一种基于高斯核的跨模态网络的视频时空定位网络、方法
本发明属于视频语义与深度学习,具体涉及一种基于高斯核的跨模态网络的视频时空定位网络、方法。
背景技术:
1、自然语言的视频定位是一个基本但具有挑战性的问题,因为它在视觉语言理解中具有巨大的潜在应用。一般来说,它可以分为三个不同的类别:空间定位,时间定位和时空定位。其中,时空视频定位(stvg,spatio-temporal video grounding for multi-formsentences)更具挑战性,因为它不仅需要对复杂的多模态交互进行建模以进行语义对齐,而且还需要检索目标活动的空间位置和时间持续时间。如图1所示,stvg旨在根据给定的文本描述来定位待查询对象的时空位置。
2、大多数先前的空间或时间视频定位技术旨在通过直接检测每个视频帧的前景对象以进行对象相关性学习或通过回归边界来解决时间定位问题。
3、stvg任务的一项最新工作以更一般的方式解决了定位问题,它能够在未修剪的视频中将待查询对象的时空管定位。然而,所有这些定位方法都存在以下缺点:(1)它们严重依赖检测模型的检测质量。此外,它们通常使用检测到的锚框预生成提议区域,导致计算耗时。(2)他们通常单独处理视频帧,而不考虑连续帧之间的时间相关性。
技术实现思路
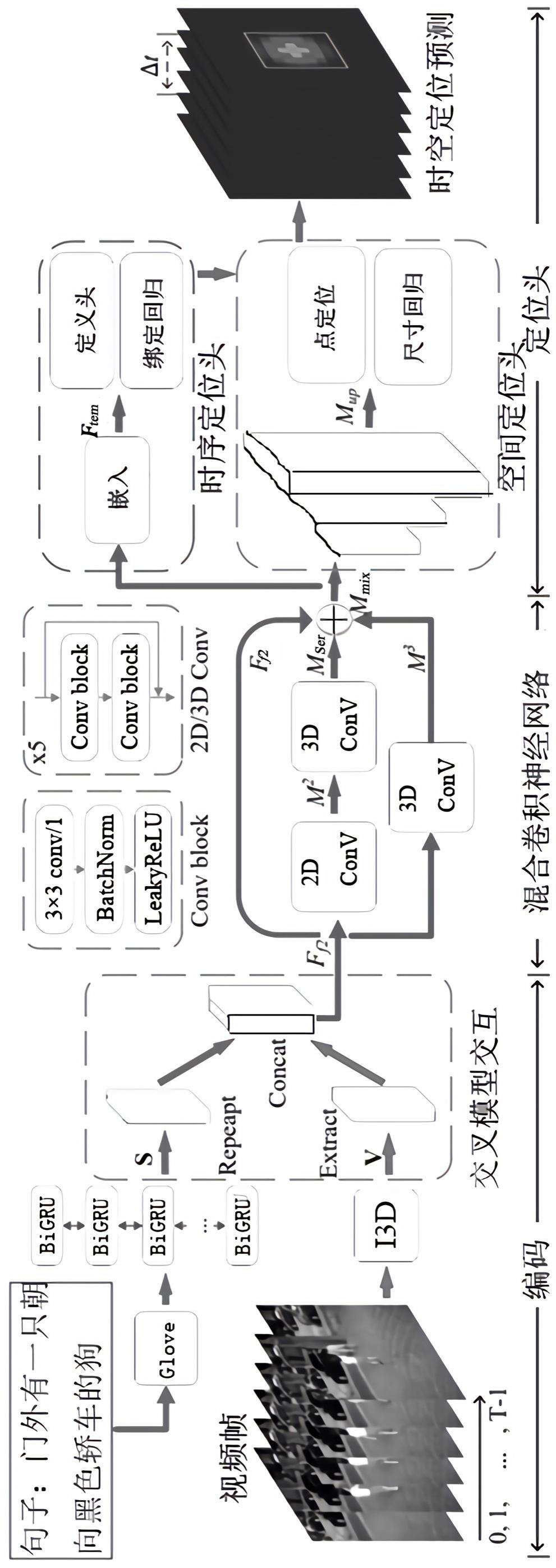
1、为解决时空视频定位依赖检测模型、计算耗时和未考虑连续帧之间的时间相关性的问题,在本发明的第一方面提供了一种基于高斯核的跨模态网络的视频时空定位网络,包括:获取模块,用于获取预设文本和待定位的视频帧;编码模块,用于通过预训练的第一卷积网络分别对文本和视频帧进行编码,得到视频特征v和文本特征s;以及将所述视频特征v和文本特征s进行跨模态交互,得到跨模态交互特征ff2;混合卷积网络,用于通过串行连接和并行连接的多个第二卷积网络,从跨模态交互特征ff2中提取序列特征mser和时间残差特征m3;以及将所述交互特征ff2、序列特征mser和时间残差特征m3融合,得到混合特征mmix;定位模块,用于通过混合特征mmix的重构和高斯核热图对预设文本进行空间定位;以及通过混合特征mmix和第三卷积网络对预设文本进行时间定位。
2、在本发明的一些实施例中,所述混合卷积网络包括:串行连接网络,用于从跨模态交互特征ff2中提取序列特征mser;并行连接网络,用于从跨模态交互特征ff2中提取时间残差特征m3;混合模块,用于将所述交互特征ff2、序列特征mser和时间残差特征m3融合,得到混合特征mmix。
3、在本发明的一些实施例中,所述定位模块包括:空间定位头,用于通过混合特征mmix的重构和高斯核热图对预设文本进行空间定位;时间定位头,通过混合特征mmix和第三卷积网络对预设文本进行时间定位。
4、进一步的,所述空间定位头包括:上采样单元,用于对混合特征mmix进行上采样,得到特征图mup;高斯核单元,用于将视频帧视为一系列以查询对象为热源中心的热图,并利用高斯核来描述对象位置的概率分布;点定位单元,用于学习基于高斯核的热图监督的预测热图,并对预设文本进行关键点定位;尺寸回归单元,用于通过对特征图mup进行尺寸回归,并定义预设文本对应的对象的尺寸。
5、进一步的,所述时间定位头包括:输入层,将混合特征mmix放入到预设的时间位置区间中,得到一个或多个第一时间边界;嵌入层,用于从时间边界中提取不同的时间长度特征,并通过自注意力机制增强所述不同的时间长度特征的时序性,得到一个或多个第二时间边界;置信单元,用于对一个或多个第二时间边界进行置信评估,并从其中筛选出置信度最高的第二时间边界;边界回归单元,用于对第二时间边界回归,调整第二时间边界的偏移量。
6、在上述的实施例中,所述第一卷积网络为i3d网络。
7、在上述的实施例中,第三卷积网络包括:至少包括1个3维卷积层、1个bi-gru和1维卷积层。
8、本发明的第二方面,提供了一种基于高斯核的跨模态网络的视频时空定位方法,包括:获取预设文本和待定位的视频帧;通过预训练的第一卷积网络分别对文本和视频帧进行编码,得到视频特征v和文本特征s;将所述视频特征v和文本特征s进行跨模态交互,得到跨模态交互特征ff2;通过串行连接和并行连接的多个第二卷积网络,从跨模态交互特征ff2中提取序列特征mser和时间残差特征m3;将所述交互特征ff2、序列特征mser和时间残差特征m3融合,得到混合特征mmix;通过混合特征mmix的重构和高斯核热图对预设文本进行空间定位;通过混合特征mmix和第三卷积网络对预设文本进行时间定位。
9、本发明的第三方面,提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明在第二方面提供的基于高斯核的跨模态网络的视频时空定位方法。
10、本发明的第四方面,提供了一种计算机可读介质,其上存储有计算机程序,其中,所述计算机程序被处理器执行时实现本发明在第二方面提供的基于高斯核的跨模态网络的视频时空定位方法。
11、本发明的有益效果是:
12、本发明提出第一个用于时空视频接地的无锚模型gkcmn(基于高斯核的交叉模态网络或基于高斯核的跨模态网络),它利用高斯核来突出目标语义的最重要区域;同时设计了一个混合卷积网络来捕获时间和空间信息;在vidstg数据集上进行评估,证明了gkcmn模型的准确性、精度和有效性。
技术特征:
1.一种基于高斯核的跨模态网络的视频时空定位网络,其特征在于,包括:
2.根据权利要求1所述的基于高斯核的跨模态网络的视频时空定位网络,其特征在于,所述混合卷积网络包括:
3.根据权利要求1所述的基于高斯核的跨模态网络的视频时空定位网络,其特征在于,所述定位模块包括:
4.根据权利要求3所述的基于高斯核的跨模态网络的视频时空定位网络,其特征在于,所述空间定位头包括:
5.根据权利要求4所述的基于高斯核的跨模态网络的视频时空定位网络,其特征在于,所述时间定位头包括:
6.根据权利要求1至5任一项所述的基于高斯核的跨模态网络的视频时空定位网络,其特征在于,所述第一卷积网络为i3d网络。
7.根据权利要求1至5任一项所述的基于高斯核的跨模态网络的视频时空定位网络,其特征在于,其特征在于,包括:第三卷积网络包括:至少包括1个3维卷积层、1个bi-gru和1维卷积层。
8.一种基于高斯核的跨模态网络的视频时空定位方法,其特征在于,包括:
9.一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现如权利要求8所述的基于高斯核的跨模态网络的视频时空定位方法。
10.一种计算机可读介质,其上存储有计算机程序,其中,所述计算机程序被处理器执行时实现如权利要求8所述的基于高斯核的跨模态网络的视频时空定位方法。
技术总结
本发明涉及一种基于高斯核的跨模态网络的视频时空定位网络,其网络包括:混合卷积网络,用于通过串行连接和并行连接的多个第二卷积网络,从跨模态交互特征F<subgt;f2</subgt;中提取序列特征M<subgt;ser</subgt;和时间残差特征M<supgt;3</supgt;;以及将所述交互特征F<subgt;f2</subgt;、序列特征M<subgt;ser</subgt;和时间残差特征M<supgt;3</supgt;融合,得到混合特征M<subgt;mix</subgt;;定位模块,用于通过混合特征M<subgt;mix</subgt;的重构和高斯核热图对预设文本进行空间定位;以及通过混合特征M<subgt;mix</subgt;和第三卷积网络对预设文本进行时间定位。本发明通过部署混合串行和并行连接网络来学习多模态表示的空间非局部信息和时间建模,然后利用高斯热图和置信度实现了视频时空定位和模型的无锚化,提高定位的准确性和精度。
技术研发人员:周潘,熊泽雨,朱佳昊,彭洋,徐子川,袁增辉
受保护的技术使用者:华中科技大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!