基于YOLOv5改进的主作业面人员检测方法与流程
本发明涉及建筑施工,具体涉及一种基于yolov5改进的主作业面人员检测方法。
背景技术:
1、目标检测是计算机视觉和数字图像处理领域非常热门的一个方向,在机器人巡航、自动驾驶、工业监控、智慧安防等诸多领域,均有广泛应用,可以为公司减少一定的人力成本。从2012年,hinton课题组通过构建cnn神经网络刷新imagenet记录夺冠以来,基于深度学习的目标检测技术进入了快速干道,得到了很快的发展。
2、目前基于深度学习的目标检测技术研究热点主要从以下方面展开:
3、a.以fasterrcnn为主的两阶段目标检测。
4、b.以yolo系列、ssd系列、retinanet为主的一阶段目标检测。
5、c.以centernet为主的anchorfree思想及以swin transformer为主的注意力思想。
6、基于算法部署成本考虑,一阶段的目标检测算法,往往在工业界更受欢迎,得到了广泛的应用。而最新的yolov5算法,在精度和速度上均达到了sota的水平,受到了工业界目标检测领域的一致好评。许多学者也愿意站在yolov5的肩膀上,对其精度和速度做大量的改进工作。本发明的发明构思也是以yolov5为基础脉络,在工业应用过程中,在不影响原有速度的基础上,大大提高了目标检测模型的精度。
7、与本发明最接近的技术方案为算法训练阶段使用图像金字塔方法,通过不同尺度下对输入图像进行缩放,生成一系列具有不同分辨率的图像。然后对每个尺度的图像进行标注,训练。这种方法看似模拟了主作业面的小尺寸人员图像,但是与真实的施工主作业面现场环境差别很大,对于主作业面上摆放的施工素材小尺寸人像的检测能够有一定效果提升,但是现有技术存在一定的缺陷。
8、目前的目标检测算法在小尺寸实体检测方面存在一些技术缺点,包括:
9、1)尺寸信息丢失:在小尺寸实体检测中,由于物体相对较小,存在尺寸信息的丢失。这可能导致难以准确地定位和检测小目标,因为其细节和上下文信息有限。
10、2)特征表示不足:小尺寸目标通常具有较少的像素信息,这使得提取具有判别性的特征表示变得更加困难。在卷积神经网络中,较小的目标可能在较高层级的特征图中丢失细节,使得难以对其进行有效的检测。
11、3)尺度失衡问题:目标检测算法通常在训练过程中使用具有各种尺度的训练样本,但小尺寸目标的样本数量往往较少。这可能导致在检测小尺寸实体时的尺度失衡问题,使得算法更倾向于检测大尺寸目标而忽略小尺寸目标。
12、4)目标边界模糊:由于小尺寸目标的像素数量较少,目标边界可能不够清晰和准确。这可能导致目标检测算法在边界定位和准确性方面存在困难,从而降低小尺寸实体检测的性能。
13、这些技术缺点对于小尺寸实体检测是普遍存在的挑战。
14、公开于该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域一般技术人员所公知的现有技术。
技术实现思路
1、为解决现有技术所存在的问题,本发明提供一种基于yolov5改进的主作业面人员检测方法,可以有效解决主作业面拍摄图像中小尺寸人员的检测问题,并提高检测的准确性和鲁棒性。
2、为了解决上述技术问题,本申请实施例提供了一种基于yolov5改进的主作业面人员检测方法,其包括:
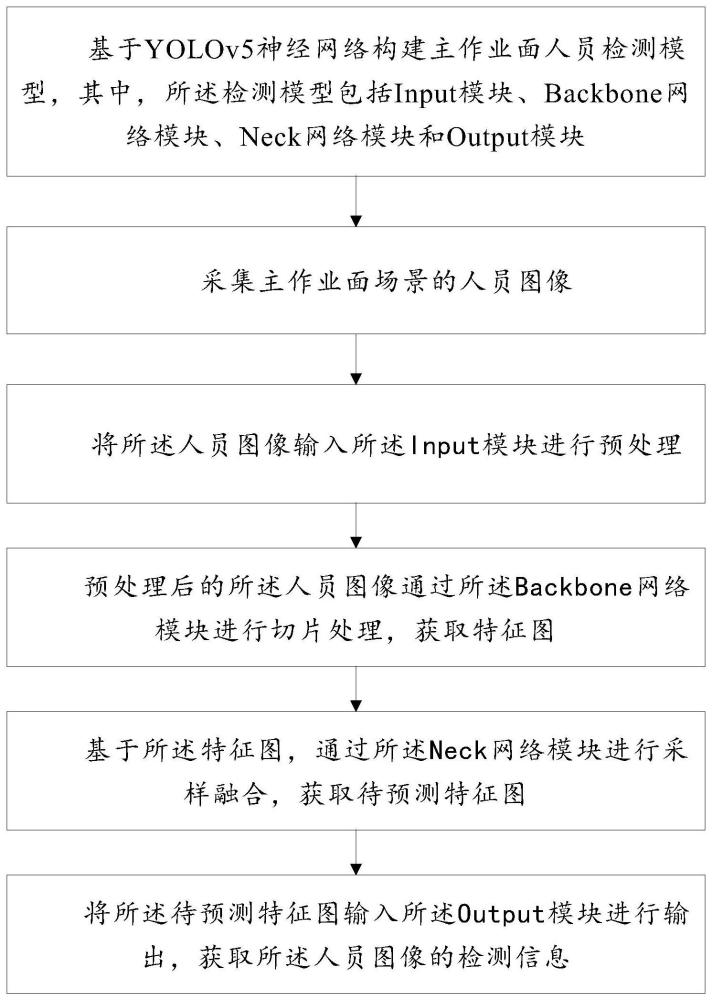
3、基于yolov5神经网络构建主作业面人员检测模型,其中,所述检测模型包括input模块、backbone网络模块、neck网络模块和output模块;
4、采集主作业面场景的人员图像;
5、将所述人员图像输入所述input模块进行预处理;
6、预处理后的所述人员图像通过所述backbone网络模块进行切片处理,获取特征图;
7、基于所述特征图,通过所述neck网络模块进行采样融合,获取待预测特征图;
8、将所述待预测特征图输入所述output模块进行输出,获取所述人员图像的检测信息。
9、进一步的,所述预处理为:对所述人员图像进行数据增强处理;
10、所述数据增强处理包括:对所述人员图像通过随机缩放、随机裁剪、随机排布的方式进行拼接。
11、进一步的,所述backbone网络模块基于cspdarknet53网络构建,通过卷积核对预处理后的所述人员图像进行切片。
12、进一步的,所述backbone网络模块输出四个尺度不同的特征图至所述neck网络模块;所述neck网络模块将fpn和pan结构相结合,对所述backbone网络模块得到四个尺度不同的特征图进行多尺度融合处理。
13、进一步的,基于yolov5神经网络构建主作业面人员检测模型包括:
14、获取人员图像的数据集,采用多尺度滑动窗口对所述数据集进行标注,将标注后的所述数据集划分为训练集和验证集;
15、选取所述yolov5神经网络;
16、基于所述训练集对所述yolov5神经网络进行训练,基于所述验证集对训练后的所述yolov5神经网络进行验证。
17、进一步的,基于所述训练集对所述yolov5神经网络进行训练还包括:采用giou_loss做bounding box的损失函数。
18、与现有技术相比,本发明具有以下有益效果:
19、1)图像增强:应用图像增强技术,如锐化、对比度增强等,以增强小尺寸图像中的细节,并提高人员检测的准确性和鲁棒性。
20、2)多尺度检测:利用多尺度检测方法,对裁剪后的图像进行不同尺度的检测,以覆盖不同大小的人员目标,提高检测率。
21、3)数据增强:通过数据增强技术,如旋转、缩放、平移等,生成更多样化的训练数据,以提高模型对小尺寸人员的检测能力。
22、4)深度学习模型优化:针对小尺寸图像的检测,可以对yolov5或其他深度学习模型进行特定优化,如调整网络结构、增加层级、改进损失函数等,以提高模型的适应性和准确性。
23、这些技术方案的组合可以有效解决主作业面拍摄图像中小尺寸人员的检测问题,并提高检测的准确性和鲁棒性。
技术特征:
1.一种基于yolov5改进的主作业面人员检测方法,其特征在于,包括:
2.根据权利要求1所述的基于yolov5改进的主作业面人员检测方法,其特征在于,所述预处理为:对所述人员图像进行数据增强处理;
3.根据权利要求1所述的基于yolov5改进的主作业面人员检测方法,其特征在于,所述backbone网络模块基于cspdarknet53网络构建,通过卷积核对预处理后的所述人员图像进行切片。
4.根据权利要求1所述的基于yolov5改进的主作业面人员检测方法,其特征在于,所述backbone网络模块输出四个尺度不同的特征图至所述neck网络模块;所述neck网络模块将fpn和pan结构相结合,对所述backbone网络模块得到四个尺度不同的特征图进行多尺度融合处理。
5.根据权利要求1所述的基于yolov5改进的主作业面人员检测方法,其特征在于,基于yolov5神经网络构建主作业面人员检测模型包括:
6.根据权利要求5所述的基于yolov5改进的主作业面人员检测方法,其特征在于,基于所述训练集对所述yolov5神经网络进行训练还包括:采用giou_loss做bounding box的损失函数。
技术总结
本发明公开了一种基于YOLOv5改进的主作业面人员检测方法,包括:基于YOLOv5神经网络构建主作业面人员检测模型,其中,检测模型包括Input模块、Backbone网络模块、Neck网络模块和Output模块;采集主作业面场景的人员图像;将人员图像输入Input模块进行预处理;预处理后的人员图像通过Backbone网络模块进行切片处理,获取特征图;基于特征图,通过Neck网络模块进行采样融合,获取待预测特征图;将待预测特征图输入Output模块进行输出,获取人员图像的检测信息。本发明可以有效解决主作业面拍摄图像中小尺寸人员的检测问题,并提高检测的准确性和鲁棒性。
技术研发人员:刘鹏,陈滨津,巩浩,张绪林,卜珂,孟毅,于恒,林阳
受保护的技术使用者:中国建筑第八工程局有限公司
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!