一种基于Copula和MIC的特征选择技术
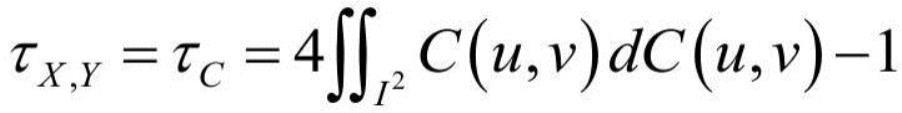
本发明涉及模式识别和数据挖掘中的一个重要数据处理步骤,具体讲是一种基于copula和mic的特征选择技术,简称fscme。
背景技术:
1、特征选择是模式识别和数据挖掘中的一个重要的数据处理步骤。其本质含义指在不明显损失数据集潜在信息的基础上从原始特征集合中选出部分特征构成新的特征子集,以此来降低数据集的特征维度,规避维度灾难,提高分类的时间效率。特征选择可以缩减训练时间并产生具有可解释性的模型。同时,特征选择技术能给学习算法带来许多的益处,减少了计算代价和对数据的存储要求,提高了分类的速度和准确率,使对数据的可视化和理解更容易。
2、根据评估策略,现有的特征选择方法可被分为两类:独立于分类器的方法和依赖于分类器的方法,其中,前者主要指过滤式方法,后者则包含封装式和嵌入式两类方法。过滤式特征选择算法的核心在于设定过滤准则,即通过某种标准对特征(子集)进行度量,选择合理的特征子集。在监督学习中,过滤式方法按其与类标签的相关性排列特征。大多数相关分数可以用一般方法计算,如f-score,relief和relief-f等。这些方法在去除不相关特征方面是有效的,但在去除冗余特征方面是无效的。另一方面,这些方法依赖于原始数据集的实际值并且对数据集的噪声较敏感。
3、battiti r提出了基于互信息的特征选择算法(mifs)。该算法采用了序列前向搜索的搜索方式,每次搜索过程采用贪婪策略,选择使得过滤式准则取最大值的特征,直到选择的特征数目达到预设数目为止。该过滤式准则的核心思路是最大化特征与标签之间的互信息的同时最小化特征与特征之间的互信息。mifs算法的框架是过滤式特征选择的通用框架,后续所介绍的算法均是基于该框架,不同的只是过滤式准则。peng h,long f,ding c等人提出了一种没有用户自定义参数的“最小冗余最大相关”算法(即经典的mrar算法)。fleuret f基于条件互信息提出了一种快速特征选择技术(cmim)。通过选择与类互信息最大的特征来预测已选择的任何特征的条件,保证了所选择的特征既具有个体信息又具有二乘二弱依赖性。meyer pe等人基于一种新的信息论选择准则:双输入对称相关,提出了一种新颖的过滤式方法,用于输入变量非常多的分类任务的有效特征选择方法(disr)。bennasar m等人基于联合互信息提出了一种非线性特征选择方法(jmim)。通过最大化联合互信息和“最大最小”准则,在一定程度上减轻了特征显著性高估的问题。snehalika lall等人引入了copula理论和互信息相结合,提出了一种基于copula的特征选择方法(cbfs),进而提出了一种基于copula和kendall’s 相关系数的正则化特征选择方法(rgcop)。期间,人们也提出了多种基于互信息理论的过滤式特征选择算法。
4、然而,上述方法往往只局限于使用一种度量标准,虽然这些方法的度量标准可以较好地度量变量之间的相关性,但是在实际应用中也存在一定的局限性。比如对于给定的数据集,按照互信息的定义无法真正意义上计算得到连续变量的信息熵,因此人们会将数据离散化,或采用其他方法进行估算,在一定程度上引进误差。
技术实现思路
1、为了规避采取单一互信息标准的局限性,本发明提供了一种基于copula和mic的特征选择技术,简称fscme。
2、本发明所采用的技术方法是:对特征选择中过滤策略和目标函数进行设计。在使用copula与kendall’s 关联关系(ccor)来计算候选特征与已选特征之间的相关性的基础上,同时使用了最大互信息系数(mic)来衡量特征与标签之间的相关性,对特征进行更好地筛选。熵权法保证了两个关联测度的重要性的同时避免了人为因素带来的偏差。同时,使得特征选择过程在共同衡量特征和标签之间的相关性以及特征和特征之间的冗余度的情况下,更加客观地得到特征子集,使分类性能有了较为明显的提升、在后续聚类性能的提升上也表现良好。
技术特征:
1.一种基于copula和mic的特征选择技术,其特征在于:
2.根据权利要求1所述的基于copula和mic的特征选择技术,具体算法实施步骤如下:
技术总结
特征选择是数据挖掘过程中的一个重要组成部分,也是近年来数据挖掘领域的研究热点。现有的基于信息熵的特征选择技术往往会引入较为复杂的互信息形式来度量特征,这可能会导致更多的冗余信息的引入和误差。为了避免更为复杂的互信息形式,本发明提出了一种融合Copula与Kendall’s关联关系(Ccor)和最大互信息系数(MIC)的特征选择技术(FSCME)。FSCME使用Ccor来衡量特征和特征之间的冗余度以及特征和标签之间的相关性。同时,为了增大特征和标签相关性的可信度,增加使用了MIC来共同衡量特征和标签之间的相关性。此外,FSCME特征选择技术还使用了客观赋权方法——熵权法对两个关联测度进行评价、赋权。结果表明,FSCME为后续聚类过程提供了更好的特征子集,同时,与其他先进技术相比,经过FSCME选择出的特征子集令分类性能有了优秀提升。
技术研发人员:尚军亮,钟琦,任倩倩,李凤,刘金星
受保护的技术使用者:曲阜师范大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!