基于深度学习的证件图像去噪增强方法与流程
本发明涉及文字识别,尤其涉及一种基于深度学习的证件图像去噪增强方法。
背景技术:
1、现有技术的证件识别过程中,大多通过证件阅读器的摄像头拍摄从而获取图像,在拍摄过程中,外界环境如照明条件、天气情况、光线条件均对图像质量造成一定的影响,产生图像中的版面是否清晰,文字是否受到损坏影响之类的问题,从而影响后期的证件识别成功率,此外,硬件设备条件受限时,识别结果的准确度同样存在风险,从而衍生出两种解决方式:硬件处理优化,配备遮光罩对拍摄区域进行保护,然而遮光罩的遮蔽范围有限,对于遮蔽范围之外的区域仍然暴露于现场的实际光源之下,当现场的设备顶端设置强光源时,生成的照片可能出现耀斑,从而影响到成像质量;通过传统图像处理算法优化,处理光照不均匀、硬件设备磨损等导致的图像污损或遮挡,以及因为相机内部光线的反射、散射,产生的图像光斑,上述步骤均需要传统图像处理算法单独进行阈值调试,且需结合特定的外景环境进行调试,工序繁琐。
技术实现思路
1、本发明的一个目的在于提供一种基于深度学习的证件图像去噪增强方法,采用超分辨率的方法对拍摄的图像进行修复和增强,对于证件图像的逐像素分析,从而提升证件图像的识别结果,鲁棒性较好,提升旅客的体验。
2、本发明的其它优势和特点通过下述的详细说明得以充分体现并可通过所附权利要求中特地指出的手段和装置的组合得以实现。
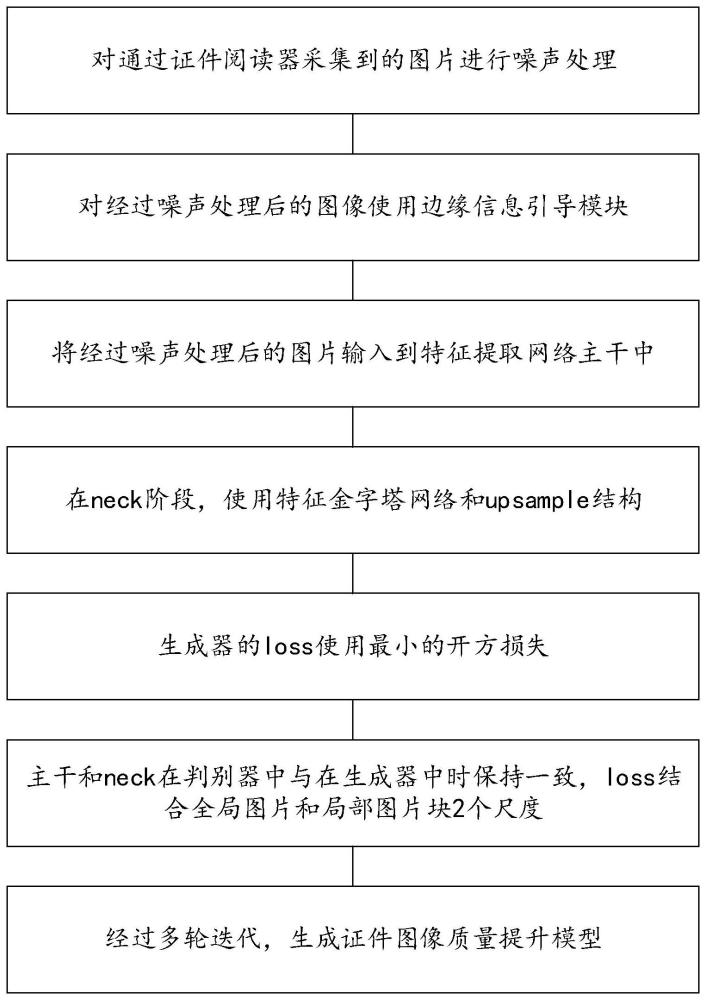
3、依本发明的一个方面,能够实现前述目的和其他目的和优势的本发明的一种基于深度学习的证件图像去噪增强方法,包括以下步骤:
4、对采集到的证件图像进行噪声处理;
5、对经过噪声处理后的证件图像使用边缘信息引导模块;
6、将获得的图像特征和rgb图像在x维度上进行拼接;
7、将经过噪声处理后的证件图像输入到特征提取网络主干中;
8、在neck阶段,使用特征金字塔网络和upsample结构;
9、生成器的loss使用最小的开方损失;
10、经过网络结构的多次训练优化,生成证件图像质量提升模型。
11、根据本发明的一个实施例,对经过噪声处理后的图像使用边缘信息引导模块时,边缘信息引导模块的算法流程如下:
12、使用sobel算子的水平核sh和垂直核sv分别计算水平和垂直方向的边缘信息eh和ev,得到边缘图像特征e:
13、
14、根据本发明的一个实施例,将获得的图像特征和rgb图像在x维度上进行拼接,增强图像的边缘信息,通过重复计算n1次,得到边缘图像特征fe:
15、fe={relu(wee+be)}n1
16、其中,we是网络结构中训练的参数,be是网络结构参数中的偏置,e是图像特征边缘。
17、根据本发明的一个实施例,将经过噪声处理后的图片输入到特征提取网络主干后,将网络结构中的网络层数和通道数通过depth_multiple:0.33和width_multiple:0.25进行调节,同时将其中的conv结构替换成了repvggblock。
18、根据本发明的一个实施例,在neck阶段,使用特征金字塔网络和upsample结构,从而获得高维和低维的特征输出,修复因为移动导致的成像模糊问题,同时加入shortcut分支。
19、根据本发明的一个实施例,生成器的loss使用最小的开方损失时,使用lsgan的损失函数:
20、
21、
22、主干和neck在判别器中与在生成器中时保持一致,loss结合全局图片和局部图片块2个尺度,loss整体公式如下:
23、lg=0.5×lp+0.006×lx+0.01×ladv
24、其中,lp表示均方误差损失,lx表示特征重建损失。
25、根据本发明的一个实施例,主干和neck在判别器中与在生成器中时保持一致,loss结合全局图片和局部图片块2个尺度时,特征重建损失如下:
26、
27、其中,表示损失网络第j层的激活,如果j是卷积层,那么是形状cj×hj×wj的特征图谱,特征重建损失表示的欧氏距离:
28、
29、其中,为预测结果,y为真实值,ladv表示全局和局部的损失,全局表示整个图片的mse损失,局部损失是将整个图片分块为一个一个重叠的同等大小的局部区域,从而推理得到的损失。
30、本发明的有益效果是:生成证件图像质量提升模型,将带有噪声、污损等内容的证件图像经过所述证件图像质量提升模型,生成图像质量清晰的证件图像,实现光斑噪声去除,从而提升证件识别效果,减少人工核验负担。
技术特征:
1.一种基于深度学习的证件图像去噪增强方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,对经过噪声处理后的图像使用边缘信息引导模块时,边缘信息引导模块的算法流程如下:
3.根据权利要求2所述的方法,其特征在于,将获得的图像特征和rgb图像在x维度上进行拼接,增强图像的边缘信息,通过重复计算n1次,得到边缘图像特征fe:
4.根据权利要求3所述的方法,其特征在于,将经过噪声处理后的图片输入到特征提取网络主干后,将网络结构中的网络层数和通道数通过depth_multiple:0.33和width_multiple:0.25进行调节,同时将其中的conv结构替换成了repvggblock。
5.根据权利要求4所述的方法,其特征在于,在neck阶段,使用特征金字塔网络和upsample结构,从而获得高维和低维的特征输出,修复因为移动导致的成像模糊问题,同时加入shortcut分支。
6.根据权利要求5所述的方法,其特征在于,生成器的loss使用最小的开方损失时,使用lsgan的损失函数:
7.根据权利要求6所述的方法,其特征在于,主干和neck在判别器中与在生成器中时保持一致,loss结合全局图片和局部图片块2个尺度时,特征重建损失如下:
技术总结
本发明公开了一种基于深度学习的证件图像去噪增强方法,包括以下步骤:对采集到的证件图像进行噪声处理;对经过噪声处理后的证件图像使用边缘信息引导模块;将获得的图像特征和RGB图像在x维度上进行拼接;将经过噪声处理后的证件图像输入到特征提取网络主干中;在neck阶段,对特征进行混合和尺寸调整,传递到预测层;生成器的损失函数使用最小的开方损失;经过网络结构的多次训练优化,生成证件图像质量提升模型。
技术研发人员:付雪平,夏炉系,张浒,黄鑫,苗应亮
受保护的技术使用者:盛视科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!