基于双分支视频的非受控条件下人脸面部表情预测方法
本发明属于人脸面部表情预测领域,特别是涉及一种基于双分支视频的非受控条件下人脸面部表情预测方法。
背景技术:
1、面部表情是人类表达情感和进行社交活动的重要方式,也是实现人机交互的重要途径之一。2006年,hinton等提出深度信念网络(deep belief networks,dbns),使得深度学习和基于深度学习的面部表情识别重新引起重视。深度学习在表情识别中的应用,大多基于vggnet、googlenet与resnet网络模型,其核心结构均为深度卷积神经网络(deepconvolution neural networks,dcnn),如今正呈现蓬勃发展的态势。然而,目前传统的特征提取和分类方法一般都是通过标准人脸表情数据集来验证识别率,对于复杂环境与多变环境考虑不足,削弱了表情识别系统的适用性。
2、受控条件下的人脸面部表情识别所依赖的一个基本假设是:采集者模仿标准的表情图片,做出相对应的表情,最后人工筛选出合格样本的过程,因此受控条件下采集的数据样本噪声比例相对比较低。然而,真实场景中有很多干扰因素,包括身份、姿势、光照、性别、种族、年龄等常见的干扰因素和潜在的干扰因素(如发型、配饰、遮挡等)。因此非受控条件下进行面部表情识别表情仍然是非常具有挑战性的。
技术实现思路
1、本发明的目的是提供一种基于双分支视频的非受控条件下人脸面部表情预测方法,以解决上述现有技术存在的问题。
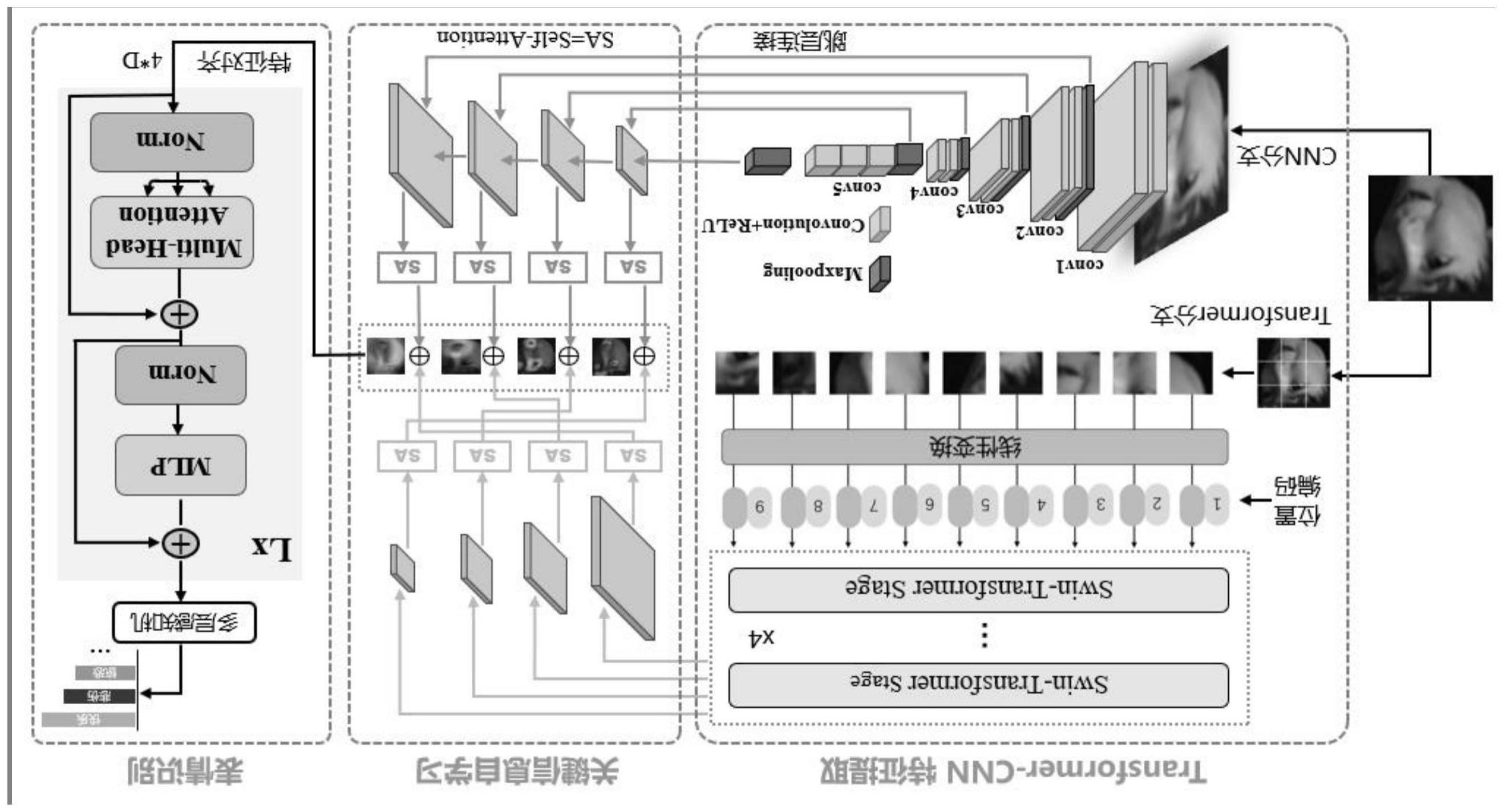
2、为实现上述目的,本发明提供了一种基于双分支视频的非受控条件下人脸面部表情预测方法,包括:
3、获取初始视频数据,将所述初始视频数据进行处理,获得视频片段;
4、构建双分支网络结构,将所述视频片段通过双分支网络结构中进行处理,获得多尺度深度特征图;
5、基于注意力机制,将所述多尺度深度特征图进行层级式特征融合,获得全局和局部信息;
6、基于所述全局和局部信息对初始视频片段样本的面部表情融合特征进行分类,完成非受控条件下面部表情分类。
7、优选的,所述获得视频片段的过程包括:
8、将所述初始视频数据进行长度统一处理,获得长度统一数据;
9、将所述长度统一数据进行内插和裁剪操作,获得每个帧的人脸区域;
10、基于所述每个帧的人脸区域对所述长度统一数据进行提取,获得所述视频片段。
11、优选的,所述获得多尺度深度特征图的过程包括:
12、构建自注意力机制的深度学习模型,将所述视频片段输入至所述自注意力机制的深度学习模型中进行处理,获得每个阶段的输出特征;
13、构建卷积神经网络模型,将所述视频片段输入至所述卷积神经网络模型中进行处理,获得每层之间的输出特征;
14、将所述每个阶段的输出特征和每层之间的输出特征进行合并,获得所述多尺度深度特征图。
15、优选的,所述自注意力机制的深度学习模型中分支的每个阶段采用swintransformeblock以区块的形式连接并进行处理输出;
16、所述卷积神经网络模型采用resnet18的基础basicblock进行跳层连接并输出。
17、优选的,所述获得全局和局部信息的过程包括:将所述多尺度深度特征图进行关键信息学习,然后将进行关键信息学习的各个层级的特征图进行融合,获得所述全局和局部信息。
18、优选的,所述构建分类网络,将所述全局和局部信息输入至所述分类网络中进行处理,获得分类结果;
19、对所述分类结果进行迭代训练获得损失函数,
20、基于所述损失函数对所述分类结果进行迭代再处理,获得所述非受控条件下面部表情分类。
21、优选的,所述损失函数的表达式为:
22、
23、其中,yn是label(1或0),pn是对对象预测的概率。
24、本发明的技术效果为:
25、采用新的初始视频片段样本处理作为整个模型的输入,采用一种新的双分支结构特征提取,提取多尺度深度特征,对输入图像中信息的提取更加完善来增加网络的精度。采用新的基于注意力机制的关键信息学习和层级式特征融合方法,可以将来自不同层级的特征进行有效的融合,从而提升模型的性能。不同层级的特征包含了不同抽象级别的信息,通过融合这些特征,模型可以更好地理解和表示输入数据,提高模型对尺度变化的鲁棒性和模型的语义表达能力。
技术特征:
1.一种基于双分支视频的非受控条件下人脸面部表情预测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于双分支视频的非受控条件下人脸面部表情预测方法,其特征在于,所述获得视频片段的过程包括:
3.根据权利要求1所述的基于双分支视频的非受控条件下人脸面部表情预测方法,其特征在于,所述获得多尺度深度特征图的过程包括:
4.根据权利要求3所述的基于双分支视频的非受控条件下人脸面部表情预测方法,其特征在于,所述自注意力机制的深度学习模型中分支的每个阶段采用swintransformeblock以区块的形式连接并进行处理输出;
5.根据权利要求1所述的基于双分支视频的非受控条件下人脸面部表情预测方法,其特征在于,所述获得全局和局部信息的过程包括:将所述多尺度深度特征图进行关键信息学习,然后将进行关键信息学习的各个层级的特征图进行融合,获得所述全局和局部信息。
6.根据权利要求1所述的基于双分支视频的非受控条件下人脸面部表情预测方法,其特征在于,所述构建分类网络,将所述全局和局部信息输入至所述分类网络中进行处理,获得分类结果;
7.根据权利要求6所述的基于双分支视频的非受控条件下人脸面部表情预测方法,其特征在于,所述损失函数的表达式为:
技术总结
本发明公开了一种基于双分支视频的非受控条件下人脸面部表情预测方法,所述技术领域为人脸面部表情预测领域,包括:获取初始视频数据,将所述初始视频数据进行处理,获得视频片段;构建双分支网络结构,将所述视频片段通过双分支网络结构中进行处理,获得多尺度深度特征图;基于注意力机制,将所述多尺度深度特征图进行层级式特征融合,获得全局和局部信息;基于所述全局和局部信息对初始视频片段样本的面部表情融合特征进行分类,完成非受控条件下面部表情分类。本发明不同层级的特征包含了不同抽象级别的信息,通过融合这些特征,模型可以更好地理解和表示输入数据,提高模型对尺度变化的鲁棒性和模型的语义表达能力。
技术研发人员:吕杨,张富春,南智雄,马宗楠,曹楠,刘改慧
受保护的技术使用者:延安大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!