一种多数据集的联合训练方法及终端与流程
本发明涉及图像处理,尤其涉及一种多数据集的联合训练方法及终端。
背景技术:
1、在进行多标签分类时,其数据集通常是由一个样例和一个集合的标签所组成的样本,该样本可能同时属于多个类别,例如一张图片中同时含有行人、自行车、小汽车等多个目标,则在数据集a中对应的目标标签为行人,在数据集b中对应的目标标签为自行车,在数据集c中对应的目标标签为小汽车,此时数据集a、b、c中的图像虽然同时包含行人、自行车以及小汽车三个目标,但是在进行标注时,每个数据集仅标注该数据集当前关注的目标。而目前实现多数据集的联合训练方法主要包括以下三种方式:
2、常规的方法:分别在不同的数据集上训练对应的模型,并将模型串联起来进行部署,同一个目标需要依次在多个模型上进行推理,得到对应的推理结果,最后将全部结果合并得到最终的输出;但是这种方法需要维护多个模型,且同一目标需要进行多次推理,存在大量的重复计算。
3、使用伪标签的方法:先使用大模型分别在不同的数据集上训练对应的分类模型(例如a模型、b模型、c模型等),然后使用训练好的大模型在其他未标注对应属性的数据上进行分类,生成伪标签;最后将标注的标签和生成的伪标签合并,即将多个数据集合并为一个数据集,再进行最终的分类模型训练,得到最终的联合分类模型;但是这种方法训练得到的大模型精度不是100%准确,在各个数据集全部生成伪标签以后,伪标签的数量远大于标注标签的数量,导致在最终的模型训练时,放大精度误差,影响最终输出的联合分类模型的精度。
4、半监督的训练方法:先使用半监督的方法进行模型训练,逐步增加未标注的数据,并生成对应的伪标签,将标注的标签和生成的伪标签合并,得到一个新的模型;然后再增加部分未标注数据集,生成伪标签,合并数据集,训练得到新模型;经过多次的迭代后得到最终的分类模型;但是这种方法生成的伪标签精度不可控,在数据集数量太大的情况下,伪标签的质量会严重影响最终输出的联合分类模型的精度。
技术实现思路
1、本发明所要解决的技术问题是:提供一种多数据集的联合训练方法及终端,无需维护多个模型,也无需生成伪标签,有效提高联合训练精度。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种多数据集的联合训练方法,包括:
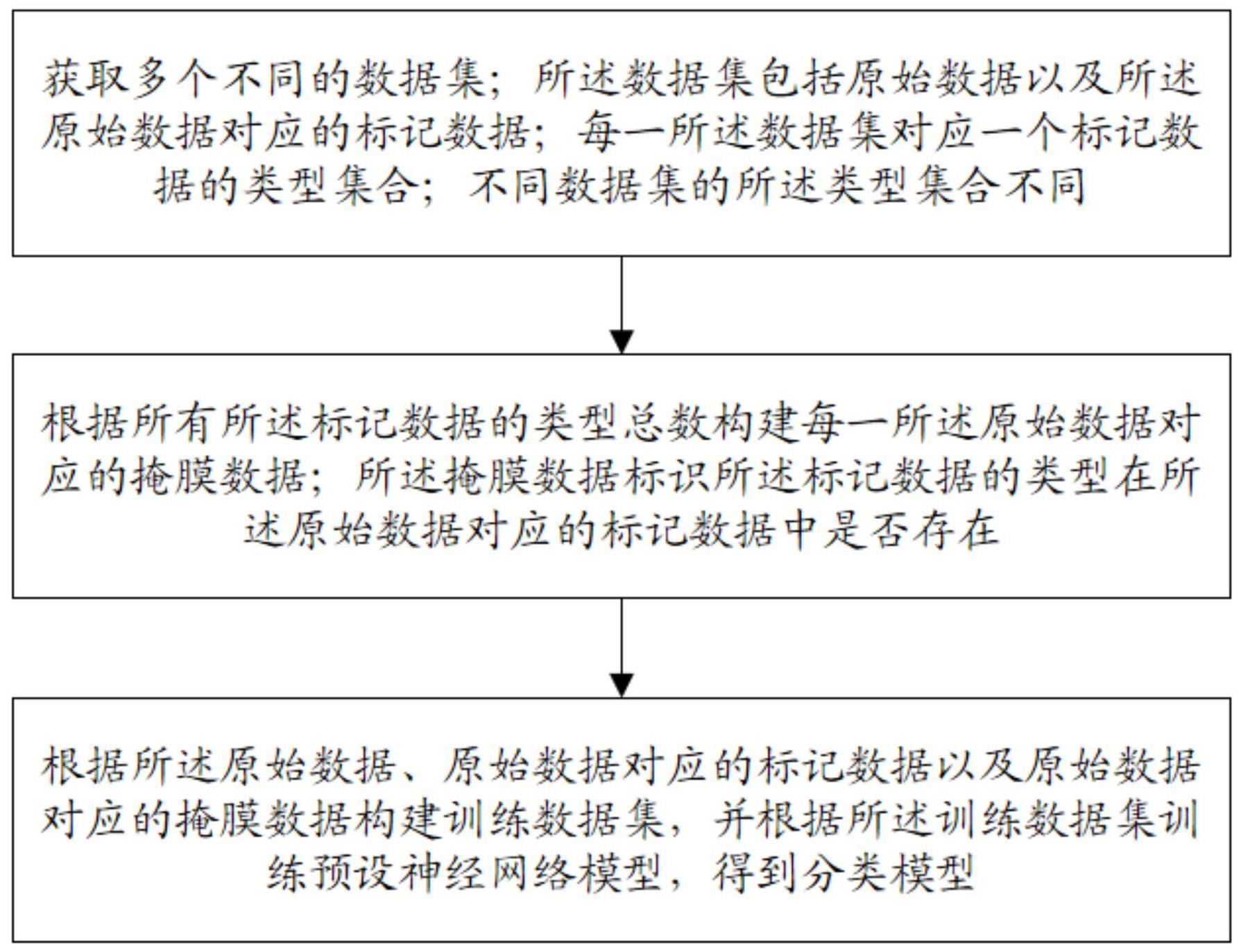
4、获取多个不同的数据集;所述数据集包括原始数据以及所述原始数据对应的标记数据;每一所述数据集对应一个标记数据的类型集合;不同数据集的所述类型集合不同;
5、根据所有所述标记数据的类型总数构建每一所述原始数据对应的掩膜数据;所述掩膜数据标识所述标记数据的类型在所述原始数据对应的标记数据中是否存在;
6、根据所述原始数据、原始数据对应的标记数据以及原始数据对应的掩膜数据构建训练数据集,并根据所述训练数据集训练预设神经网络模型,得到分类模型。
7、为了解决上述技术问题,本发明采用的另一种技术方案为:
8、一种多数据集的联合训练终端,包括存储器、处理器及存储在所述存储器上并在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种多数据集的联合训练方法中的各个步骤。
9、本发明的有益效果在于:通过一个预设神经网络模型上同时对多个不同的数据集上进行联合训练,得到最优分类模型,以此方式避免维护多个模型,减少模型推理次数,提高模型训练效率。同时本发明根据所有所述标记数据的类型总数构建掩膜数据,使得多个数据集在进行联合训练时,无需补充标注某一数据集中未标注数据,减少数据标注的工作量;并且避免在不同数据集上生成伪标签,屏蔽训练过程中未标注数据所带来的误差,提高多数据集的联合训练模型的精度。
技术特征:
1.一种多数据集的联合训练方法,其特征在于,包括:
2.根据权利要求1所述的一种多数据集的联合训练方法,其特征在于,所述根据所述训练数据集训练预设神经网络模型,得到分类模型,具体为:
3.根据权利要求2所述的一种多数据集的联合训练方法,其特征在于,所述得到迭代中的待选分类模型之后,还包括:
4.根据权利要求1或3所述的一种多数据集的联合训练方法,其特征在于,所述根据所述训练数据集训练预设神经网络模型之前,还包括:
5.根据权利要求4所述的一种多数据集的联合训练方法,其特征在于,所述根据所述测试集评估所述分类模型的精确度,具体为:
6.根据权利要求4所述的一种多数据集的联合训练方法,其特征在于,还包括:
7.根据权利要求2所述的一种多数据集的联合训练方法,其特征在于,所述根据所述模型预测结果、原始数据对应的标记数据以及原始数据对应的掩膜数据计算损失函数值,具体为:
8.根据权利要求4所述的一种多数据集的联合训练方法,其特征在于,所述根据所述原始数据、原始数据对应的标记数据以及原始数据对应的掩膜数据构建训练数据集,具体为:
9.根据权利要求1所述的一种多数据集的联合训练方法,其特征在于,所述根据所有所述标记数据的类型总数构建每一所述原始数据对应的掩膜数据,具体为:
10.一种多数据集的联合训练终端,包括存储器、处理器及存储在所述存储器上并在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1-9任意一项所述的一种多数据集的联合训练方法中的各个步骤。
技术总结
本发明提供的一种多数据集的联合训练方法及终端,通过一个预设神经网络模型上同时对多个不同的数据集上进行联合训练,得到最优分类模型,以此方式避免维护多个模型,减少模型推理次数,提高模型训练效率。同时本发明根据所有所述标记数据的类型总数构建掩膜数据,使得多个数据集在进行联合训练时,无需补充标注某一数据集中未标注数据,减少数据标注的工作量;并且避免在不同数据集上生成伪标签,屏蔽训练过程中未标注数据所带来的误差,提高多数据集的联合训练模型的精度。
技术研发人员:梁浩,张宇,刘东剑
受保护的技术使用者:深圳金三立视频科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!