模型训练方法、装置、计算机设备及存储介质与流程
本申请涉及计算机,特别涉及一种模型训练方法、装置、计算机设备及存储介质。
背景技术:
1、在模型训练过程中,神经网络模型的训练和微调是两个核心的步骤。具体地,模型通常首先在大规模的通用数据集上进行预训练,然后在特定的任务数据集上进行微调,以便更好地适应新的任务和场景。但是这种训练方式面临一个重要的挑战,即灾难性遗忘(catastrophic forgetting)。也即是,当模型开始学习新的任务时,它可能会忘记在预训练阶段学习到的原始知识。例如,一个在多种语言数据集上预训练的模型可能会具有识别和理解各种语言的能力。但是,当模型在中文数据集上微调后,其对其他语言的理解可能会显著下降。因此,如何在模型训练过程中抑制模型的灾难性遗忘成为研究的重点。
技术实现思路
1、本申请实施例提供了一种模型训练方法、装置、计算机设备及存储介质,能够有效地抑制大型语言模型在参数调整过程中的灾难性遗忘现象,使得模型在任务上取得优异的性能的基础上,同时保留其预训练阶段学习到的丰富知识。所述技术方案如下:
2、一方面,提供了一种模型训练方法,所述方法包括:
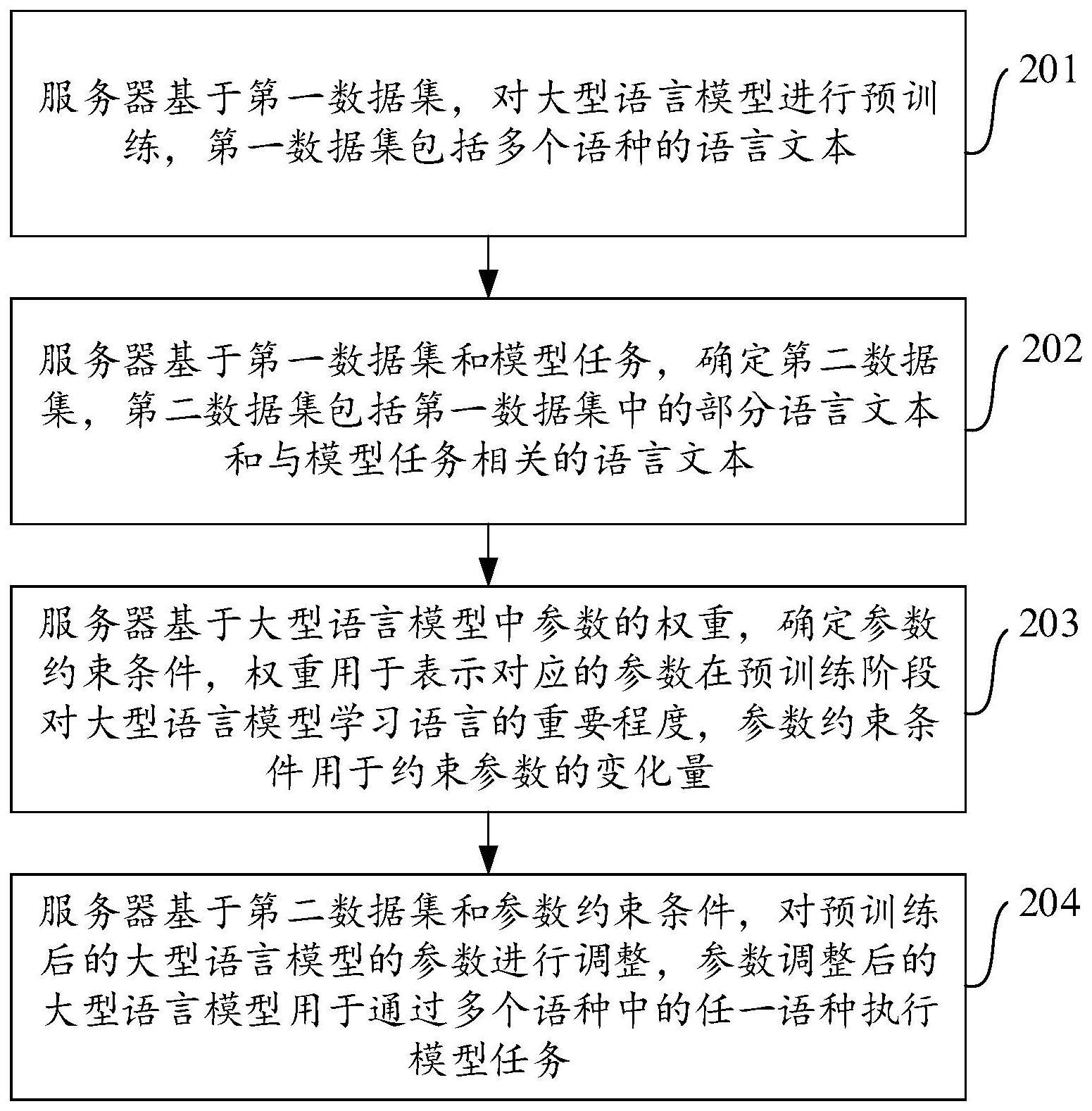
3、基于第一数据集,对大型语言模型进行预训练,所述第一数据集包括多个语种的语言文本;
4、基于所述第一数据集和模型任务,确定第二数据集,所述第二数据集包括所述第一数据集中的部分语言文本和与所述模型任务相关的语言文本;
5、基于所述大型语言模型中参数的权重,确定参数约束条件,所述权重用于表示对应的参数在预训练阶段对所述大型语言模型学习语言的重要程度,所述参数约束条件用于约束参数的变化量;
6、基于所述第二数据集和所述参数约束条件,对预训练后的所述大型语言模型的参数进行调整,参数调整后的所述大型语言模型用于通过所述多个语种中的任一语种执行所述模型任务。
7、另一方面,提供了一种模型训练装置,所述装置包括:
8、第一训练模块,用于基于第一数据集,对大型语言模型进行预训练,所述第一数据集包括多个语种的语言文本;
9、第一确定模块,用于基于所述第一数据集和模型任务,确定第二数据集,所述第二数据集包括所述第一数据集中的部分语言文本和与所述模型任务相关的语言文本;
10、第二确定模块,用于基于所述大型语言模型中参数的权重,确定参数约束条件,所述权重用于表示对应的参数在预训练阶段对所述大型语言模型学习语言的重要程度,所述参数约束条件用于约束参数的变化量;
11、第二训练模块,用于基于所述第二数据集和所述参数约束条件,对预训练后的所述大型语言模型的参数进行调整,参数调整后的所述大型语言模型用于通过所述多个语种中的任一语种执行所述模型任务。
12、在一些实施例中,所述第一确定模块,用于对于所述第一数据集中的任一语种,获取属于所述语种的语言文本;将所述多个语种的语言文本,作为第一文本子集;基于所述模型任务,获取第二文本子集;将所述第一文本子集和所述第二文本子集的合集,作为所述第二数据集。
13、在一些实施例中,所述第一确定模块,包括:
14、第一确定单元,用于对于所述第一数据集中的任一语言文本,基于所述语言文本的语义,确定所述语言文本的主题;
15、第一获取单元,用于从所述第一数据集中,获取主题与所述模型任务相关的语言文本,得到第三文本子集;
16、第二获取单元,用于基于所述模型任务,获取第二文本子集;
17、合并单元,用于将所述第二文本子集和所述第三文本子集的合集,作为所述第二数据集。
18、在一些实施例中,所述第一获取单元,用于对于所述第一数据集中的任一语言文本,基于所述语言文本的主题和所述模型任务,确定主题相似度,所述主题相似度用于表示所述语言文本的主题和所述模型任务之间的相关程度;从所述第一数据集中,获取主题相似度达到相似度阈值的语言文本,得到所述第三文本子集。
19、在一些实施例中,所述第二确定模块,包括:
20、第三获取单元,用于获取所述大型语言模型中参数的权重;
21、处理单元,用于对于所述大型语言模型的任一参数,将所述参数与所述参数的权重相乘,得到所述参数的约束项;
22、第二确定单元,用于基于所述大型语言模型中多个参数的约束项,确定所述参数约束条件,所述参数约束条件为所述大型语言模型的损失的一部分。
23、在一些实施例中,所述第二确定单元,用于从所述大型语言模型中的所有参数中,筛选出权重达到权重阈值的多个参数;对所述多个参数的约束项求和,得到参数约束条件。
24、在一些实施例中,所述第二确定模块,用于对于所述大型语言模型的任一参数,基于所述参数的权重,确定所述参数的学习率,所述参数的学习率与所述参数的权重负相关;基于所述大型语言模型中多个参数的学习率,确定参数约束条件。
25、在一些实施例中,所述第二训练模块,还用于采用权重衰减策略和dropout中的至少一种方式,对所述大型语言模型的参数进行调整。
26、另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器用于存储至少一段计算机程序,所述至少一段计算机程序由所述处理器加载并执行以实现本申请实施例中的模型训练方法。
27、另一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一段计算机程序,所述至少一段计算机程序由处理器加载并执行以实现如本申请实施例中模型训练方法。
28、另一方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序存储在计算机可读存储介质中,计算机设备的处理器从计算机可读存储介质读取该计算机程序,处理器执行该计算机程序,使得该计算机设备执行上述各个方面或者各个方面的各种可选实现方式中提供的模型训练方法。
29、本申请实施例提供了一种模型训练方法,在对大型语言模型进行预训练之后,从预训练所使用的第一数据集中获取语言文本以及与模型任务相关的语言文本来构成第二数据集,使得后续在基于模型任务对大型语言模型的参数进行调整的过程中,能够再次学习预训练所使用的语言文本,也即是使得大型语言模型能够回顾和利用预训练阶段的经验;并且还能够根据大语言模型中参数在预训练阶段对学习语言的重要程度,来确定参数约束条件,使得后续在基于模型任务对大型语言模型的参数进行调整的过程中,能够约束模型中参数的变化量,防止大型语言模型过度修改预训练阶段所学习到的知识,上述两种方式能够有效地抑制大型语言模型在参数调整过程中的灾难性遗忘现象,使得模型在任务上取得优异的性能的基础上,同时保留其预训练阶段学习到的丰富知识。
技术特征:
1.一种模型训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述第一数据集和模型任务,确定第二数据集,包括:
3.根据权利要求1所述的方法,其特征在于,所述基于所述第一数据集和模型任务,确定第二数据集,包括:
4.根据权利要求3所述的方法,其特征在于,所述从所述第一数据集中,获取主题与所述模型任务相关的语言文本,得到第三文本子集,包括:
5.根据权利要求1所述的方法,其特征在于,所述基于所述大型语言模型中参数的权重,确定参数约束条件,包括:
6.根据权利要求5所述的方法,其特征在于,所述基于所述大型语言模型中多个参数的约束项,确定所述参数约束条件,包括:
7.根据权利要求1所述的方法,其特征在于,所述基于所述大型语言模型中参数的权重,确定参数约束条件,包括:
8.根据权利要求1所述的方法,其特征在于,所述方法还包括:
9.一种模型训练装置,其特征在于,所述装置包括:
10.一种计算机设备,其特征在于,所述计算机设备包括处理器和存储器,所述存储器用于存储至少一段计算机程序,所述至少一段计算机程序由所述处理器加载并执行权利要求1至8任一项权利要求所述的模型训练方法。
11.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质用于存储至少一段计算机程序,所述至少一段计算机程序用于执行权利要求1至8任一项权利要求所述的模型训练方法。
12.一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至8任一项权利要求所述的模型训练方法。
技术总结
本申请提供了一种模型训练方法、装置、计算机设备及存储介质,属于计算机技术领域。所述方法包括:基于第一数据集,对大型语言模型进行预训练;基于所述第一数据集和模型任务,确定第二数据集;基于所述大型语言模型中参数的权重,确定参数约束条件,所述权重用于表示对应的参数在预训练阶段对所述大型语言模型学习语言的重要程度,所述参数约束条件用于约束参数的变化量;基于所述第二数据集和所述参数约束条件,对预训练后的所述大型语言模型的参数进行调整。上述方法能够有效地抑制大型语言模型在参数调整过程中的灾难性遗忘现象,使得模型在任务上取得优异的性能的基础上,同时保留其预训练阶段学习到的丰富知识。
技术研发人员:陈孝良,李良斌,常乐,黄赟贺
受保护的技术使用者:北京声智科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!