一种基于深度学习的政策匹配方法与流程
本发明涉及数据处理,尤其是涉及一种基于深度学习的政策匹配方法。
背景技术:
1、政府部门经常通过多种渠道发布多种企业相关的政策文件,但企业经常因为信息了解的不及时或对相应政策文件理解的不准确而错过了相应政策,导致企业利益受到损失,企业为了减少这方便的损失常见的做法是雇用相应的人员或相应的咨询公司帮助企业即时了解与分析相应政策,这增加企业的负担。
技术实现思路
1、本发明提供了一种基于深度学习的政策匹配方法,以解决现有技术中企业无法及时了解政策文件,无法及时准确匹配政策条件的技术问题。
2、本发明的一个方面在于提供一种基于深度学习的政策匹配方法,所述政策匹配方法包括如下方法步骤:
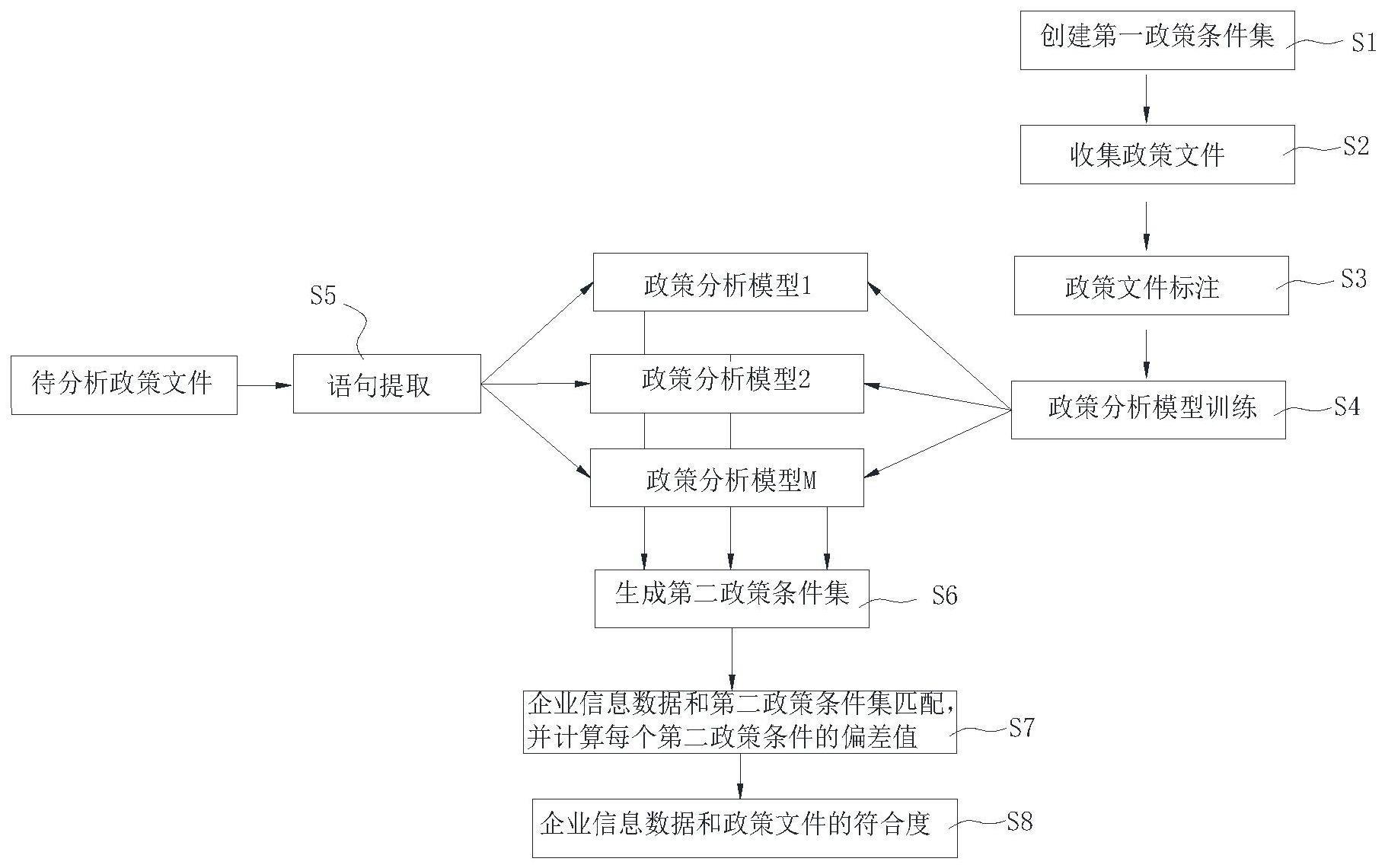
3、s1、创建第一政策条件集,其中,第一政策条件集中包括多个第一政策条件;
4、s2、收集不同行业、不同政府部门的政策文件n份,并对收集的n份政策文件进行语句提取,获取每一份政策文件的多个语句;
5、s3、利用第一政策条件集,对n份政策文件进行多分类标注,以及对每一份政策文件的多个语句进行命名实体标注,以及对每一份政策文件的多个语句进行序列到序列标注;
6、s4、利用标注好的n份政策文件,以及每一份政策文件命名实体标注的多个语句,以及每一份政策文件序列到序列标注的多个语句,训练m个政策分析模型;
7、s5、对待分析的政策文件进行语句提取,获取待分析文件的多个语句,将待分析文件,以及待分析文件的多个语句输入m个政策分析模型,输出待分析文件,以及待分析文件的多个语句对应的第二政策条件;
8、s6、将m个政策分析模型输出的待分析文件,以及待分析文件的多个语句对应的第二政策条件,合并成第二政策条件集,并对第二政策条件集进行数据标准化处理;
9、s7、获取企业信息数据和第二政策条件集,将企业信息数据和第二政策条件集匹配,并计算每个第二政策条件的偏差值;
10、s8、对每个第二政策条件的偏差值进行截取,利用截取后的每个第二政策条件的偏差值,计算企业信息数据与政策文件的符合度,并显示企业信息数据与政策文件的符合度。
11、在一个优选的实施例中,在步骤s2中,对收集的n份政策文件进行语句提取包括:
12、s201、去除每一份政策文件中不可见的字符、空格、空行、emoji等字符;
13、s202、每一份政策文件中无句号分隔的段落、章节内容之间添加句号;
14、s203、对每一份政策文件的内容按顺序合并为单行内容;
15、s204、对单行内容切分为多个语句。
16、在一个优选的实施例中,在步骤s4中,利用标注好的n份政策文件,通过transformer-xl类的长文本编码模型,训练政策分析模型。
17、在一个优选的实施例中,在步骤s4中,利用每一份政策文件命名实体标注的多个语句,通过bert+bilstm+crf类的模型,训练政策分析模型;
18、在一个优选的实施例中,在步骤s4中,利用每一份政策文件序列到序列标注的多个语句,通过seq2seq类的序列到序列的翻译模型,训练政策分析模型。
19、在一个优选的实施例中,在步骤s5中,对待分析的政策文件进行语句提取包括:
20、s501、去除待分析的政策文件中不可见的字符、空格、空行、emoji等字符;
21、s502、待分析的政策文件中无句号分隔的段落、章节内容之间添加句号;
22、s503、对待分析的政策文件的内容按顺序合并为单行内容;
23、s504、对单行内容切分为多个待分析文件的语句。
24、在一个优选的实施例中,在步骤s7中,每个第二政策条件的偏差值通过如下方法计算:
25、对于数值类第二政策条件,其条件偏差=(vkey-vtarget)/vtarget;
26、对于文本类第二政策条件,
27、其中,veckey和vectarget表示经过bert类的模型计算后的第二政策条件,与企业信息数据的语义向量。
28、在一个优选的实施例中,在步骤s8中,每个第二政策条件的偏差值的截取规则为:
29、当第二政策条件的偏差值大于0,则第二政策条件的偏差值取0;
30、当第二政策条件的偏差值小于-1,则第二政策条件的偏差值取-1;
31、当第二政策条件的偏差值范围在[-1,0],则第二政策条件的偏差值不进行截取。
32、在一个优选的实施例中,在步骤s8中,企业信息数据与政策文件的符合度通过如下方法计算:
33、
34、其中,s表示对第二政策条件集中第二政策条件的数量;ri表示截取后的第二政策条件偏差值,wi表示每个第二政策条件的权重。
35、在一个优选的实施例中,企业信息数据与政策文件的符合度取值范围在[0,100],当企业信息数据与政策文件的符合度=100时,则企业信息数据与政策文件完全符合。
36、与现有技术相比,本发明具有以下有益效果:
37、本发明提供的一种基于深度学习的政策匹配方法,通过深度学习模型分析政策文件,计算信息数据与政策文件的符合程度,用于主动提醒或自动办理相关业务等场景,让相关企业即时享受到相应政策,帮助企业减少损失、减轻负担,帮助政务服务需求侧改革落地,提升政务主动服务的能力。
技术特征:
1.一种基于深度学习的政策匹配方法,其特征在于,所述政策匹配方法包括如下方法步骤;
2.根据权利要求1所述的政策匹配方法,其特征在于,在步骤s2中,对收集的n份政策文件进行语句提取包括:
3.根据权利要求1所述的政策匹配方法,其特征在于,在步骤s4中,利用标注好的n份政策文件,通过transformer-xl类的长文本编码模型,训练政策分析模型。
4.根据权利要求1所述的政策匹配方法,其特征在于,在步骤s4中,利用每一份政策文件命名实体标注的多个语句,通过bert+bilstm+crf类的模型,训练政策分析模型。
5.根据权利要求1所述的政策匹配方法,其特征在于,在步骤s4中,利用每一份政策文件序列到序列标注的多个语句,通过seq2seq类的序列到序列的翻译模型,训练政策分析模型。
6.根据权利要求1所述的政策匹配方法,其特征在于,在步骤s5中,对待分析的政策文件进行语句提取包括:
7.根据权利要求1所述的政策匹配方法,其特征在于,在步骤s7中,每个第二政策条件的偏差值通过如下方法计算:
8.根据权利要求1所述的政策匹配方法,其特征在于,在步骤s8中,每个第二政策条件的偏差值的截取规则为:
9.根据权利要求1所述的政策匹配方法,其特征在于,在步骤s8中,企业信息数据与政策文件的符合度通过如下方法计算:
10.根据权利要求9所述的政策匹配方法,其特征在于,企业信息数据与政策文件的符合度取值范围在[0,100],当企业信息数据与政策文件的符合度=100时,则企业信息数据与政策文件完全符合。
技术总结
本发明提供了一种基于深度学习的政策匹配方法,包括:S1、创建第一政策条件集;S2、收集政策文件N份,获取每一份政策文件的多个语句;S3、利用第一政策条件集,对N份政策文件进行标注;S4、训练M个政策分析模型;S5、获取待分析文件的多个语句,输入M个政策分析模型,输出第二政策条件;S6、生成第二政策条件集;S7、获取企业信息数据和第二政策条件集,计算每个第二政策条件的偏差值;S8、对每个第二政策条件的偏差值进行截取,利用截取后的每个第二政策条件的偏差值,计算企业信息数据与政策文件的符合度。本发明通过深度学习模型分析政策文件,计算信息数据与政策文件的符合程度,让相关企业即时享受到相应政策。
技术研发人员:郭大勇,兰永
受保护的技术使用者:上海通办信息服务有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!