同声传译模型训练方法、装置、电子设备及存储介质
本发明涉及自然语言处理,尤其涉及一种同声传译模型训练方法、装置、电子设备及存储介质。
背景技术:
1、通常,同声传译模型可以模拟真实同声传译场景的形式,即在接受源端文本输入的同时,进行目标端译文文本的生成。在进行模型训练时,需要为同声传译模型定义特定的读写策略来确定何时选择读取一个新的源端语言词语、以及何时选择生成一个目标端语言词语。
2、现有技术中,可以通过固定策略的方式定义读写策略,也可以通过自适应策略的方式定义读写策略。
3、然而,无论是固定策略还是自适应策略的同声传译模型,都存在严重的幻觉翻译现象(即模型生成的目标端译文文本所表达的意思,与输入的源端文本表达的意思完全无关),这使得同声传译模型的性能和用户的信任度大大降低。
技术实现思路
1、本发明提供一种同声传译模型训练方法、装置、电子设备及存储介质,用以解决现有技术中的同声传译模型存在严重的幻觉翻译现象,模型的性能和用户的信任度较低的问题。
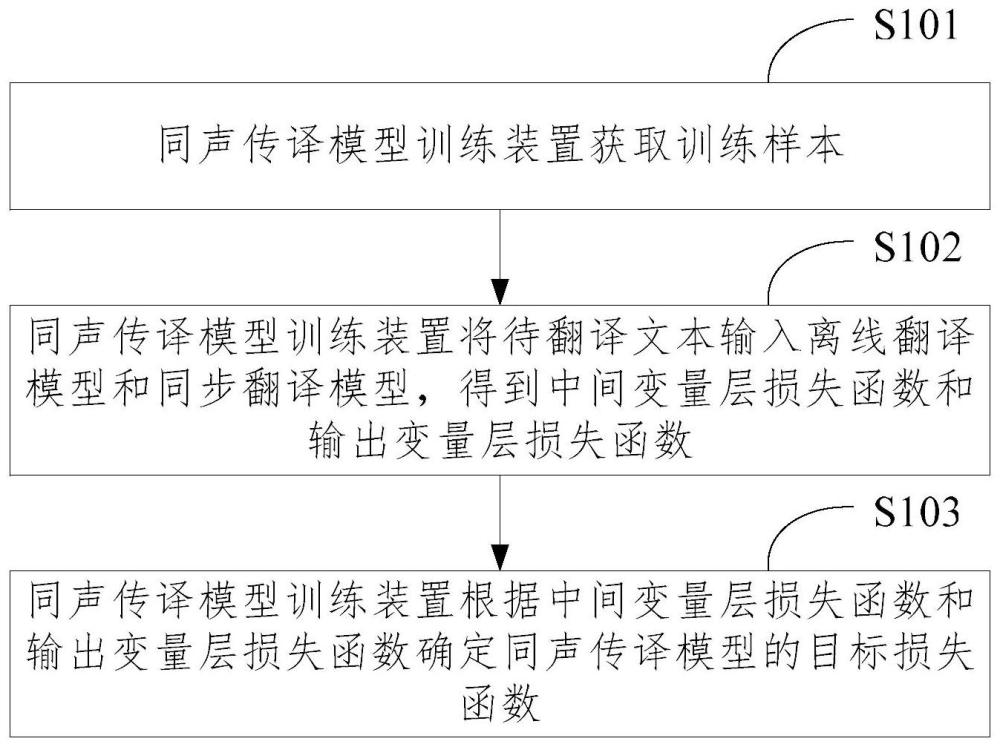
2、本发明提供一种同声传译模型训练方法,包括:获取训练样本,所述训练样本包括待翻译文本;将所述待翻译文本输入离线翻译模型和同步翻译模型,得到中间变量层损失函数和输出变量层损失函数;根据所述中间变量层损失函数和输出变量层损失函数确定同声传译模型的目标损失函数;其中,所述同声传译模型包括所述离线翻译模型和所述同步翻译模型。
3、根据本发明提供一种的同声传译模型训练方法,所述离线翻译模型包括第一编码器和第一解码器,所述同步翻译模型包括第二编码器和第二解码器;所述将所述待翻译文本输入离线翻译模型和同步翻译模型,得到中间变量层损失函数和输出变量层损失函数,包括:将所述待翻译文本输入所述离线翻译模型,得到所述第一编码器的第一编码向量和所述第一解码器的第一解码向量;将所述待翻译文本输入所述同步翻译模型,得到所述第二编码器的第二编码向量和所述第二解码器的第二解码向量;根据所述第一编码向量、所述第二编码向量、所述第一解码向量以及所述第二解码向量确定所述中间变量层损失函数。
4、根据本发明提供一种的同声传译模型训练方法,所述第一编码向量为所述第一编码器的偶数层输出;所述第二编码向量为所述第二编码器的偶数层输出;所述第一解码向量为所述第一解码器的偶数层输出;所述第二解码向量为所述第二解码器的偶数层输出。
5、根据本发明提供一种的同声传译模型训练方法,所述将所述待翻译文本输入离线翻译模型和同步翻译模型,得到中间变量层损失函数和输出变量层损失函数,包括:将所述待翻译文本输入所述离线翻译模型,得到第一概率分布;将所述待翻译文本输入所述同步翻译模型,得到第二概率分布;对所述第一概率分布和所述第二概率分布进行拟合处理,得到所述输出变量层损失函数。
6、根据本发明提供一种的同声传译模型训练方法,所述根据所述中间变量层损失函数和所述输出变量层损失函数确定同声传译模型的目标损失函数,包括:根据公式l=ltce+lsce+λ1lhrd+λ2lopd,确定目标损失函数l;其中,ltce为所述离线翻译模型的交叉熵损失函数,lsce为所述同步翻译模型的交叉熵损失函数,lhrd为所述中间变量层损失函数,lopd为所述输出变量层损失函数,λ1和λ2均为比例系数。
7、本发明还提供一种同声传译模型训练装置,包括:获取模块和处理模块;所述获取模块,用于获取训练样本,所述训练样本包括待翻译文本;所述处理模块,用于将所述待翻译文本输入离线翻译模型和同步翻译模型,得到中间变量层损失函数和输出变量层损失函数;根据所述中间变量层损失函数和输出变量层损失函数确定同声传译模型的目标损失函数;其中,所述同声传译模型包括所述离线翻译模型和所述同步翻译模型。
8、根据本发明提供一种的同声传译模型训练装置,所述离线翻译模型包括第一编码器和第一解码器,所述同步翻译模型包括第二编码器和第二解码器;所述处理模块,具体用于:将所述待翻译文本输入所述离线翻译模型,得到所述第一编码器的第一编码向量和所述第一解码器的第一解码向量;将所述待翻译文本输入所述同步翻译模型,得到所述第二编码器的第二编码向量和所述第二解码器的第二解码向量;根据所述第一编码向量、所述第二编码向量、所述第一解码向量以及所述第二解码向量确定所述中间变量层损失函数。
9、根据本发明提供一种的同声传译模型训练装置,所述第一编码向量为所述第一编码器的偶数层输出;所述第二编码向量为所述第二编码器的偶数层输出;所述第一解码向量为所述第一解码器的偶数层输出;所述第二解码向量为所述第二解码器的偶数层输出。
10、根据本发明提供一种的同声传译模型训练装置,处理模块具体用于:将所述待翻译文本输入所述离线翻译模型,得到第一概率分布;将所述待翻译文本输入所述同步翻译模型,得到第二概率分布;对所述第一概率分布和所述第二概率分布进行拟合处理,得到所述输出变量层损失函数。
11、根据本发明提供一种的同声传译模型训练装置,处理模块具体用于:根据公式l=ltce+lsce+λ1lhrd+λ2lopd,确定目标损失函数l;其中,ltce为所述离线翻译模型的交叉熵损失函数,lsce为所述同步翻译模型的交叉熵损失函数,lhrd为所述中间变量层损失函数,lopd为所述输出变量层损失函数,λ1和λ2均为比例系数。
12、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述同声传译模型训练方法的步骤。
13、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述同声传译模型训练方法的步骤。
14、本发明提供的同声传译模型训练方法、装置、电子设备及存储介质,可以获取训练样本,所述训练样本包括待翻译文本;将所述待翻译文本输入离线翻译模型和同步翻译模型,得到中间变量层损失函数和输出变量层损失函数;根据所述中间变量层损失函数和输出变量层损失函数确定同声传译模型的目标损失函数;其中,所述同声传译模型包括所述离线翻译模型和所述同步翻译模型。通过该方案,同声传译模型的目标损失函数是由中间变量层损失函数和输出变量层损失函数确定的,而中间变量层损失函数和输出变量层损失函数是基于离线翻译模型和同步翻译模型得到的,由于离线翻译模型的幻觉翻译现象较少,且离线翻译模型和同步翻译模型的模型结构相似,因此离线翻译模型可以为训练同声传译模型提供额外的监督信号,从而弥补同步翻译模型在训练过程中相比于离线翻译模型所欠缺的知识,帮助同步翻译模型学习更丰富的知识,进而减少同声传译模型中的幻觉翻译现象,提高模型性能和用户的信任度。
技术特征:
1.一种同声传译模型训练方法,其特征在于,包括:
2.根据权利要求1所述的同声传译模型训练方法,其特征在于,所述离线翻译模型包括第一编码器和第一解码器,所述同步翻译模型包括第二编码器和第二解码器;
3.根据权利要求2所述的同声传译模型训练方法,其特征在于,所述第一编码向量为所述第一编码器的偶数层输出;所述第二编码向量为所述第二编码器的偶数层输出;所述第一解码向量为所述第一解码器的偶数层输出;所述第二解码向量为所述第二解码器的偶数层输出。
4.根据权利要求1所述的同声传译模型训练方法,其特征在于,所述将所述待翻译文本输入离线翻译模型和同步翻译模型,得到中间变量层损失函数和输出变量层损失函数,包括:
5.根据权利要求1所述的同声传译模型训练方法,其特征在于,所述根据所述中间变量层损失函数和所述输出变量层损失函数确定同声传译模型的目标损失函数,包括:
6.一种同声传译模型训练装置,其特征在于,包括:获取模块和处理模块;
7.根据权利要求6所述的同声传译模型训练装置,其特征在于,所述离线翻译模型包括第一编码器和第一解码器,所述同步翻译模型包括第二编码器和第二解码器;
8.根据权利要求6所述的同声传译模型训练装置,其特征在于,所述处理模块,具体用于:将所述待翻译文本输入所述离线翻译模型,得到第一概率分布;将所述待翻译文本输入所述同步翻译模型,得到第二概率分布;对所述第一概率分布和所述第二概率分布进行拟合处理,得到所述输出变量层损失函数。
9.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至5中任一项所述的同声传译模型训练方法中的步骤。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至5中任一项所述的同声传译模型训练方法中的步骤。
技术总结
本发明提供一种同声传译模型训练方法、装置、电子设备及存储介质,应用于自然语言处理技术领域。该方法包括:获取训练样本,所述训练样本包括待翻译文本;将所述待翻译文本输入离线翻译模型和同步翻译模型,得到中间变量层损失函数和输出变量层损失函数;根据所述中间变量层损失函数和输出变量层损失函数确定同声传译模型的目标损失函数;其中,所述同声传译模型包括所述离线翻译模型和所述同步翻译模型。
技术研发人员:亢晓勉,于东磊,唐姝蓓,周玉
受保护的技术使用者:中国科学院自动化研究所
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!