基于深度学习的张口视频识别方法、系统、设备及介质与流程
本发明涉及计算机图像处理领域,具体地说是一种基于深度学习的张口视频识别方法、系统、设备及介质。
背景技术:
1、颞下颌关节盘前移位是颞下颌关节紊乱综合征的一种常见类型,在青少年人群中的发病率高达30%~40%,主要表现为关节区疼痛、杂音及下颌运动障碍;其主要原因为前移位的关节盘阻挡了髁突的正常滑行运动,且关节盘前移位后,后方的双板区受压产生疼痛,可能影响髁突和下颌骨的发育,造成颌骨畸形。部分病变严重的患者,关节头骨质被破坏,发生髁突吸收,可能造成严重的颌面部畸形如张口受限和张口偏斜。
2、患者由于关节盘不可复移位导致开口小于正常或完全不能张口(受限),张口偏斜指牙齿以及颌骨在水平向、矢状向及冠状向上的不协调,主要表现为面部不对称、颌部向一侧偏斜、牙弓不对称、上下牙列中线不一致、局部牙列锁合或反合等。现阶段临床上颞下颌关节盘前移位主要依靠就诊医师的临床诊断以及基于mri和ct的影像学辅助。
3、目前临床上颞下颌关节盘前移位的识别方式主要有以下两种:1.患者前往医院。寻求就诊医师的临床诊断2.基于患者核磁共振成像(mri)和计算机断层扫描(ct)的影像学材料进行辅助治疗。
4、然而,影像学受样本数量和医疗资源限制,诊断正确率不高,不利于大规模初筛。口腔颌面锥形束ct和mri在tmd的临床检查中虽已广泛应用,但目前国内尚无行业认可的检查规范;有些影像资料质量无法满足临床诊断要求,无效检查、重复检查时常发生,浪费了宝贵的医疗资源,加重了患者的医疗负担,甚至还可能导致错误的诊断和治疗。
技术实现思路
1、本发明为解决现有的问题,旨在提供一种基于深度学习的张口视频识别方法、系统、设备及介质。
2、为了达到上述目的,本发明采用的技术方案的第一方面提供了一种基于深度学习的张口视频识别方法,包含如下步骤:
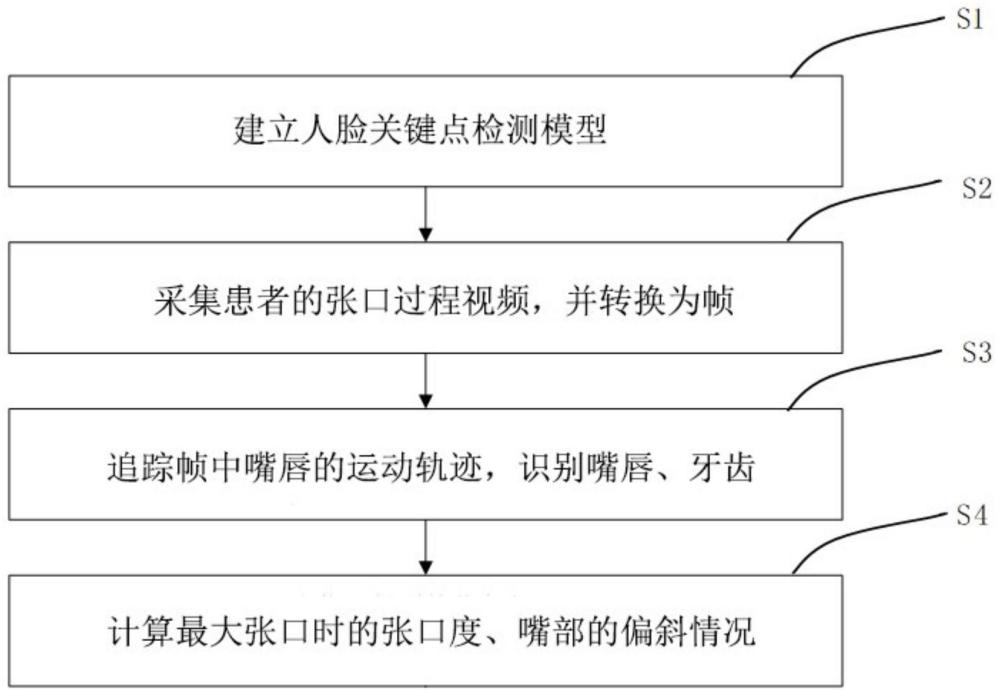
3、s1,建立人脸关键点检测模型;
4、s2,采集患者的张口过程视频,并转换为帧;
5、s3,用人脸关键点检测模型追踪帧中嘴唇的运动轨迹,并识别嘴唇、牙齿;
6、s4,计算最大张口时的张口度、嘴部的偏斜情况。
7、在一些实施例的s1中,采用opencv dlib库对一张正脸图像设置68个面部关键点的人脸关键点检测模型;人脸的关键点分为51个内部关键点和17个轮廓关键点。
8、在一些实施例的s2中,使用opencv库的cv2.videocapture()函数读取视频文件,然后循环遍历每一帧以读取帧图像;在一些实施例中,还进一步地将其转换为rgb格式的图像。
9、在一些实施例的s3中,使用utils.getlandmarks()函数检测每一帧中的人脸关键点。
10、在一些实施例的s3中,提取嘴巴边缘的关键点,截取嘴部的感兴趣区域。
11、在一些实施例的s3中,将嘴唇的关键点依次连接,通过阈值分割得到嘴唇区域的闭合图像。
12、在一些实施例的s3中,对于牙齿部分,基于阈值分割对帧图像的绿色通道直方图均衡化的值进行分割。
13、在一些实施例的s4中,根据检测到的人脸关键点,计算嘴巴张开的距离,即上下唇之间的距离;找到嘴巴张开程度最大的帧,作为关键帧。
14、在一些实施例的s4中,张口度通过计算最大张口时上下牙中间点的距离来实现。
15、在一些实施例的s4中,追踪视频中关键点的轨迹,以闭口原始位置为轨迹起点、以最大张口位置为轨迹终点,分析每帧位置变化;连接原始下颌目标点和眉间的关键点作为中线,比较下颌目标点的位置,识别闭口、张口、运动过程中嘴部的偏斜情况。
16、本发明的第二方面提供一种张口视频的识别系统,包括:
17、模型训练模块,用于建立人脸关键点检测模型;
18、采集转换模块,用于采集患者的张口过程视频,并转换为帧;
19、追踪识别模块,用于追踪帧中嘴唇的运动轨迹,并识别嘴唇、牙齿;
20、计算模块,用于计算最大张口时的张口度,并识别嘴部的偏斜情况。
21、本发明的第三方面提供一种张口视频的识别设备,包括处理器、以及用于存储处理器的可执行指令的存储器,所述处理器运行时执行任一上述的方法。
22、本发明的第四方面提供一种计算机可读介质,其上存储有计算机程序指令,其特征在于:所述计算机程序指令被处理执行时,实现任一上述的方法。
23、和现有技术相比,本发明通过基于深度学习技术在大量数据集上进行训练,针对患者的张口过程视频,再基于大规模数据集和视觉处理技术实现对张口受限及张口偏斜的识别,提高诊断效率、利于疾病的大规模初筛。
24、本发明通过视频关键帧提取,有效减少视频检索所需要花费的时间,并能够增强视频检索的精确度;通过提取嘴部和眼部的兴趣域进行处理,减少了计算的复杂程度,实现了线上轻量级辅助诊断的效果,实现了对于医疗资源的高效利用。
技术特征:
1.一种基于深度学习的张口视频识别方法,其特征在于包含如下步骤:
2.根据权利要求1所述的方法,其特征在于:s1中,采用opencv dlib库对一张正脸图像设置68个面部关键点的人脸关键点检测模型;人脸的关键点分为51个内部关键点和17个轮廓关键点。
3.根据权利要求1所述的方法,其特征在于:s2中,使用opencv库的cv2.videocapture()函数读取视频文件,然后循环遍历每一帧以读取帧图像;和/或将其转换为rgb格式的图像。
4.根据权利要求1或3所述的方法,其特征在于:s3中,使用utils.getlandmarks()函数检测每一帧中的人脸关键点。
5.根据权利要求4所述的方法,其特征在于:s3中,将嘴唇的关键点依次连接,通过阈值分割得到嘴唇区域的闭合图像。
6.根据权利要求1所述的方法,其特征在于:s4中,根据检测到的人脸关键点,计算嘴巴张开的距离,即上下唇之间的距离;找到嘴巴张开程度最大的帧,作为关键帧。
7.根据权利要求1所述的方法,其特征在于:s4中,追踪视频中关键点的轨迹,以闭口原始位置为轨迹起点、以最大张口位置为轨迹终点,分析每帧位置变化;连接原始下颌目标点和眉间的关键点作为中线,比较下颌目标点的位置,识别闭口、张口、运动过程中嘴部的偏斜情况。
8.一种张口视频的识别系统,其特征在于包括:
9.一种张口视频的识别设备,其特征在于:包括处理器、以及用于存储处理器的可执行指令的存储器,所述处理器运行时执行权利要求1-7中任一所述的方法。
10.一种计算机可读介质,其上存储有计算机程序指令,其特征在于:所述计算机程序指令被处理执行时,实现权利要求1-7中任一所述的方法。
技术总结
基于深度学习的张口视频识别方法、系统、设备及介质,方法包括:S1,建立人脸关键点检测模型;S2,采集患者的张口过程视频,并转换为帧;S3,用人脸关键点检测模型追踪帧中嘴唇的运动轨迹,并识别嘴唇、牙齿;S4,计算最大张口时的张口度、嘴部的偏斜情况。本发明通过基于深度学习技术在大量数据集上进行训练,针对患者的张口过程视频,基于大规模数据集和视觉处理技术实现对张口受限及张口偏斜的识别,提高诊断效率、利于疾病的大规模初筛。
技术研发人员:陈涛,李万章,朱紫珩,王立峰,冯渊
受保护的技术使用者:上海哈珥斯智能科技有限公司
技术研发日:
技术公布日:2024/5/10
- 还没有人留言评论。精彩留言会获得点赞!