机、残差连接操作获得长期依赖信息;
17、作为优选,在步骤s5中,每个transformer层的输出经过下采样后输入到下一个transformer层,具体包括:
18、将latm和gatm中的每个transformer层的输出都通过最大池化层进行下采样,然后再输入到下一层的transformer层中;
19、每个transformer层的特征输出构建为一个特征金字塔结构。
20、作为优选,在步骤s6中,特征金字塔的每一层输入到检测头得到最终动作的时序边界和类别,具体包括:
21、在分类头中,输入特征通过共享权重的两个带有层归一化和relu激活函数的一维卷积网络,再通过一个一维卷积和一个sigmoid函数得到最终的分类结果;
22、在回归头中,选定某一时刻特征t,以该时刻选择相邻s个时刻特征组合为一个片段特征,分别输入到边界回归器和偏移回归器中,得到一个片段的位置特征和偏移量。然后将片段中的每个时刻的位置特征与偏移量相加得到该时刻的边界特征。将一个片段的边界特征通过softmax函数得到边界概率分布,以片段特征中其他时刻与t之间的距离计算偏移的的期望值,将当前的时刻与偏移的期望值相加就得到最终的动作时序边界。
23、本发明具有以下的特点和有益效果:
24、采用上述技术方案,首先通过预训练模型获取待识别视频的初始特征,将初始特征输入到动作检测模型中,在模型网络的浅层阶段,使用局部自注意力机制的transformer结构来建模局部样式特征,同时能够减少大量的计算,然后通过最大池化层进行下采样操作,使得特征分辨率减小到一定范围后再通过全局自注意力机制的transformer结构来建模长期依赖关系。每一层transformer结构输出分辨率不同的时空特征就构建成了一个特征金字塔结构,将特征金字塔的每一层分别输入到由分类头和回归头组成的检测头中得到动作的分类结果和时序边界。特别的,在回归头中,结合时刻特征和片段特征,以计算片段内多个时刻特征边界偏移期望的方式得到最终的动作时序边界,使得更加精确地定位动作边界。
技术特征:
1.一种基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,所述步骤s2中,浅层卷积网络包括两层一维卷积层,卷积核大小为3,步长为1,每个卷积层后加一个relu激活函数。
3.根据权利要求1所述的基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,所述latm中transformer网络的层数为l,其中l=2;所述gatm中transformer网络的层数为g,其中g=4。
4.根据权利要求3所述的基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,在每个所述transformer网络的后面加上一个最大池化层达到下采样的效果,下采样率为2。
5.根据权利要求4所述的基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,所述latm和gatm中每个transformer网络的输出经过下采样后输入到下一个transformer网络。
6.根据权利要求3所述的基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,所述步骤s3中,latm输出局部样式特征的方法为:
7.根据权利要求3所述的基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,所述步骤s4中,gatm输出长期依赖信息的方法为:所述步骤s6中,检测头包括分类头和回归头。
8.根据权利要求7所述的基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,所述步骤s6中,通过分类头输出动作类别概率来判断所属的动作类别。
9.根据权利要求7所述的基于transformer的视频多注意力机制的时序动作检测方法,其特征在于,所述步骤s6中,通过回归头定位动作的起始位置和结束位置。
技术总结
本发明公开了一种基于Transformer的视频多注意力机制的时序动作检测方法,包括如下步骤:S1、获取待检测的视频图像,将视频帧经过预训练的视频模型提取初始视频特征;S2、将所述视频特征输入到一个浅层卷积网络进行投影得到视频片段特征嵌入;S3、将所有特征嵌入输入到局部自注意力的Transformer模块输出其局部样式特征;S4、将所述的局部样式特征输入到全局自注意力的Transformer模块对长期依赖进行建模;S5、最终每个Transformer层的输出构建为特征金字塔结构;S6、将特征金字塔的每一层输入到检测头中,检测头中包括回归头和分类头,分别输出最终动作的时序边界和类别。该方法能够提升动作检测的准确率,同时效率比传统的Transformer模型更高。
技术研发人员:张万军,周福兴,张海平
受保护的技术使用者:杭州电子科技大学信息工程学院
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!