一种数据处理方法、装置、计算机设备及存储介质与流程
本发明涉及计算机,具体涉及一种数据处理方法、装置、电子设备及存储介质。
背景技术:
1、现在比较常见的将原数据库中的数据同步至目标数据库中的方法:基于oracle数据库的业务系统。为了方便不同数据库实例同步数据,采用定时的方式从其他数据库实例中查询数据并同步到物化视图中。这种方式仅能适用于初期或是规模较小的业务。但随着业务的发展,各个业务开始进行服务的拆分和微服务的改造。在改造的过程中数据库的成本上升和资源消耗大会导致效率急剧下降,对原数据库造成很大的影响,进而有些应用需要去除资源消耗较高的oracle数据库,采用资源消耗较低的mysql数据库。这时oracle物化视图同步这种耦合度很高的数据同步方式已经不能满足业务发展的需要。
技术实现思路
1、有鉴于此,本发明实施例提供了一种数据处理方法、装置、电子设备及存储介质,以解决较大规模业务服务拆分和微服务改造中数据同步资源浪费和数据耦合度较高的问题。
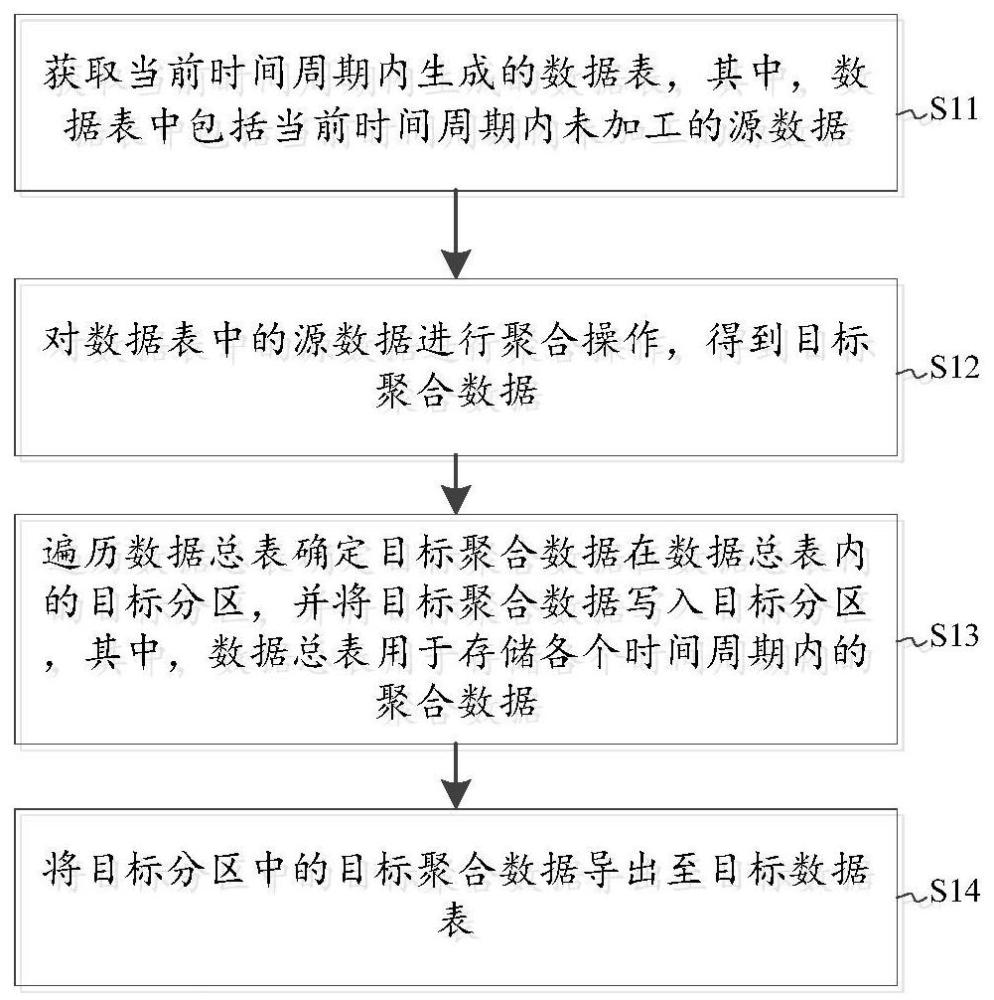
2、第一方面,本发明实施例提供了一种数据处理方法,所述方法包括:
3、获取当前时间周期内生成的数据表,其中,所述数据表中包括当前时间周期内未加工的源数据;
4、对所述数据表中的源数据进行聚合操作,得到目标聚合数据;
5、遍历数据总表确定所述目标聚合数据在数据总表内的目标分区,并将所述目标聚合数据写入所述目标分区,其中,所述数据总表用于存储各个时间周期内的聚合数据;
6、将所述目标分区中的目标聚合数据导出至目标数据表。
7、可选的,所述获取当前时间周期内生成的数据表,包括:
8、基于所述当前时间周期,查询至少一个源数据库中未加工的源数据,其中,所述源数据存储于所述源数据库内的源数据表;
9、将所述源数据存储至分布式文件系统;
10、利用预设查询语句将所述分布式文件系统中的源数据映射为所述数据表,其中,所述数据表的表结构与所述源数据对应源数据表的表结构一致。
11、可选的,所述对所述数据表中的源数据进行聚合操作,得到目标聚合数据,包括:
12、获取所述源数据对应的数据属性;
13、确定所述数据属性对应的聚合方式;
14、按照所述聚合方式对所述源数据进行聚合操作,得到所述目标聚合数据。
15、可选的,在对所述数据表中的源数据进行聚合操作,得到目标聚合数据之后,所述方法还包括:
16、检测所述数据表中源数据对应的数据量;
17、在所述数据量大于或等于预设阈值的情况下,从所述聚合总表中获取所述目标分区的相邻分区;
18、对比所述相邻分区的聚合数据与所述目标聚合数据,得到增量数据;
19、将所述增量数据存储至增量数据表。
20、可选的,在基于所述目标分区将所述聚合数据导出至目标数据表之后,所述方法还包括:
21、检测所述目标数据表的数据量是否满足预设要求;
22、在所述数据量不满足预设要求的情况下,生成告警信息。
23、可选的,所述方法还包括:
24、在所述数据量满足预设要求的情况下,对比所述目标数据表中的目标聚合数据与业务数据库中的业务数据,得到对比结果;
25、根据所述对比结果执行相应的处理操作。
26、可选的,所述根据所述对比结果执行相应的处理操作,包括:
27、在所述对比结果为所述业务数据库中不存在所述目标聚合数据的情况下,将所述目标聚合数据插入所述业务数据库;
28、在所述对比结果为所述业务数据与所述目标聚合数据不一致的情况下,利用所述目标聚合数据对所述业务数据库进行更新。
29、第二方面,本发明实施例提供了一种数据处理装置,所述装置包括:
30、获取模块,用于获取当前时间周期内生成的数据表,其中,所述数据表中包括当前时间周期内未加工的源数据;
31、聚合模块,用于对所述数据表中的源数据进行聚合操作,得到目标聚合数据;
32、存储模块,用于遍历数据总表确定所述聚合数据在数据总表内的目标分区,并将所述聚合数据写入所述目标分区,其中,所述数据总表用于存储各个各个时间周期内的聚合数据;
33、导出模块,用于基于所述目标分区将所述聚合数据导出至目标数据表。
34、第三方面,本发明实施例提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的方法。
35、第四方面,本发明实施例提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的方法。
36、本申请实施例提供的方法具有以下有益效果:
37、本申请实施例采用大数据异步导数的方式,对源数据库进行解耦;提高了数据处理的灵活性,同时可以对数据进行多次多维度的处理聚合,以及通过将聚合数据导出能够支持不同数据库类型之间的数据交互。
38、具体的,本申请实施例通过获取当前时间周期内生成的数据表,实现了定时生成数据表,从而对当前时间周期内的源数据进行聚合和导出的自动化处理,减少了手动操作的工作量和错误的可能性。同时还可以及时处理最新的数据,确保聚合和导出的数据是基于最新的源数据,并且在数据总表中存储最新的聚合数据。通过遍历数据总表确定目标聚合数据在数据总表内的目标分区,并将目标聚合数据写入目标分区,可以灵活地根据需要选择目标分区进行数据存储和管理。
39、另外,通过在数据总表中存储各个时间周期内的聚合数据,可以保留历史数据并支持历史查询。以此可以方便地追溯和分析各个时间周期内的聚合结果,为决策和分析提供依据。
技术特征:
1.一种数据处理方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述获取当前时间周期内生成的数据表,包括:
3.根据权利要求1所述的方法,其特征在于,所述对所述数据表中的源数据进行聚合操作,得到目标聚合数据,包括:
4.根据权利要求3所述的方法,其特征在于,在对所述数据表中的源数据进行聚合操作,得到目标聚合数据之后,所述方法还包括:
5.根据权利要求1所述的方法,其特征在于,在基于所述目标分区将所述聚合数据导出至目标数据表之后,所述方法还包括:
6.根据权利要求5所述的方法,其特征在于,所述方法还包括:
7.根据权利要求6所述的方法,其特征在于,所述根据所述对比结果执行相应的处理操作,包括:
8.一种数据处理装置,其特征在于,所述装置包括:
9.一种计算机设备,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机指令,所述计算机指令用于使计算机执行权利要求1至7中任一项所述的方法。
技术总结
本发明涉及计算机技术领域,公开了一种数据处理方法、装置、电子设备及存储介质,方法包括:获取当前时间周期内生成的数据表,其中,数据表中包括当前时间周期内未加工的源数据;对数据表中的源数据进行聚合操作,得到目标聚合数据;遍历数据总表确定目标聚合数据在数据总表内的目标分区,并将目标聚合数据写入目标分区,其中,数据总表用于存储各个时间周期内的聚合数据;将目标分区中的目标聚合数据导出至目标数据表。本申请实施例采用大数据异步导数的方式,对源数据库进行解耦;提高了数据处理的灵活性,同时可以对数据进行多次多维度的处理聚合,以及通过将聚合数据导出能够支持不同数据库类型之间的数据交互。
技术研发人员:徐浩
受保护的技术使用者:北京自如信息科技有限公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!