文本识别数据集制作方法、计算机设备和计算机存储介质与流程
本公开的实施例涉及计算机,具体涉及文本识别数据集制作方法、计算机设备和计算机存储介质。
背景技术:
1、随着人工智能技术进入大规模工业化大生产阶段,文本检测、文本识别、文字转语音、语音转文字等各种人工智能相关应用开始飞入寻常百姓家。文本识别技术,其底层能力依赖于数据以及深度学习神经网络模型。设计好的神经网络模型,需要通过有监督学习的方式,使用大量的文本识别数据对其进行训练,不断迭代,最终才能得到一个可商用的文本识别算法。对于文本识别任务来说,想要在实际场景中取得不错的效果,需要事先针对该场景准备大量的图像数据,而这种文本识别的图像数据,目前是比较稀缺的,且其采集和制作所耗费的人力以及时间资源也比较大,不利于文本识别技术的应用和普及。
技术实现思路
1、本公开的内容部分用于以简要的形式介绍构思,这些构思将在后面的具体实施方式部分被详细描述。本公开的内容部分并不旨在标识要求保护的技术方案的关键特征或必要特征,也不旨在用于限制所要求的保护的技术方案的范围。
2、本公开的一些实施例提出了文本识别数据集制作方法、计算机设备和计算机可读存储介质,来解决以上背景技术部分提到的技术问题中的一项或多项。
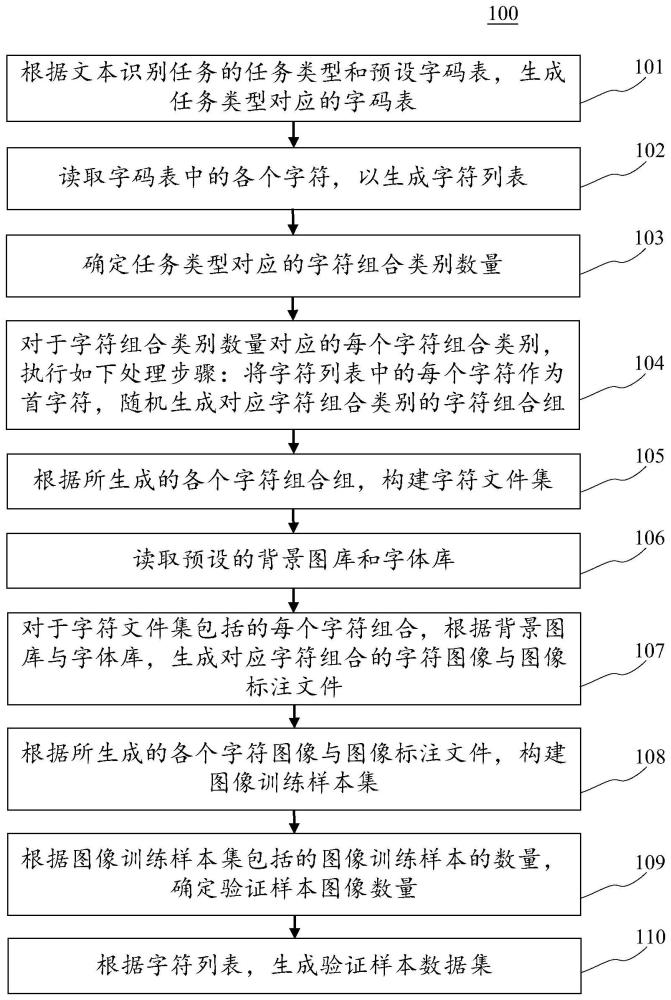
3、第一方面,本公开的一些实施例提供了一种文本识别数据集制作方法,该方法包括:根据文本识别任务的任务类型和预设字码表,生成上述任务类型对应的字码表,其中,上述字码表包含在对应上述任务类型中的各个字符,上述任务类型表征上述文本识别任务的应用场景;读取上述字码表中的各个字符,以生成字符列表;确定上述任务类型对应的字符组合类别数量;对于上述字符组合类别数量对应的每个字符组合类别,执行如下处理步骤:将上述字符列表中的每个字符作为首字符,随机生成对应上述字符组合类别的字符组合组;根据所生成的各个字符组合组,构建字符文件集,其中,上述字符文件集中的字符文件对应上述各个字符组合组中的字符组合组;读取预设的背景图库和字体库;对于上述字符文件集包括的每个字符组合,根据上述背景图库与上述字体库,生成对应上述字符组合的字符图像与图像标注文件;根据所生成的各个字符图像与图像标注文件,构建图像训练样本集;根据上述图像训练样本集包括的图像训练样本的数量,确定验证样本图像数量;根据上述字符列表,生成验证样本数据集,其中,上述验证样本数据集包括的验证样本的数量为上述验证样本图像数量。
4、第二方面,本公开还提供一种计算机设备,上述计算机设备包括处理器、存储器、以及存储在上述存储器上并可被上述处理器执行的计算机程序,其中上述计算机程序被上述处理器执行时,实现如上述第一方面任一实现方式所描述的方法。
5、第三方面,本公开还提供一种计算机可读存储介质,上述计算机可读存储介质上存储有计算机程序,其中上述计算机程序被处理器执行时,实现如上述第一方面任一实现方式所描述的方法。
6、本公开的上述各个实施例具有如下有益效果:通过本公开的一些实施例的文本识别数据集制作方法,解决了图像采集难和数据标注难的问题,极大地丰富了训练数据集,大大提升了模型训练的效率。首先,根据文本识别任务的任务类型和预设字码表,生成上述任务类型对应的字码表。其中,上述字码表包含在对应上述任务类型中的各个字符,上述任务类型表征上述文本识别任务的应用场景。由此,可以选择出对应文本识别任务的字码。其次,读取上述字码表中的各个字符,以生成字符列表。接着,确定上述任务类型对应的字符组合类别数量;对于上述字符组合类别数量对应的每个字符组合类别,执行如下处理步骤:将上述字符列表中的每个字符作为首字符,随机生成对应上述字符组合类别的字符组合组。由此,可以避免传统数据集制作方法存在的字符覆盖不全的问题。之后,根据上述字符组合组集,构建字符文件集。其中,上述字符文件集中的字符文件对应上述字符组合组集中的字符组合组。再之后,读取预设的背景图库和字体库。由此,便于构建样本图像。然后,对于上述字符文件集包括的每个字符组合,根据上述背景图库与上述字体库,生成对应上述字符组合的字符图像与图像标注文件。再然后,根据所生成的各个字符图像与图像标注文件,构建图像训练样本集。由此,可以构建出训练样本集。最后,根据上述图像训练样本集包括的图像训练样本的数量,确定验证样本图像数量;根据上述字符列表,生成验证样本数据集。其中,上述验证样本数据集包括的验证样本的数量为上述验证样本图像数量。由此,解决了图像采集难和数据标注难的问题,极大地丰富了训练数据集,大大提升了模型训练的效率。
技术特征:
1.一种文本识别数据集制作方法,包括:
2.根据权利要求1所述的方法,其中,所述根据所述背景图库与所述字体库,生成对应所述字符组合的字符图像与图像标注文件,包括:
3.根据权利要求1所述的方法,其中,所述根据文本识别任务的任务类型和预设字码表,生成所述任务类型对应的字码表,包括:
4.根据权利要求1所述的方法,其中,所述验证样本数据集包括的验证样本的数量为所述验证样本图像数量包括:
5.根据权利要求1所述的方法,其中,所述根据所述字符列表,生成验证样本数据集,包括:
6.一种计算机设备,其中,所述计算机设备包括处理器、存储器、以及存储在所述存储器上并可被所述处理器执行的计算机程序,其中所述计算机程序被所述处理器执行时,实现如权利要求1-4中任一所述的方法的步骤。
7.一种计算机可读存储介质,其中,所述计算机可读存储介质上存储有计算机程序,其中所述计算机程序被处理器执行时,实现如权利要求1-4中任一所述的方法的步骤。
技术总结
本公开的实施例公开了文本识别数据集制作方法、计算机设备和计算机存储介质。该方法的一具体实施方式包括:确定任务类型对应的字符组合类别数量;对于字符组合类别数量对应的每个字符组合类别,执行如下处理步骤:将字符列表中的每个字符作为首字符,随机生成对应字符组合类别的字符组合组;根据所生成的各个字符组合组,构建字符文件集;对于字符文件集中的每个字符文件,根据背景图库与字体库,生成对应字符组合的字符图像与图像标注文件;根据所生成的各个字符图像与图像标注文件,构建图像训练样本集;根据字符列表,生成验证样本数据集。该实施方式极大地丰富了训练数据集,大大提升了模型训练的效率。
技术研发人员:韦未来
受保护的技术使用者:北京朝歌数码科技股份有限公司
技术研发日:
技术公布日:2024/1/22
- 还没有人留言评论。精彩留言会获得点赞!