基于GPU直接存储器访问的显示加速方法、装置及介质与流程
本发明实施例涉及窗口图形系统,尤其涉及一种基于gpu直接存储器访问的显示加速方法、装置及介质。
背景技术:
1、窗口系统作为操作系统中图形显示的主要服务,负责将各个图形应用程序的窗口渲染数据显示到最终的显示器上,每个图形应用程序作为客户端,与窗口系统交互、配合以生成渲染结果。linux系统中有很多窗口系统的实现,如x window system、wayland、android surfaceflinger等,目前主流的窗口系统协议是用于x window system的x11和用于wayland窗口系统的wayland,两者的差别在于:基于wayland协议的架构中省去了x11中xserver作为中间传递的过程,直接由合成器,即compositor去负责显示,因此,无论是x11还是wayland,均需要经过compositor将每个客户端的窗口进行合成,当混合完成之后,最终当前帧要显示的内容即图片,已经放置在了一块显存的存储空间中了,此时只需要将已存储到所述显存的存储空间中的各客户端的渲染结果经过混合后的合成结果数据搬运到显示处理器要读取的帧缓冲中即可,通常的做法是x server或者wayland会发起一次显存拷贝,将混合后的内容,拷贝到帧缓冲,即framebuffer,同步等待拷贝完成。以wayland为例,目前所述显存拷贝通常是由合成器在cpu侧完成,由于显存拷贝和渲染同步完成,将会阻塞下一帧的渲染并且同时占用cpu的资源,因此,上述技术方案在进行图形绘制的过程中,无法发挥gpu并行处理数据的优势,导致窗口系统的性能低下。
技术实现思路
1、有鉴于此,本发明实施例期望提供一种基于gpu直接存储器访问的显示加速方法、装置及介质,能够提升系统整体的显示帧率,从而提高gpu系统的吞吐量并减少cpu的消耗。
2、本发明实施例的技术方案是这样实现的:
3、第一方面,本发明实施例提供一种基于gpu直接存储器访问的显示加速方法,包括:
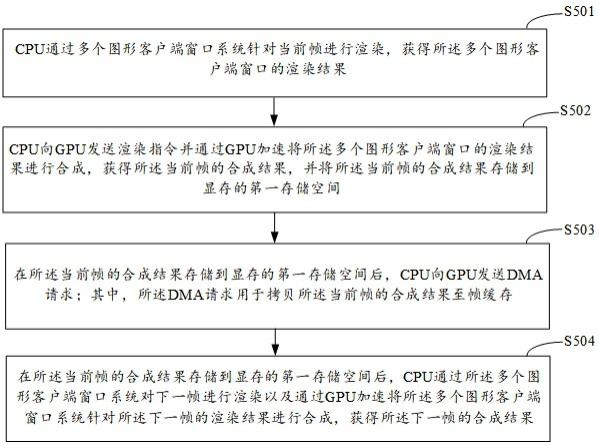
4、cpu通过多个图形客户端窗口系统针对当前帧进行渲染,获得所述多个图形客户端窗口的渲染结果;
5、cpu向gpu发送渲染指令并通过gpu加速将所述多个图形客户端窗口的渲染结果进行合成,获得所述当前帧的合成结果,并将所述当前帧的合成结果存储到显存的第一存储空间;
6、在所述当前帧的合成结果存储到显存的第一存储空间后,cpu向gpu发送dma请求;其中,所述dma请求用于拷贝所述当前帧的合成结果至帧缓存;
7、在所述当前帧的合成结果存储到显存的第一存储空间后,cpu通过所述多个图形客户端窗口系统对下一帧进行渲染以及通过gpu加速将所述多个图形客户端窗口系统针对所述下一帧的渲染结果进行合成,获得所述下一帧的合成结果。
8、第二方面,本发明实施例提供一种基于gpu直接存储器访问的显示加速装置,所述加速装置包括:渲染部分、合成部分、拷贝部分以及获得部分;其中,
9、所述渲染部分,经配置为cpu通过多个图形客户端窗口系统针对当前帧进行渲染,获得所述多个图形客户端窗口的渲染结果;
10、所述合成部分,经配置为cpu向gpu发送渲染指令并通过gpu加速将所述多个图形客户端窗口的渲染结果进行合成,获得所述当前帧的合成结果,并将所述当前帧的合成结果存储到显存的第一存储空间;
11、所述拷贝部分,经配置为在所述当前帧的合成结果存储到显存的第一存储空间后,cpu向gpu发送dma请求;其中,所述dma请求用于拷贝所述当前帧的合成结果至帧缓存;
12、所述获得部分,经配置为在所述当前帧的合成结果存储到显存的第一存储空间后,cpu通过所述多个图形客户端窗口系统对下一帧进行渲染以及通过gpu加速将所述多个图形客户端窗口系统针对所述下一帧的渲染结果进行合成,获得所述下一帧的合成结果。
13、第三方面,本发明实施例提供一种计算设备,所述计算设备包括:通信接口,存储器和处理器;各个组件通过总线系统耦合在一起;其中,
14、所述通信接口,用于在与其他外部网元之间进行收发信息过程中,信号的接收和发送;
15、所述存储器,用于存储能够在所述处理器上运行的计算机程序;
16、所述处理器,用于在运行所述计算机程序时,执行第一方面所述基于gpu直接存储器访问的显示加速方法的步骤。
17、第四方面,本发明实施例提供一种计算机存储介质,所述计算机存储介质存储有基于gpu直接存储器访问的显示加速程序,所述基于gpu直接存储器访问的显示加速程序被至少一个处理器执行时实现第一方面所述基于gpu直接存储器访问的显示加速方法的步骤。
18、本发明实施例提供了一种基于gpu直接存储器访问的显示加速方法、装置及介质,通过cpu向gpu发送渲染指令并通过gpu加速将各图形客户端窗口系统的渲染结果执行合成以获取到当前帧的合成结果并存储到显存的第一存储空间,在所述当前帧的合成结果存储到显存的第一存储空间后,所述cpu侧的合成器向gpu发起dma请求以拷贝所述当前帧的合成结果至帧缓存,同时cpu通过所述多个图形客户端窗口系统对下一帧进行渲染以及通过gpu加速将所述多个图形客户端窗口系统针对所述下一帧的渲染结果进行合成,获得所述下一帧的合成结果,由于所述当前帧的合成结果的拷贝是在gpu侧完成的,因此,不需要占用cpu的资源,减少了对cpu的消耗。通过该技术方案实现了渲染流程和拷贝流程的并行执行,提升了系统整体的显示帧率,从而提高了gpu的吞吐量。
技术特征:
1.一种基于gpu直接存储器访问的显示加速方法,其特征在于,该方法应用于具有cpu和gpu的计算设备,包括:
2.根据权利要求1所述方法,其特征在于,所述cpu通过多个图形客户端窗口系统针对当前帧进行渲染,获得所述多个图形客户端窗口的渲染结果,包括:
3.根据权利要求1所述方法,其特征在于,所述cpu向gpu发送渲染指令并通过gpu加速将所述多个图形客户端窗口的渲染结果进行合成,获得所述当前帧的合成结果,并将所述当前帧的合成结果存储到显存的第一存储空间,包括:
4.根据权利要求3所述方法,其特征在于,所述通过gpu加速将所述显存的第二存储空间中的所述当前帧的渲染结果进行合成以生成当前帧的合成结果并存储到显存的第一存储空间,包括:
5.根据权利要求1所述方法,其特征在于,所述在所述当前帧的合成结果存储到显存的第一存储空间后,cpu向gpu发送dma请求;其中,所述dma请求用于拷贝所述当前帧的合成结果至帧缓存,包括:
6.根据权利要求5所述方法,其特征在于,所述根据所述dma请求,通过dma执行单元从显存的第一存储空间中读取所述当前帧的合成结果并存储到dma通道中,包括:
7.根据权利要求5所述方法,其特征在于,所述将所述当前帧的合成结果通过所述dma通道拷贝至帧缓存,包括:
8.一种基于gpu直接存储器访问的显示加速装置,其特征在于,所述加速装置包括:渲染部分、合成部分、拷贝部分以及获得部分;其中,
9.一种计算设备,其特征在于,所述计算设备包括:通信接口,处理器,存储器;各个组件通过总线系统耦合在一起;其中,
10.一种计算机存储介质,其特征在于,所述计算机存储介质存储有基于gpu直接存储器访问的显示加速的程序,所述基于gpu直接存储器访问的显示加速的程序被至少一个处理器执行时实现权利要求1至7任一项所述基于gpu直接存储器访问的显示加速方法的步骤。
技术总结
本发明实施例公开了一种基于GPU直接存储器访问的显示加速方法、装置及介质,该方法包括:CPU通过多个图形客户端窗口系统针对当前帧进行渲染,获得所述多个图形客户端窗口的渲染结果;CPU向GPU发送渲染指令并通过GPU加速将所述多个图形客户端窗口的渲染结果进行合成,获得合成结果,并存储到显存的第一存储空间;在存储到显存的第一存储空间后,CPU向GPU发送DMA请求;在存储到显存的第一存储空间后,CPU通过所述多个图形客户端窗口系统对下一帧进行渲染以及通过GPU加速将针对所述下一帧的渲染结果进行合成,获得所述下一帧的合成结果。通过该技术方案能够提高GPU系统的吞吐量并减少CPU的消耗。
技术研发人员:李通
受保护的技术使用者:西安芯云半导体技术有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!