一种基于深度学习与合成数据的弱纹理物体位姿估计方法
本发明涉及计算机视觉和机械臂抓取领域中的物体6d位姿估计技术,特别涉及一种弱纹理物体位姿估计方法。
背景技术:
1、物体6d位姿估计能够帮助操作人员获取相机坐标系下物体刚体的3d平移信息和3d旋转信息,从而提高操作人员的操作精度以及效率。传统的物体位姿估计一般是基于特征点对应的方法和基于模板匹配的方法。这些方法在遮挡情况以及面对弱纹理物体时效果很差,难以应对当今复杂的工业环境。随着深度学习技术的发展,越来越多针对基于深度学习的6d位姿估计方法被提出。
2、中国专利申请号为202010619800.7的文献中提出了基于位姿估计和校正的单图像机器人无序目标抓取方法,但是这种方法需要大量的真实数据集,成本高,工作量大,制作困难。中国申请号为cn202110921177.5的文献中提出了一种弱纹理物体位姿估计方法和系统,利用点渲染分割网络植入实例分割方法,但是由于网络的限制,该位姿估计方法在实际任务中依赖于深度信息和真实图像,不具备一定的柔性。目前,虽然基于深度学习的方法优于传统方法,但是它们通常需要标注真实数据集,产生很大的数据集制作成本。针对弱纹理与合成数据的6d位姿估计方法难以在保持高精度的同时实现快速性。
技术实现思路
1、本发明的目的是解决目前工业场景下弱纹理物体的6d位姿估计精度低、速度慢以及数据集制作困难等问题。提出了一种基于深度学习与合成数据的弱纹理物体位姿估计方法,利用合成数据训练以解决数据获取困难的问题,通过算法融合在保持检测速度的同时提高检测精度。
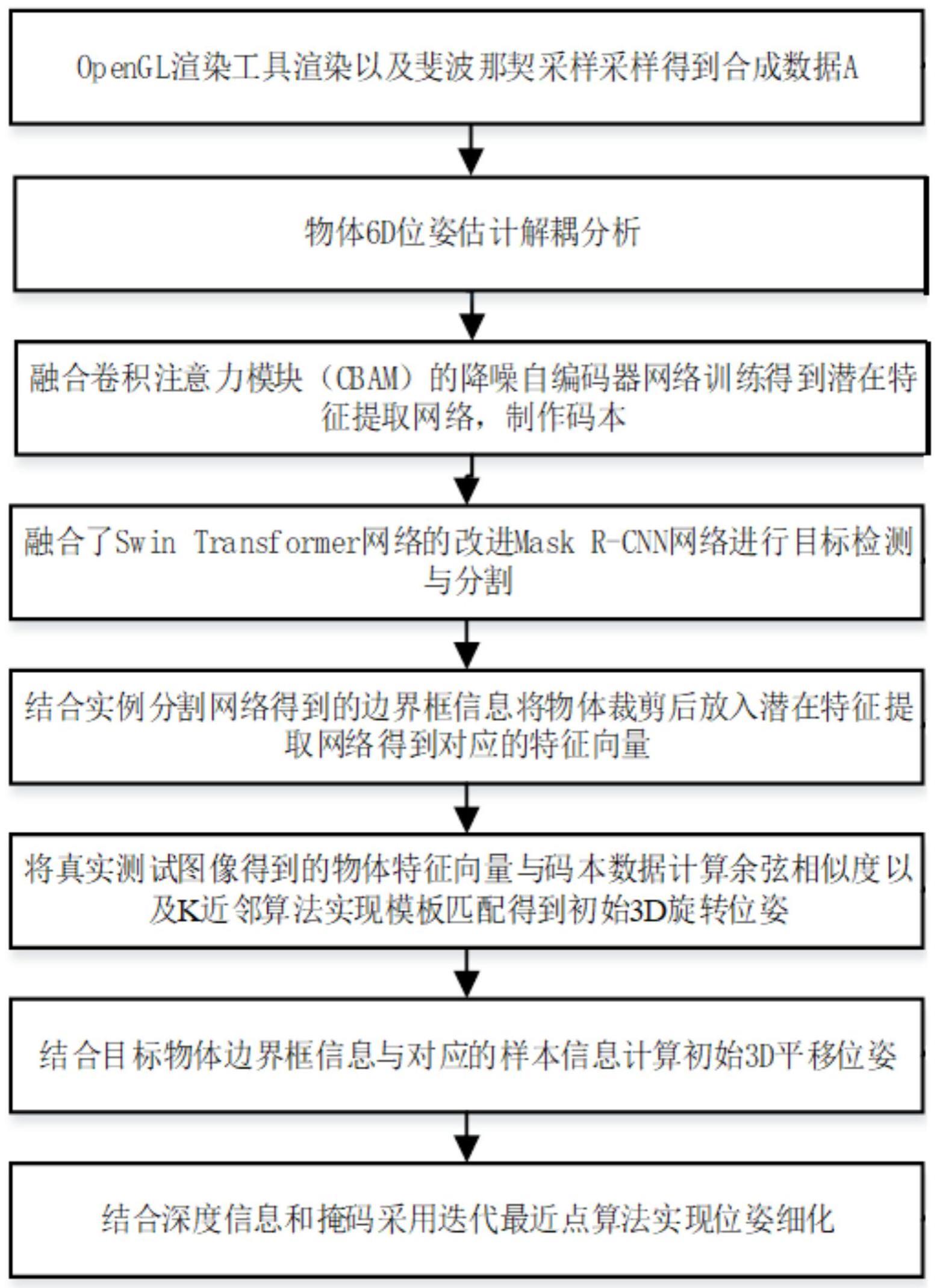
2、为实现上述目的,本发明一种基于深度学习与合成数据的弱纹理物体位姿估计方法采用的技术方案是:获取若干无纹理的物体的t-less数据集,得到每个物体的无纹理cad模型,还包括以下步骤:
3、步骤1):对无纹理cad模型进行渲染得到合成数据以及每个数据对应的边界框信息;
4、步骤2):对物体6d位姿解耦为一个旋转位姿和一个平移量的组合,所述的合成数据中的每个数据都对应于一个旋转位姿和平移量;
5、步骤3):所述的合成数据经过融合cbam模块的5层卷积层组成的自编码器网络,得到模板潜在向量zi,再经过5层反卷积层,完成一次完整的迭代,训练得到位姿潜在特征提取网络,将所述的合成数据输入该位姿潜在特征提取网络制作成码本,码本中的模板潜在向量zi与合成数据中每个数据对应的旋转位姿一一对应;
6、步骤4):将真实测试图像输入到融合swin transformer的改进的mask r-cnn实例分割网络,得到特征图,对特征图中的每一点设定预定的roi,roi经rpn过滤得到候选roi,对候选roi进行roialign,得到包围框信息;
7、步骤5)对步骤4)中所述的包围框信息进行裁剪,输入步骤3)中所述的位姿潜在特征提取网络,得到对应的潜在特征向量ztest;
8、步骤6):根据所述的潜在特征向量ztest与所述的模板潜在向量zi计算出余弦相似度,再采用k近邻算法寻找与物体图像姿态最接近的k个模板,这k个模板对应的姿态就是物体图像的3d旋转位姿;
9、步骤7):先根据真实测试图像中物体对应的合成数据中的cad模型数据的边界框信息以及步骤4)中所述的包围框信息得到z轴平移量的估计值,再采用图像坐标系与相机坐标系的转化关系式得到真实测试图像中物体在x轴和y轴上的平移量。
10、本发明采用上述技术方案后的优点如下:
11、(1)本发明设计了用于6d位姿估计任务的融合了cbam(卷积注意力模块)的降噪自编码器网络,其通过将cbam纳入现有的降噪自编码器算法而得到,该模块抑制了来自信道和空间两个维度的不相关特征,突出物体特征,抑制不相关特征,提高网络表达特征的能力。因此,降噪自编码器可以更好地提取潜在特征。
12、(2)本发明设计了用于6d位姿估计的实例分割网络,将swin transformer融入到改进的实例分割模型mask r-cnn中。针对传统mask r-cnn实例分割网络精度低、速度慢的特点,将主干网络替换为swin transformer网络结构,在减少网络参数量的同时提高了检测精度,由于swin transformer的滑动窗口操作,计算复杂度大大降低,从而降低了计算复杂度,使网络能够应对大尺寸的图像输入,同时保持低内存占用,模型参数量大大降低;而改进的mask r-cnn实例分割网络,是针对fpn传递给rpn的特征图信息缺乏底层信息,将传统fpn结构增加从下到上的向后连接的通道得到一种改进的fpn网络,提高本发明实例分割网络的精度。
13、(3)本发明为基于合成数据的弱纹理物体6d位姿估计,借由虚拟渲染、空间采样、域随机化技术实现本发明改进的降噪自编码器网络的训练,以此减少虚拟模型与真实模型之间的域差距,大大减少了6d位姿估计方法的实现成本,本发明将改进的算法融入到整个模型中,使得本发明能够在减少模型参数量的同时提高6d位姿估计识别精度。
技术特征:
1.一种基于深度学习与合成数据的弱纹理物体位姿估计方法,获取若干无纹理的物体的t-less数据集,得到每个物体的无纹理cad模型,其特征是包括以下步骤:
2.根据权利要求1所述的弱纹理物体位姿估计方法,其特征是:步骤7)中所述的z轴平移量的估计值为tj,z为所述的合成数据中物体的z轴平移量,fw和fj分别为真实相机的焦距和渲染相机的焦距,ww、hw分别是所述的包围框信息中边界框的宽度和高度,wj、hj分别是合成数据记录的每个数据对应的边界框信息中边界框的宽度和和高度。
3.根据权利要求2所述的弱纹理物体位姿估计方法,其特征是:当深度信息可用时,则真实测试图像中物体的z轴平移量为pw为真实测试图像中物体的点云记为pw,为真实测试图像中物体的点云的质心,为合成数据中对应数据点云的质心,tj,z为合成数据中物体的z轴平移量。
4.根据权利要求3所述的弱纹理物体位姿估计方法,其特征是:根据图像坐标系与相机坐标系的转化关系式重新计算真实测试图像中物体的x轴和y轴平移量,得到真实测试图像中物体的3d平移位姿。
5.根据权利要求4所述的弱纹理物体位姿估计方法,其特征是:对初始点云信息进行预处理,再采用icp算法进行迭代优化初始位姿估计,得到3d旋转位姿和平移量。
6.根据权利要求1-5任一所述的弱纹理物体位姿估计方法,其特征是:步骤1)中,采用opengl载入.obj格式的cad模型点云数据,渲染得到纯背景下数据,将白色区域与纯黑背景进行区域叠加,再经过斐波那契网格采样得到所述的合成数据。
7.根据权利要求1-5任一所述的弱纹理物体位姿估计方法,其特征是:步骤3)中,对所述的合成数据进行域随机化训练,再输入所述的自编码器网络,所述的自编码器网络将卷积降噪自编码器中编码器前三层分别融入cbam。
8.根据权利要求1-5任一所述的弱纹理物体位姿估计方法,其特征是:步骤4)中,所述的改进的mask r-cnn实例分割网络由4层复合结构和改进的fpn结构组成,所述的改进的fpn包含有当前层、上层以及从下到上并向后连接的通道,合并低级特征图和高级特征图生成新的特征图。
9.根据权利要求8所述的弱纹理物体位姿估计方法,其特征是:所述的新的特征图pi(i=2,3,4,5,6)是fpn结构的特征金字塔的特征,低级特征图为mi,高级特征图为pi+1,表示步长stride为2、卷积核尺寸size为3×3的卷积;表示步长为1、卷积核尺寸为3×3的卷积。
10.根据权利要求1所述的弱纹理物体位姿估计方法,其特征是:步骤6)中,所述的余弦相似度
技术总结
本发明公开一种基于深度学习与合成数据的弱纹理物体位姿估计方法,对无纹理CAD模型进行渲染得到合成数据,经过融合CBAM模块的5层卷积层组成的自编码器网络得到位姿潜在特征提取网络,制作成码本,将真实测试图像输入到改进的Mask R‑CNN实例分割网络得到包围框信息;对包围框信息进行裁剪,输入位姿潜在特征提取网络得到潜在特征向量;根据潜在特征向量与模板潜在向量计算出余弦相似度,采用k近邻算法得到3D旋转位姿;根据真实测试图像中CAD模型数据的边界框信息得到z轴平移量估计值,采用图像坐标系与相机坐标系的转化关系式得到x轴和y轴上的平移量;提高了网络表达特征的能力,降低计算复杂度,在减少模型参数量的同时提高6D位姿估计识别精度。
技术研发人员:郑天宇,张胜文,舒瑞,张春燕,程德俊
受保护的技术使用者:江苏科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!