一种支持海量公式并行计算的方法与流程
本发明涉及计算机,尤其涉及一种支持海量公式并行计算的方法。
背景技术:
1、企业税务申报表的数值计算涉及复杂的业务知识,需要通过公式引擎赋予业务人员自主配置公式来进行税务申报的数值计算。公式引擎支持定义变量和常量、使用自然语言描述计算步骤、引用其他公式等功能;公式引擎为业务人员提供了一个高度灵活且易用的平台,能够更高效地处理业务数据并迅速做出准确的决策。
2、公式引擎通过将常见的计算步骤封装为一个公式并在其他公式中重复使用,实现业务人员在一个公式中引用其他公式的功能;但现有技术中这种在一个公式中引用其他公式的方法存在以下弊端:
3、1、一张企业税务申报表往往需要执行上万次公式,公式之间存在复杂的依赖关系时,难以确认公式正确的执行顺序;
4、2、无法充分利用计算机的并行计算能力实现海量公式并行计算,效率低下;
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺点,而提出的一种支持海量公式并行计算的方法。
2、为实现上述目的,本发明采用了如下技术方案:
3、一种支持海量公式并行计算的方法,包括以下步骤:
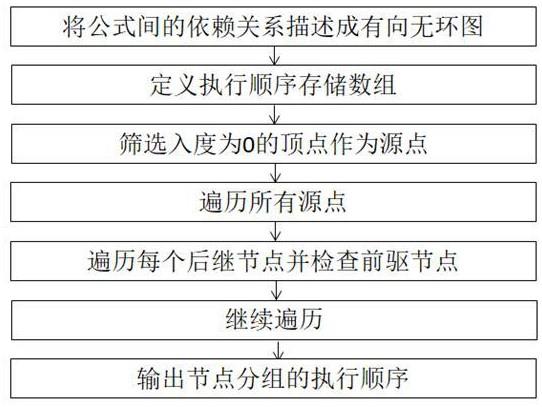
4、s1:将公式间的依赖关系描述成有向无环图;
5、企业进行税务申报表数值计算时,将涉及到的存在依赖关系的公式描述为有向无环图;
6、所述有向无环图包括节点和有向边,有向无环图的各个节点对应涉及到的各个公式,有向无环图的有向边从被依赖节点指向依赖节点;
7、进一步的,一条有向边中,被依赖节点为依赖节点的前驱节点,依赖节点为被依赖节点的后继节点;
8、进一步的,每个节点所对应的后继节点和前驱节点不唯一;
9、进一步的,检查各个节点和有向边的指向关系,确保不会形成环路;
10、s2:定义执行顺序存储数组;
11、定义一个执行顺序存储数组readynodes;
12、所述执行顺序存储数组readynodes中的元素类型同样为数组,即执行顺序存储数组readynodes由一系列内部数组组成;
13、进一步的,定义一个哈希表类型的变量checknodes,将遍历过的节点对应的公式存储到变量checknodes中;
14、s3:筛选入度为0的节点作为源点;
15、遍历有向无环图中所有的节点,获取各个节点的入边数,筛选出所有入边数为0的节点即入度为0的节点作为源点;
16、s4:遍历所有源点;
17、通过广度优先搜索bfs对步骤s3中筛选出的所有源点进行遍历;
18、遍历完成后,将所有源点对应的公式保存到一个初始分组中,将这个初始分组添加到执行顺序存储数组readynodes中,作为执行顺序存储数组readynodes的第一个内部数组;
19、同时将初始分组中包含的公式保存到变量checknodes中;
20、s5:遍历每个后继节点并检查前驱节点;
21、所有源点遍历完成后,对所有源点对应的后继节点进行逐个遍历;
22、具体的遍历方法包括如下子步骤:
23、s51:创建当前分组;
24、s52: 依次遍历所有源点对应的后继节点并进行判断;
25、具体的判断方法如下:
26、s521:检查当前遍历节点的所有前驱节点,判断当前遍历节点的所有前驱节点是否都已存在于checknodes中,如果是,则表示当前遍历节点的所有前驱节点是否都已存在执行顺序存储数组readynodes的分组中且已经都执行过;如果不是,则继续遍历其他节点;
27、s522:判断当前遍历节点本身是否存在于checknodes中,如果不在,则将当前遍历节点对应的公式添加到创建的当前分组中;如果在,则继续遍历其他节点;
28、s523:保存当前遍历状态;
29、依次遍历,直至所有源点的后继节点全都遍历完成;
30、s53:所有源点对应的后继节点遍历完成;
31、将当前分组保存到执行顺序存储数组readynodes中,为初始分组的后的第二个内部分组;
32、同时将第二个内部分组中包含的公式同步添加到checknodes中;
33、s6:继续遍历;
34、检查有向无环图中是否存在还未分组的节点,如果不存在,则遍历完成;
35、如果存在,则创建新的当前分组,并对执行顺序存储数组readynodes的第二个内部分组中所包含节点的后续节点进行遍历;
36、具体的遍历方法为步骤s5中提供遍历方法;
37、直至有向无环图中所有节点遍历完成;
38、s7:输出节点分组的执行顺序;
39、所述各个内部分组在执行顺序存储数组readynodes中的顺序为分组的执行顺序;
40、进一步的,每个内部分组中节点对应的公式可以并行执行;
41、与现有技术相比,本发明的有益效果为:
42、本发明所提供的支持海量公式并行计算的方法通过将公式之间的依赖关系描述为有向无环图的形式,通过广度优先搜索bfs对有向无环图中的节点对应的公式进行分组,从而确认公式的执行顺序,高效解决了公式之间存在复杂的依赖关系时,难以确认公式正确的执行顺序的问题;
43、本发明提供的方法利用广度优先搜索bfs对有向无环图中的公式进行分组和并行计算,充分利用了现在计算机的并行处理能力,避免了传统拓扑排序算法中的多次递归和重复计算的问题,能够高效地解决公式间存在复杂依赖关系或存在大规模公式的情况;
44、本方法通过检查前驱节点是否都存在于之前的分组中确保了数据的正确性和一致性,避免了并发执行导致的数据冲突和错误,提高了计算的准确性。
技术特征:
1.一种支持海量公式并行计算的方法,其特征在于:包括以下步骤
2.如权利要求1所述的一种支持海量公式并行计算的方法,其特征在于:
3.如权利要求2所述的一种支持海量公式并行计算的方法,其特征在于:
4.如权利要求1所述的一种支持海量公式并行计算的方法,其特征在于:每个节点所对应的后继节点和前驱节点不唯一。
5.如权利要求1所述的一种支持海量公式并行计算的方法,其特征在于:
6.如权利要求1所述的一种支持海量公式并行计算的方法,其特征在于:
技术总结
本发明提供一种支持海量公式并行计算的方法,包括以下步骤:S1:将公式间的依赖关系描述成有向无环图;S2:定义执行顺序存储数组;S3:筛选入度为0的顶点作为源点;S4:遍历所有源点;S5:遍历每个后继节点并检查前驱节点;S6:继续遍历;S7:输出节点分组的执行顺序;本发明所提供的支持海量公式并行计算的方法通过将公式之间的依赖关系描述为有向无环图的形式,通过广度优先搜索BFS对有向无环图中的节点对应的公式进行分组,从而确认公式的执行顺序,高效解决了公式之间存在复杂的依赖关系时,难以确认公式正确的执行顺序的问题。
技术研发人员:慕传伟
受保护的技术使用者:云帐房网络科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!