一种文本分类方法、装置及相关产品与流程
本申请涉及自然语言处理,尤其涉及一种文本分类方法、装置及相关产品。
背景技术:
1、文本分类是自然语言处理中的一项基础任务,被广泛应用于搜索、推荐、对话以及问答等多个业务场景。目前,随着文本类别数量的增多,通常会对文本进行多层次分类。例如,当用户输入文本“手机a”进行搜索时,会先确定“手机a”属于“商品-手机”这个类别,再根据该文本的类别确定搜索结果。其中,“商品-手机”中包括属于第一类别层次的类别“商品”,以及在“商品”下属于第二类别层次的类别“手机”。
2、相关技术中,对文本进行多层次分类的方案可以分为以下两种:
3、一种方案是,从多个类别中直接确定文本所属类别。但该方案将多个类别同等对待,没有利用类别的层次信息。另一种方案是,利用类别的层次信息,先从第一类别层次的多个类别中确定文本所属类别a,再从类别a下的第二类别层次的多个类别中确定文本所属类别b等,以此类推。但上文提及的两种方案均存在类似的问题:两种方案均调用训练好的文本分类模型进行文本分类,而层次较低的类别对应的文本样本数量可能会比较少,容易影响文本分类模型的训练效果,进一步导致模型输出的文本分类结果准确性不足。
技术实现思路
1、本申请实施例提供了一种文本分类方法、装置及相关产品,旨在提高文本分类结果的准确性,进而提高文本的分类准确率。
2、本申请第一方面提供了一种文本分类方法,包括:
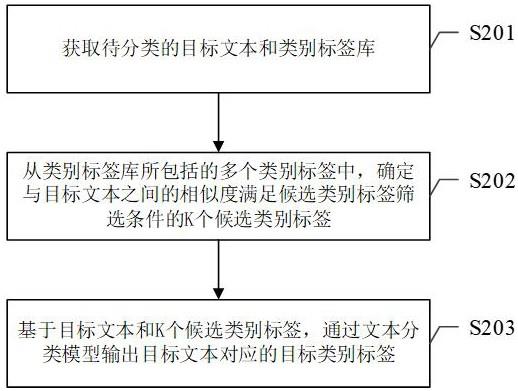
3、获取待分类的目标文本和类别标签库;所述类别标签库中包括多个类别标签,一个类别标签由属于至少一个类别层次的类别文本构成;所述类别层次用于表示类别在类别层次体系中所在的层次;所述类别层次体系包括至少两个类别层次;
4、从所述类别标签库所包括的多个类别标签中,确定与所述目标文本之间的相似度满足候选类别标签筛选条件的k个候选类别标签;所述k为大于1的整数;
5、基于所述目标文本和所述k个候选类别标签,通过文本分类模型输出所述目标文本对应的目标类别标签;所述目标类别标签为所述k个候选类别标签中与所述目标文本所属类别最匹配的一个类别标签。
6、本申请第二方面提供了一种文本分类装置,包括:
7、获取模块,用于获取待分类的目标文本和类别标签库;所述类别标签库中包括多个类别标签,一个类别标签由属于至少一个类别层次的类别文本构成;所述类别层次用于表示类别在类别层次体系中所在的层次;所述类别层次体系包括至少两个类别层次;
8、标签确定模块,用于从所述类别标签库所包括的多个类别标签中,确定与所述目标文本之间的相似度满足候选类别标签筛选条件的k个候选类别标签;所述k为大于1的整数;
9、标签输出模块,用于基于所述目标文本和所述k个候选类别标签,通过文本分类模型输出所述目标文本对应的目标类别标签;所述目标类别标签为所述k个候选类别标签中与所述目标文本所属类别最匹配的一个类别标签。
10、本申请第三方面提供了一种文本分类设备,所述设备包括处理器以及存储器:
11、所述存储器用于存储计算机程序,并将所述计算机程序传输给所述处理器;
12、所述处理器用于根据所述计算机程序中的指令执行第一方面提供的文本分类方法的步骤。
13、本申请第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序被文本分类设备执行时实现第一方面提供的文本分类方法的步骤。
14、本申请第五方面提供了一种计算机程序产品,包括计算机程序,该计算机程序被文本分类设备执行时实现第一方面提供的文本分类方法的步骤。
15、从以上技术方案可以看出,本申请实施例具有以下优点:
16、本申请技术方案中先获取待分类的目标文本和包括多个类别标签的类别标签库,一个类别标签由属于至少一个类别层次的类别文本构成,类别层次用于表示类别在类别层次体系中所在的层次,类别层次体系包括至少两个类别层次。然后,从类别标签库包括的多个类别标签中,确定与目标文本之间的相似度满足候选类别标签筛选条件的k个候选类别标签。随后,基于目标文本和k个候选类别标签,通过文本分类模型输出目标文本对应的目标类别标签,目标类别标签为k个候选类别标签中与目标文本所属类别最匹配的一个类别标签。本申请中利用类别标签本身的文本语义信息,先确定出k个候选类别标签,再通过文本分类模型从k个候选类别标签中确定出目标文本所属的目标类别标签。可见,该方案相较于相关技术,使得文本分类模型在文本样本数量较少的情况下,文本分类模型所输出的文本分类结果的准确性不再只依赖于文本样本数量,而是可以通过类别标签本身的文本语义信息,将文本分类模型输出的结果限定在与目标文本相似度高的k个候选类别标签中,也即限定了文本分类模型可输出的文本分类结果对应的类别标签的范围,避免文本分类模型从大量类别标签中确定目标文本对应的目标类别标签。因此能够提高文本分类结果的准确性,进而提高文本的分类准确率。
技术特征:
1.一种文本分类方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述候选类别标签筛选条件为类别标签与目标文本之间的相似度根据相似度从大到小的顺序排在前k个;所述从所述类别标签库所包括的多个类别标签中,确定与所述目标文本之间的相似度满足候选类别标签筛选条件的k个候选类别标签,具体包括:
3.根据权利要求1所述的方法,其特征在于,所述候选类别标签筛选条件为类别标签与目标文本之间的相似度大于相似度阈值;所述从所述类别标签库所包括的多个类别标签中,确定与所述目标文本之间的相似度满足候选类别标签筛选条件的k个候选类别标签,具体包括:
4.根据权利要求1所述的方法,其特征在于,所述从所述类别标签库所包括的多个类别标签中,确定与所述目标文本之间的相似度满足候选类别标签筛选条件的k个候选类别标签,具体包括:
5.根据权利要求1所述的方法,其特征在于,所述基于所述目标文本和所述k个候选类别标签,通过文本分类模型输出所述目标文本对应的目标类别标签,具体包括:
6.根据权利要求4所述的方法,其特征在于,所述向量转换模型为通过以下步骤训练获得的:
7.根据权利要求6所述的方法,其特征在于,所述基于所述目标语句、所述正样本语句、所述负样本语句以及待训练模型的损失函数,训练所述待训练模型,具体包括:
8.根据权利要求7所述的方法,其特征在于,所述获取所述目标语句的向量表示、所述正样本语句的向量表示以及所述负样本语句的向量表示,具体包括:
9.根据权利要求1或5所述的方法,其特征在于,所述文本分类模型为通过以下步骤训练获得的:
10.一种文本分类装置,其特征在于,包括:
11.一种文本分类设备,其特征在于,所述设备包括处理器以及存储器:
12.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质用于存储计算机程序,所述计算机程序被文本分类设备执行时实现权利要求1至9任一项所述的文本分类方法的步骤。
13.一种计算机程序产品,其特征在于,包括计算机程序,该计算机程序被文本分类设备执行时实现权利要求1至9任一项所述的文本分类方法的步骤。
技术总结
本申请公开一种文本分类方法、装置及相关产品,可应用于基于大模型的人工智能领域。方法中获取待分类的目标文本和类别标签库;从类别标签库所包括的多个类别标签中,确定与目标文本之间的相似度满足候选类别标签筛选条件的K个候选类别标签;基于目标文本和K个候选类别标签,通过文本分类模型输出目标文本对应的目标类别标签。该方案使得文本分类模型在文本样本数量较少的情况下,文本分类模型所输出的文本分类结果的准确性不再只依赖于文本样本数量,而是可以通过类别标签本身的文本语义信息,将文本分类模型输出的结果限定在与目标文本相似度高的K个候选类别标签中。因此能够提高文本分类结果的准确性,进而提高文本的分类准确率。
技术研发人员:杨韬
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!