基于LangChain和大语言模型的问答方法和系统与流程
本申请总体上涉及数据处理领域,更具体地涉及一种基于langchain框架和大语言模型的问答方法和系统。
背景技术:
1、智能问答系统(question answering system,qa)是信息检索系统的一种高阶形式,其目的在于用使用简洁的自然语言准确地回答用户所提出的问题。与搜索引擎相比,问答系统能更好地理解用户问题的真实意图,从而能更有效地满足用户的需求,这些使得其在自然语言处理(natural language processing,nlp)领域中的关注度与日俱增并且发展前景十分广泛。
2、问答系统的发展历程可以简单概括为:基于结构化数据的问答系统、基于自由文本的问答系统、基于问题答案对的问答系统三个阶段。基于结构化数据的问答系统主要是面向限定领域,系统处理的数据类型是简单且高度结构化的数据,系统一般将输入问题转化为数据库查询语句,通过数据库的检索返回答案。基于自由文本的问答系统的处理流程主要包括:问题分析、文档检索及段落划分、候选答案抽取、答案排序、答案验证等。基于问题答案对的问答系统主要涉及社区问答(community question answering,cqa)与常见问答(frequently asked questions,faq)两种类型。
3、现有技术中提出了一种基于知识库的问答方法及系统。该问答方法包括:获取问题信息和问题信息对应的解决方案信息,并将问题信息和解决方案信息录入预设知识库;获取问题输入数据;对问题输入数据和预设知识库进行匹配,生成匹配结果;若匹配结果为匹配成功,生成与问题输入数据对应的答案反馈信息;若匹配结果为匹配失败,将问题输入数据上报至待完善问题列表。该方法需要将问题信息和其对应的解决方案信息录入预设的知识库中,会耗费大量的人力和时间,较为繁琐且开发成本较高。
4、另一方面,自chatgpt问世以来,大语言模型(large language model,llm)展现出了惊人的能力,并以爆发式增长态势应用到nlp相关的各个领域中。大语言模型是指使用海量文本数据训练的深度学习模型,通常拥有较大量级的参数,如亿级,千亿级。现有的llm主要采用transformer模型架构和预训练目标即语言进行建模。与小语言模型的主要区别在于,llm在很大程度上扩展了模型大小、预训练数据和总计算量(扩大倍数),llm可以更好地理解自然语言,并根据给定的上下文(例如,提示prompt)生成高质量的文本。
5、由此,在相关领域中提出了基于大语言模型和langchain框架的问答方法。llm已经是一个在海量数据集中训练过的模型,故针对公共领域问题已经可以给出比较好的回答,如常识类、代码类、数学计算类等。而针对垂直领域,则需要用户根据需求对llm进行微调训练,但微调模型会受到数据量、显卡资源等限制,往往表现的不好。langchain框架是一个十分强大的框架,它旨在帮助开发人员使用语言模型构建端到端的应用程序,通过其提供的工具、组件和接口,可以将大语言模型和外部数据结合,并允许语言模型和运行环境进行交互,故使用langchain结合知识库做垂直领域问答已成为当下比较令人感兴趣的智能问答系统构建方案。然而,目前的大多数方案只提出了基本的应用流程,对性能、准确度、行业应用等方面并没有深入研究介绍,如何将大语言模型和langchain框架更好地应用在所需领域中还需进一步探索。
技术实现思路
1、鉴于以上所述的问题,本申请提供了一种基于langchain框架和大语言模型的本地知识库问答方法和系统,且将其应用于机器人问答对话系统中,并针对如何在显卡资源有限的情况下更好地提升系统性能来对该问答方法和系统进行改进,以实现更为准确、更为高效的智能问答,同时更好地节约成本。
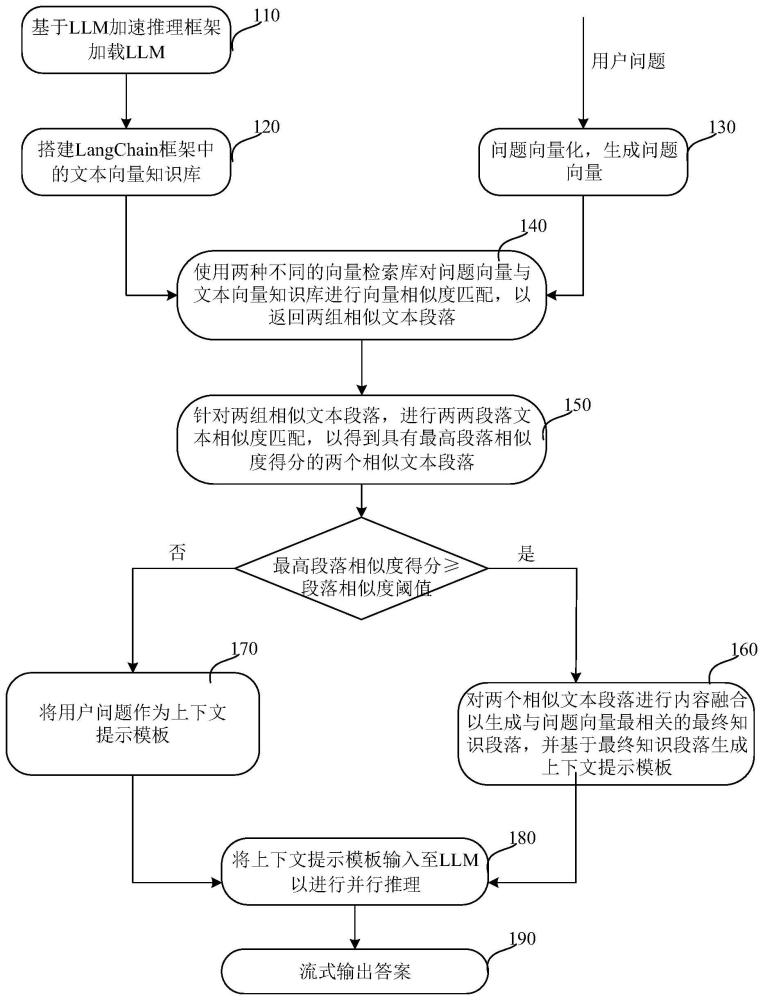
2、根据本申请的一方面,提供了一种基于langchain框架和大语言模型llm的问答方法,包括:基于llm加速推理框架来加载所述llm;搭建所述langchain框架中的文本向量知识库;对用户问题进行向量化以生成问题向量;使用两种不同的向量检索库对所述问题向量与所述文本向量知识库进行向量相似度匹配,以返回两组相似文本段落;针对所述两组相似文本段落,进行两两段落文本相似度匹配,以得到具有最高段落相似度得分的两个相似文本段落;当所述最高段落相似度得分高于或等于段落相似度阈值时,对所述两个相似文本段落进行内容融合以生成与所述问题向量最相关的最终知识段落,并基于所述最终知识段落生成上下文提示模板;当所述最高段落相似度得分低于所述段落相似度阈值时,将所述用户问题作为所述上下文提示模板;并且将所述上下文提示模板输入至所述llm中,以进行并行推理并且流式输出答案。
3、根据本申请的另一方面,提供了一种基于langchain框架和大语言模型llm的问答系统,包括:处理器,以及与所述处理器耦接的接口单元和存储单元,所述接口单元被配置为接收用户问题,所述存储单元被配置为存储所述llm和计算机程序指令,其中,所述处理器被配置为执行所述计算机程序指令来:基于llm加速推理框架来加载所述llm;搭建所述langchain框架中的文本向量知识库;对所述用户问题进行向量化以生成问题向量;使用两种不同的向量检索库对所述问题向量与所述文本向量知识库进行向量相似度匹配,以返回两组相似文本段落;针对所述两组相似文本段落,进行两两段落文本相似度匹配,以得到具有最高段落相似度得分的两个相似文本段落;当所述最高段落相似度得分高于或等于段落相似度阈值时,对所述两个相似文本段落进行内容融合以生成与所述问题向量最相关的最终知识段落,并基于所述最终知识段落生成上下文提示模板;当所述最高段落相似度得分低于所述段落相似度阈值时,将所述用户问题作为所述上下文提示模板;并且将所述上下文提示模板输入至所述llm中,以进行并行推理并且经由所述接口单元流式输出答案。
4、根据本申请的又一方面,提供了一种存储有程序指令的机器可读存储介质,其中,所述程序指令在被处理器执行时使得所述处理器执行如上所述的基于langchain框架和大语言模型llm的问答方法。
技术特征:
1.一种基于langchain框架和大语言模型llm的问答方法,包括:
2.根据权利要求1所述的问答方法,其中,基于所述最终知识段落生成上下文提示模板包括:
3.根据权利要求1或2所述的问答方法,其中,基于llm加速推理框架来加载所述llm包括:
4.根据权利要求1或2所述的问答方法,其中,搭建所述langchain框架中的文本向量知识库包括:
5.根据权利要求4所述的问答方法,其中,对所述用户问题进行向量化所使用的量化方法与对所述文本块进行向量化所使用的量化方法相同。
6.根据权利要求1或2所述的问答方法,其中,每组相似文本段落包括基于相应的向量检索库得到的具有最高k个相似度得分的k个相似文本段落。
7.根据权利要求2所述的问答方法,其中,将所述最终知识段落拆分为单句包括:按照字符方式将所述最终知识段落拆分为单句。
8.根据权利要求4所述的问答方法,其中,将所述文本拆分为文本块包括:按照字符加长度的方式将所述文本拆分为文本块。
9.根据权利要求4所述的问答方法,其中,所述本地知识文档采用以下格式中的一种或多种:文本、图片、便携式文档格式。
10.根据权利要求4所述的问答方法,其中,所述本地知识文档基于问答相关的领域而被选择并加载。
11.一种基于langchain框架和大语言模型llm的问答系统,包括:处理器,以及与所述处理器耦接的接口单元和存储单元,所述接口单元被配置为接收用户问题,所述存储单元被配置为存储所述llm和计算机程序指令,其中,所述处理器被配置为执行所述计算机程序指令来:
12.根据权利要求11所述的问答系统,其中,基于所述最终知识段落生成上下文提示模板包括:
13.根据权利要求11或12所述的问答系统,其中,基于llm加速推理框架来加载所述llm包括:
14.根据权利要求11或12所述的问答系统,其中,搭建所述langchain框架中的文本向量知识库包括:
15.根据权利要求14所述的问答系统,其中,对所述用户问题进行向量化所使用的量化方法与对所述文本块进行向量化所使用的量化方法相同。
16.根据权利要求11或12所述的问答系统,其中,每组相似文本段落包括基于相应的向量检索库得到的具有最高k个相似度得分的k个相似文本段落。
17.根据权利要求12所述的问答系统,其中,将所述最终知识段落拆分为单句包括:按照字符方式将所述最终知识段落拆分为单句。
18.根据权利要求14所述的问答系统,其中,将所述文本拆分为文本块包括:按照字符加长度的方式将所述文本拆分为文本块。
19.根据权利要求14所述的问答系统,其中,所述本地知识文档采用以下格式中的一种或多种:文本、图片、便携式文档格式。
20.根据权利要求14所述的问答系统,其中,所述本地知识文档基于问答相关的领域而被选择并加载。
21.一种存储有程序指令的机器可读存储介质,其中,所述程序指令在被处理器执行时使得所述处理器执行如权利要求1至10中任一项所述的基于langchain框架和大语言模型llm的问答方法。
技术总结
本申请涉及基于LangChain和大语言模型的问答方法和系统。该方法包括:基于加速推理框架来加载LLM;搭建文本向量知识库;对用户问题进行向量化以生成问题向量;使用两种不同的向量检索库对问题向量与文本向量知识库进行相似度匹配,返回两组相似文本段落;针对两组相似文本段落,进行两两段落相似度匹配,得到具有最高段落相似度得分的两个相似文本段落;当最高段落相似度得分高于或等于设定阈值时,对两个相似文本段落进行内容融合以生成最终知识段落,并基于最终知识段落生成上下文提示模板;当最高段落相似度得分低于设定阈值时,将用户问题作为上下文提示模板;将上下文提示模板输入至LLM中,进行并行推理并流式输出答案。
技术研发人员:邓博文,高珊
受保护的技术使用者:广州昂宝电子有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!