一种基于小样本机器学习的高精度疲劳寿命预测方法
本发明涉及一种基于小样本机器学习的高精度疲劳寿命预测方法,属于材料疲劳寿命预测领域。
背景技术:
1、疲劳是航空发动机叶片最主要的失效形式,也是最危险的失效形式,约90%的机械事故都和金属疲劳相关,疲劳断裂前一般没有明显的塑性变形,通常是在没有预兆的情况下突然破坏。因此,材料的疲劳寿命和疲劳强度一直是关乎机械机构可靠性和寿命评估的重要依据。
2、疲劳寿命可以通过实验确定,但由于合金制造和长期疲劳试验,需要大量的时间成本和试验成本,所以导致现有的疲劳数据样本普遍偏小。寿命预测方法有名义应力法、局部应力-应变法等,但这些传统的方法无法考虑到合金在复杂的工况下应用时影响因素与疲劳寿命之间的多维非线性关系,同时存在预测精度低的缺点。因此,实现小样本疲劳数据高精度寿命预测,对保障结构件服役安全性有重大意义。
3、近年来,深度学习已经成为材料研究的前沿方向和热点领域,并在预测效率和成本控制方面有显著优势。机器学习对非线性数据的出色拟合能力,因此可以从疲劳试验数据中挖掘学习,获得不同应力比、应力幅值与疲劳寿命间的映射关系。此外,迁移学习可以获取更强的泛化能力,同时解决数据样本较少的问题,避免了传统的机器学习算法因数据量少而产生过拟合问题,同时能减少计算成本,显著提高疲劳寿命预测精度。
4、基于上述原因,亟需开发一种基于小样本机器学习的高精度疲劳寿命预测方法,以节省研发和试验成本,为结构件安全服役奠定基础。
技术实现思路
1、本发明的目的在于提供一种基于小样本机器学习的高精度疲劳寿命预测方法,以实现小样本、低成本、高精度准确预测合金的疲劳寿命。
2、为了实现上述目的,本发明提供一种基于小样本机器学习的高精度疲劳寿命预测方法,具体包括以下步骤:
3、步骤一:获取钛铝合金的特征及工况条件作为一组数据,m组数据构成源域数据集ds;
4、步骤二:对步骤一源域数据集ds进行数值处理;
5、步骤三:将步骤二处理后的源域数据集随机划分为训练集和测试集,构建深度学习模型,设定参数集,用训练集训练该模型,用测试集评估训练后的模型,调整参数集,直至得到相对较优模型;
6、步骤四:另外获取钛铝合金的特征及工况条件作为一组数据,n组数据构成小样本目标域数据集dt;
7、步骤五:将步骤三得到的较优模型对目标域数据集dt进行基于模型的迁移学习,将目标域数据集dt随机划分为训练集和测试集,构建深度迁移学习模型,设定参数集,直至得到最优模型;
8、步骤六:采用步骤五所述最优模型对目标域数据集dt的测试集进行预测,获得该钛铝合金寿命预测结果。
9、较佳的,步骤一中,获取钛铝合金的特征和工况条件,钛铝合金的特征是指合金成分,工况条件包括应力比、应力幅值和疲劳寿命。
10、较佳的,步骤一中,m组数据构成源域数据集ds,m不小于100。
11、较佳的,步骤三中,将处理后的源域数据集随机划分为训练集和测试集,其中80%为训练集,20%为测试集。
12、较佳的,步骤三中,构建的深度学习模型为卷积神经网络模型。
13、较佳的,步骤三中,参数集包含神经元层数,每层神经元的个数,内核大小,卷积神经网络层数和激活函数种类。
14、较佳的,步骤三中,采用回归系数r2和均方根误差rmse作为准确率评估训练后的模型,
15、其中,回归系数r2为:
16、
17、其中,n为测试集中数据组的个数,yj为测试集中疲劳寿命,为测试集中模型预测的疲劳寿命,为测试集中所有疲劳寿命的平均值;
18、均方根误差为rmse为:
19、
20、其中,n为测试集中数据组的个数,yj为测试集中疲劳寿命,为测试集中模型预测的疲劳寿命。
21、较佳的,步骤三中,采用梯度下降算法调整参数集。
22、较佳的,步骤四中,n组数据构成小样本目标域数据集dt,n为m的1/3至1/2之间。
23、较佳的,步骤五中,所述的迁移学习是指正则化迁移学习。
24、与现有技术相比,本发明具有如下显著优点:
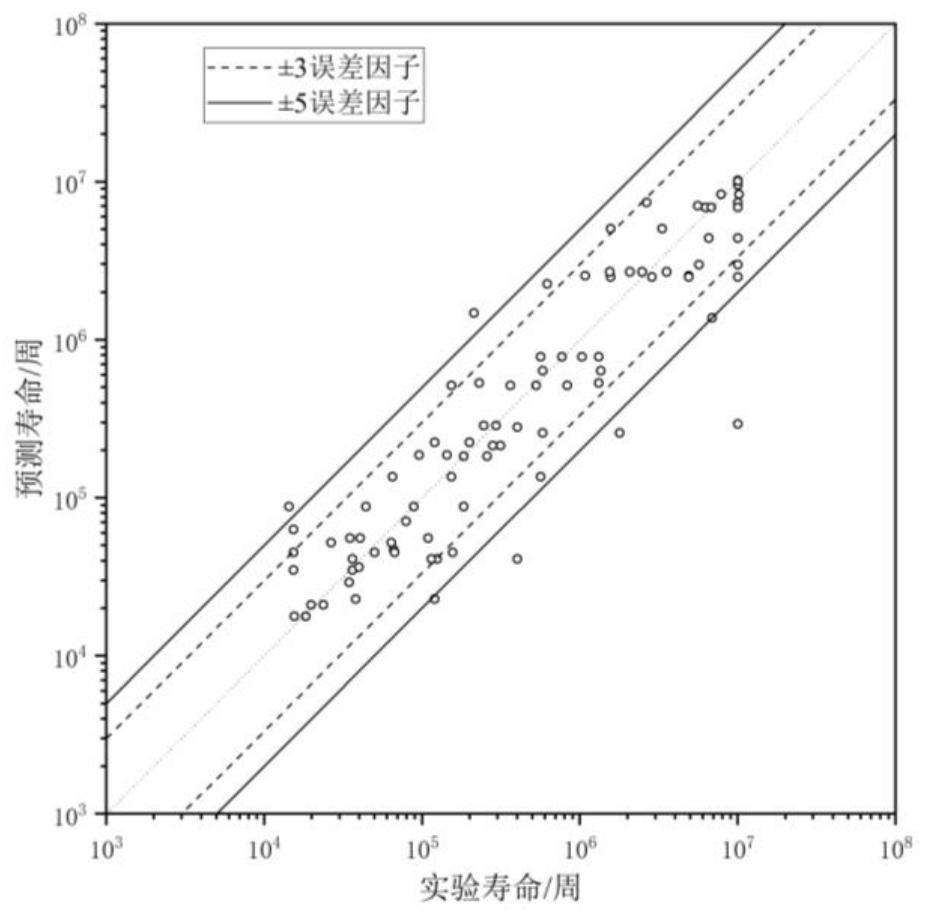
25、本发明通过建立合适的深度迁移神经网络模型,可以以较小的误差预测不同工况条件下的tnm合金疲劳寿命。同时解决数据样本较少的问题,避免了传统的机器学习算法因数据量少而产生过拟合问题,同时能减少计算成本,显著提高疲劳寿命预测精度。
技术特征:
1.一种基于小样本机器学习的高精度疲劳寿命预测方法,其特征在于,包括以下步骤:
2.如权利要求1所述的预测方法,其特征在于,步骤一和步骤四中,获取钛铝合金的特征和工况条件,钛铝合金的特征是指合金成分,工况条件包括应力比、应力幅值和疲劳寿命。
3.如权利要求1所述的预测方法,其特征在于,步骤一中,m组数据构成源域数据集ds,m不小于100。
4.如权利要求1所述的预测方法,其特征在于,步骤三和步骤五中,随机划分为训练集和测试集,其中80%为训练集,20%为测试集。
5.如权利要求1所述的预测方法,其特征在于,步骤三中,构建的深度学习模型为卷积神经网络模型。
6.如权利要求1所述的预测方法,其特征在于,步骤三和步骤五中,参数集包含神经元层数,每层神经元的个数,内核大小,卷积神经网络层数和激活函数种类。
7.如权利要求1所述的预测方法,其特征在于,步骤三中,采用回归系数r2和均方根误差rmse作为准确率评估训练后的模型,
8.如权利要求1所述的预测方法,其特征在于,步骤三中,采用梯度下降算法调整参数集。
9.如权利要求1所述的预测方法,其特征在于,步骤四中,n组数据构成小样本目标域数据集dt,n为m的1/3至1/2之间。
10.如权利要求1所述的预测方法,其特征在于,步骤五中,所述的迁移学习是指正则化迁移学习。
技术总结
本发明提供了一种基于小样本机器学习的高精度疲劳寿命预测方法,包括:获取一组疲劳寿命数据组作为源域数据集D<subgt;s</subgt;,数据处理后分为训练集和测试集,每组数据均包括合金成分、试验工况参数和疲劳寿命;建立卷积神经网络模型,采用梯度下降算法调整参数从而获取相对较优模型;另外获取一组小样本疲劳寿命数据组作为目标域数据集D<subgt;t</subgt;,通过上述得到的较优模型对D<subgt;t</subgt;进行基于模型的迁移学习以及调整参数后得到疲劳寿命预测模型;根据测试集的疲劳寿命数据组对所述模型精度进行验证。本发明利用迁移学习能获取更强的泛化能力,同时解决疲劳数据样本普遍偏少的问题,避免了传统算法因数据量少而产生过拟合问题,同时能减少计算成本,显著提高预测精度。
技术研发人员:相恒高,韩静,刘旭,陈光
受保护的技术使用者:南京理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!