一种基于编码技术的联邦学习方法
本发明涉及人工智能机器学习领域,涉及一种基于编码技术的联邦学习方法,以提升联邦学习收敛速度方法。
背景技术:
1、联邦学习(federated learning,fl)从2016年谷歌团队提出以来,已经在近几年得到了快速的发展,与传统的云计算在远程和集中的数据中心存储和处理最终用户的数据,联邦学习通过汇集网络边缘的可用资源(例如,智能手机、平板电脑、智能汽车、基站和路由器)参与整体模型的训练,使得服务提供更加接近最终用户。并且训练只在本地进行,进一步保障了用户的隐私。因此,联邦学习模型广泛运用于物联网领域,医院、银行等行业用于数据分析。
2、但是当联邦学习运用于大规模集群训练时,因为分布式计算模型的原因,往往在计算延迟和通信负载中权衡,来优化整体系统的性能。在联邦学习模型中往往存在冗余节点(即许多计算和存储点)是丰富的,并且随着网络大小线性增长。我们展示了编码在雾计算中的转换作用,以利用这种冗余来显著降低计算的带宽消耗和延迟。本发明主要是通过利用编码,以网络边缘丰富的计算资源换取通信带宽和延迟。提出了一个将最小延迟编码和最小带宽编码整和的编码框架,利用网络各个部分的可用或未充分利用的计算资源来实现显著降低计算带宽消耗和延迟的编码机会,这在联邦学习的实际运用中非常重要。
3、最小带宽编码是将计算负载因子(即评估r个精心选择的节点上的每次计算)用来创造新的编码机会,将计算所需的通信负载减少相同的因素。因此,可以利用最小带宽代码在网络边缘汇集未充分利用的计算资源,以大幅降低联邦学习计算的通信负载。最小延迟码能够在计算负载和计算延迟(即总作业响应时间)之间进行权衡。更具体地说,最小延迟码利用编码来有效地注入冗余计算,以减轻掉队者的影响,并通过与注入的冗余量成比例的乘法因子来加速计算。因此,通过在网络边缘利用更多的计算资源,最小延迟代码可以显著加联邦学习应用程序的速度。
技术实现思路
1、本发明解决的技术问题是:在联邦学习运用于大规模集群训练中,通信的负载和延迟一直是一个瓶颈。本发明充分发挥最小带宽编码和最小延迟编码的特性,提出了统一的编码框架,通过引入计算延迟和通信负载之间的权衡,将上述两个编码概念系统地结合在一起。该框架允许雾计算系统在权衡的任何点上操作,在该点上,最小带宽编码码和最小延迟编码可以分别被视为最小化通信负载和计算延迟的两个极值点。利用冗余计算来降低带宽消耗和延迟,提升联邦学习模型整体性能。
2、本发明包括以下步骤:
3、步骤(1):构建联邦学习框架,主要分为本地设备和云端服务器,与传统联邦学习不同的是本地客户端需要利用网络边缘执行任务。
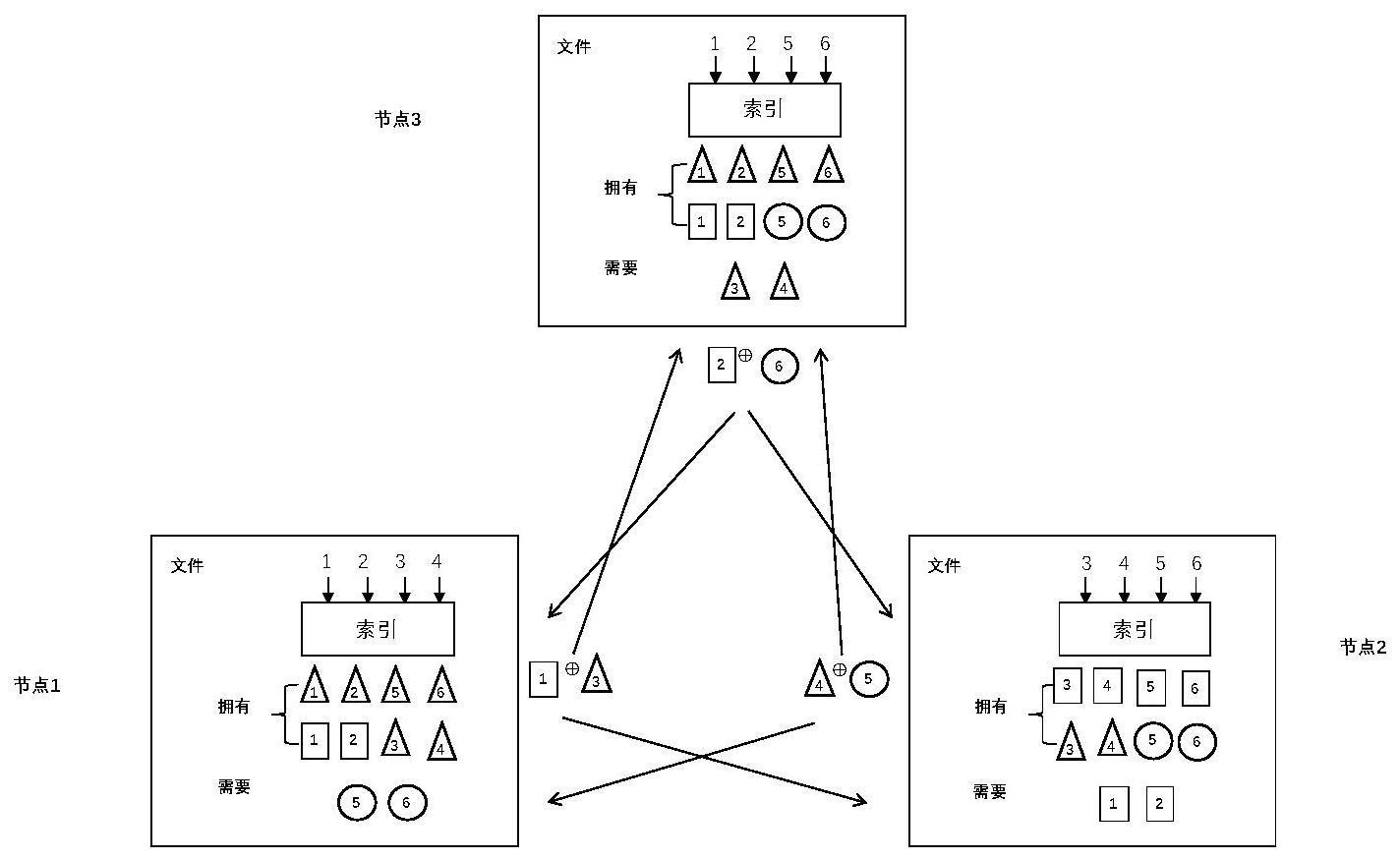
4、步骤(2):在数据混洗阶段,利用贪婪算法使最小带宽码指定的编码多播机会,直到满足所有节点的数据需求。
5、步骤(3):在计算的映射阶段,mds编码用于创建编码任务。然后,将这些任务分配给边缘节点以供本地执行,具体取决于映射阶段的计算延迟。一旦一定数量的节点完成了它们的本地计算,所有正在运行的映射任务将终止。
6、步骤(4):利用最小带宽代码和最小延迟代码编码技术,在本地计算中加入冗余在本地设备上传至云端服务器之前执行了更多的局部计算,来显著降低通信负载。
7、步骤(5):在边缘节点上运行分布式矩阵乘法的统一框架,选择计算延迟和通信负载之间选取权衡点,考虑两个点的极端,分别最小化通信负载和计算延迟。
8、步骤(6):接下来利用计算延迟和通信负载的权衡来优化总响应时间(总响应时间是混洗阶段的通信时间和映射阶段的计算延迟的总和)。
9、本发明有益效果:本发明提升联邦学习系统性能,利用最小带宽编码和最小延迟编码技术降低计算的宽带消耗和延迟。经过实验证实完成其映射工作时终止映射阶段的最小延迟代码实现了263s的总响应时间。使用统一的编码框架,我们可以等待最快的12个节点的最佳数量完成,并实现186s的最小总响应时间。因此,这种统一编码方法分别比最小带宽代码和最小延迟代码提供38.4%和29.3%的性能增益。
技术特征:
1.一种基于编码技术的联邦学习方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种基于编码技术的联邦学习方法,其特征在于:步骤(2)是在本地节点进行数据混洗时使用贪婪算法给最小带宽编码创造多播机会。贪心算法(greedy algorithm)是一种解决优化问题的常用算法设计策略。在贪心算法中,每一步都采取当前状态下最优的选择,而不考虑未来的影响。贪心算法通常适用于那些具有贪心选择性质的问题,即局部最优选择也是全局最优选择的问题。
3.根据权利要求1所述的一种基于编码技术的联邦学习方法方法,其特征在于:步骤(3)是利用mds编码创建编码任务再分配给边缘节点使用,根据映射阶段的特定计算延迟,只要一定数量的节点完成了它们的本地计算,所有正在运行的映射任务就会终止。mds编码是一种纠删码(erasure code)技术,旨在增强数据的冗余和容错性。它的主要思想是将原始数据切分成多个数据块,并生成额外的冗余块,以使数据在存储和传输过程中能够抵御硬件故障或数据丢失。mds编码的一个关键特性是,它可以在一定数量的数据块丢失或损坏的情况下,仍然能够完全恢复原始数据,具体是:
4.根据权利要求1所述的一种基于编码技术的联邦学习方法方法,其特征在于:步骤(5)是在边缘节点上运行分布式矩阵乘法的统一框架,选择计算延迟和和通信负载之间选取权衡点,考虑两个点的极端,分别最小化通信负载和计算延迟,具体是:步骤(5-1)利用最小带宽编码考虑k个节点协作从分布存储在节点处的n个输入文件中计算q个输出函数,计算的子任务比没有冗余的执行多r倍时(即,r=1)。可以得到等式:
技术总结
本发明公开了一种基于编码技术的联邦学习方法,属于人工智能机器学习领域,提升联邦学习系统性能,该方法充分发挥最小带宽编码和最小延迟编码的特性,提出了统一的编码框架。首先构建模型框架,对数据进行混洗,利用贪婪算法创造多播机会。其次在映射阶段,计算利用最小延迟和最小带宽编码技术计算通信负载和延迟。最后找到权衡点,优化总体响应时间。本发明能够有效地提升系统性能,实现了更高的模型推理速度。为后续联邦学习处理大规模集群数据提供了新的方法。
技术研发人员:毛德欢,魏贵义
受保护的技术使用者:浙江工商大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!