一种基于多维数据库查询的数据控制系统及方法与流程
本发明涉及数据库,更具体地说,涉及一种基于多维数据库查询的数据控制系统及方法。
背景技术:
1、多维数据库主要应用在商业智能和数据分析中,特别是在处理如数据仓库和olap(在线分析处理)系统的场景。多维数据库允许数据按照多个维度进行组织,例如时间、地点、产品类型、客户类型等。这样的组织方式使得用户能够非常灵活和直观地查询和分析数据,例如:“上月在上海销售的所有电视的总销售额是多少?”或“今年到目前为止,所有vip客户购买最多的商品是什么?”。
2、多维数据库面临的一个主要挑战就是数据的稀疏性。这是因为在实际的商业场景中,不是所有可能的维度组合都会有对应的数据。举例来说,假设在全球范围内销售100种产品,有1000个销售地点,跨越5年的时间,如果要为每种可能的产品、地点和时间组合都存储一个数据项,那么将会有至少5000000个数据点。但事实上,可能有许多产品在某些地点从未销售过,或者在某些时间段内没有销售记录。这就导致了多维数据库的稀疏性,即许多可能的维度组合并没有对应的数据。
3、这种数据的稀疏性会对多维数据库的查询效率产生影响,比如,如果我们仅仅查询某个维度的数据,那么可能存在大量的数据点没有数据,而查询时要遍历所有的数据并把存在的数据列出,这大大降低效率。另外,在对数据进行计算的时候,比如对某个维度的数据相加时,也需要遍历所有的数据并找出存在的数据,然后相加,这也大大降低了效率。
4、为了有效地处理多维数据库中的稀疏数据,其重点在于确认稀疏数据在哪里。通常的处理方式是,遍历多维数据库,检查每个数据点的度量值是否存在,如果某个数据点的度量值不存在,那么这个数据点就是一个“空格”,这个过程可以通过编程进行自动化,但对于大型多维数据库,这样的遍历可能需要消耗大量的计算资源和时间,而且数据库经常处于变化状态,这样遍历方式无法抓住“空格”存在的规律从而势必需要反复进行,而本发明试图采用深度学习模型来抓住“空格”存在的规律,从而即便数据库产生变化,也能够抓住“空格”存在的规律。
技术实现思路
1、本发明要解决的技术问题是提供一种基于多维数据库查询的数据控制系统及方法,以采用深度学习模型来抓住稀疏数据存在的规律,从而由此提高数据查询的效率。
2、为了达到上述目的,本发明采取以下技术方案:
3、一种基于多维数据库查询的数据控制方法,包括如下步骤:
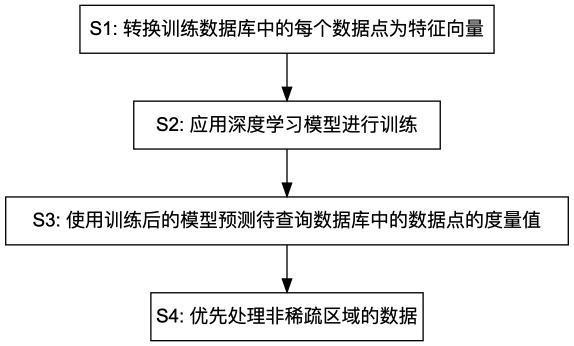
4、s1:将用于训练的多维数据库的每个数据点转换为一个特征向量,该特征向量包含表示数据点位置的维度值以及表示数据点度量的度量值,对于缺失的数据点,使用预定义的同一特殊值表示其度量值;
5、s2:应用深度学习模型进行训练,其中将数据点的维度值作为输入,将数据点的度量值作为标签进行训练,使得深度学习模型能够根据维度值预测度量值;
6、s3:将待查询的多维数据库输入训练后的深度学习模型,若预测出的数据点的度量值与s1中设定的预定义的特殊值的差值小于预设的阈值,则将该数据点纳入稀疏区域,并将除此之外的数据点纳入非稀疏区域;所述待查询的多维数据库与所述用于训练的多维数据库具有相同的维度和度量值含义;
7、s4:执行s3中多维数据库的数据查询或计算时,优先查询或计算s3步骤中分割出的非稀疏区域的数据。
8、在一些实施例中,所述深度学习模型选为lstm模型。
9、在一些实施例中,用于训练的多维数据库由从待查询的多维数据库中抽取出来的部分数据组成。
10、在一些实施例中,用于训练的多维数据库由某一时间段内的待查询的多维数据库中的数据组成。
11、本发明还公开一种基于多维数据库查询的数据控制系统,该系统包括:
12、数据转换模块:用于将训练用的多维数据库的每个数据点转换为一个特征向量,该特征向量包含表示数据点位置的维度值以及表示数据点度量的度量值,对于缺失的数据点,使用预定义的同一特殊值表示其度量值;
13、深度学习模块:用于对深度学习模型进行训练,其中将数据点的维度值作为输入,将数据点的度量值作为标签进行训练,使得深度学习模型能够根据维度值预测度量值;
14、数据分割模块:用于将待查询的多维数据库输入训练后的深度学习模型,若预测出的数据点的度量值与在数据转换模块中设定的预定义的特殊值的差值小于预设的阈值,则将该数据点纳入稀疏区域,并将除此之外的数据点纳入非稀疏区域;所述待查询的多维数据库与所述用于训练的多维数据库具有相同的维度和度量值含义;
15、数据查询模块:用于在执行s3中多维数据库的数据查询或计算时,优先查询或计算数据分割模块中分割出的非稀疏区域的数据。
16、在一些实施例中,所述深度学习模块使用的深度学习模型为lstm模型。
17、在一些实施例中,用于训练的多维数据库由从待查询的多维数据库中抽取出来的部分数据组成。
18、在一些实施例中,用于训练的多维数据库由某一时间段内的待查询的多维数据库中的数据组成。
19、本发明相对于现有技术的优点在于:
20、1)传统的方法在处理缺失数据时,往往需要遍历整个数据库来查找和标记缺失数据,这在大规模的数据库中是非常耗时和耗资源的。本发明通过训练深度学习模型,可以直接预测出哪些数据点可能为缺失数据,避免了遍历查找的过程,大大提升了效率。
21、2)本发明不仅可以预测出缺失数据,而且能够通过训练的模型捕捉到缺失数据并划分稀疏区域和非稀疏区域,发现一些数据缺失的规律,这对于理解数据缺失的原因,以及进一步完善数据收集和处理流程,都有着重要的指导意义。
22、3)通过将数据分为稀疏区域和非稀疏区域,本发明能够在执行数据查询或计算时,优先处理非稀疏区域的数据,提高了数据处理的效率。同时,由于非稀疏区域的数据更为完整和准确,因此优先处理这部分数据,也能减少错误预测带来的影响,提高了查询结果的质量。
23、4)本发明可以根据具体的业务需求和数据特性,选择不同的深度学习模型进行训练,例如lstm模型等。而且,可以通过调整模型的参数和超参数,优化模型的性能,使其更好地适应业务需求。
24、5)本发明包括了数据转换模块、深度学习模块、数据分割模块和数据查询模块等,形成了一套系统化的处理流程,能够实现对于多维数据库的全流程管理,提高了数据处理的效率和便利性。
技术特征:
1.一种基于多维数据库查询的数据控制方法,其特征在于,包括如下步骤:
2.根据权利要求1所述基于多维数据库查询的数据控制方法,其特征在于,所述深度学习模型选为lstm模型。
3.根据权利要求1所述基于多维数据库查询的数据控制方法,其特征在于,用于训练的多维数据库由从待查询的多维数据库中抽取出来的部分数据组成。
4.根据权利要求3所述基于多维数据库查询的数据控制方法,其特征在于,用于训练的多维数据库由某一时间段内的待查询的多维数据库中的数据组成。
5.一种基于多维数据库查询的数据控制系统,其特征在于,该系统包括:
6.根据权利要求5所述的基于多维数据库查询的数据控制系统,其特征在于,所述深度学习模块使用的深度学习模型为lstm模型。
7.根据权利要求5所述的基于多维数据库查询的数据控制系统,其特征在于,用于训练的多维数据库由从待查询的多维数据库中抽取出来的部分数据组成。
8.根据权利要求5所述的基于多维数据库查询的数据控制系统,其特征在于,用于训练的多维数据库由某一时间段内的待查询的多维数据库中的数据组成。
技术总结
本发明公开了一种基于多维数据库查询的数据控制系统及方法,涉及数据库技术领域,包括数据转换模块,将每个数据点转换为特征向量,包含数据点的维度值和度量值;深度学习模块,训练深度学习模型,使其能根据维度值预测度量值;数据分割模块,将待查询的多维数据库输入模型,预测出的数据点的度量值与特殊值的差值小于阈值的,纳入稀疏区域,其余纳入非稀疏区域;数据查询模块,执行多维数据库的数据查询或计算时,优先查询或计算非稀疏区域的数据。本发明可预测多维数据库中的稀疏区域,提高查询效率。
技术研发人员:刘勇
受保护的技术使用者:深圳市秦丝科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!