对CUDA内核的Softmax函数进行分段处理的方法及系统与流程
本公开涉及属于数据处理,具体涉及一种对cuda内核的softmax函数进行分段处理的方法及系统。
背景技术:
1、cuda内核中,softmax操作是深度学习模型中最常见的操作。在深度学习的分类任务中,数据处理网络最后的分类器往往采用softmax和crossentropy的组合。尽管当softmax和crossentropy联合使用时,其数学推导可以约简,但还是有很多场景会单独使用softmax函数。如bert的encoder每一层的attention layer中就单独使用了softmax求解attention的概率分布;gpt-2的attention的multi-head部分也单独使用了softmax等等。
2、深度学习框架中的所有计算的算子都会转化为gpu上的cuda kernel function,softmax操作也不例外。softmax作为一个被大多数网络广泛使用的算子,其cuda kernel实现高效性会影响很多网络最终的训练速度。那么如何实现一个高效的softmax cudakernel是本领域技术人员一直所追求的。因此,本领域技术人员一直期望获得一种改良的优化softmax cuda kernel。
技术实现思路
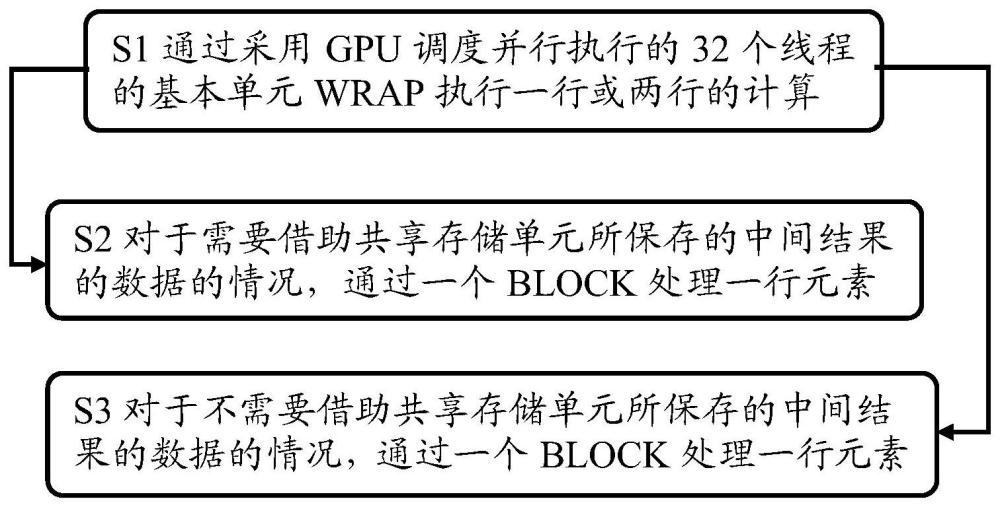
1、有鉴于此,本申请提供一种用于优化softmax cuda kernel的技术手段,该技术手段针对softmax函数进行分段处理,从而实现一种高效的softmax cuda kernel。根据本公开的一个方面,提供了一种对cuda内核的softmax函数进行分段处理的方法,包括:通过采用gpu调度并行执行的32个线程的基本单元wrap执行一行或两行的计算,从而使得每个wrap处理一行或两行元素,其中每行的reduce操作需要做wrap内的reduce操作,由此通过warpallreduce来完成wrap内各线程间的global max和global sum处理操作,其中所述warpallreduce是通过wrap级别原语shfl_xor_sync实现;以及对于需要借助共享存储单元所保存的中间结果的数据的情况,通过一个block处理一行元素,由此基于所输入的共享存储单元所保存的中间结果的数据,在block内执行reduce操作以及在block线程内进行同步操作,从而利用blockallreduce来完成block内各线程间的global max和global sum处理操作,其中所述blockallreduce是通过cub的blockreuce方法来实现。
2、根据本公开的对cuda内核的softmax函数进行分段处理的方法,还包括:对于不需要借助共享存储单元所保存的中间结果的数据的情况,通过一个block处理一行元素,由此重复重新读取中间结果的数据,在block内执行reduce操作以及在block线程内进行同步操作,从而利用blockallreduce来完成block内各线程间的global max和global sum处理操作,其中所述blockallreduce是通过cub的blockreuce方法来实现。
3、根据本公开的对cuda内核的softmax函数进行分段处理的方法,其中所述block的尺寸可以根据需要增大以便减少并行的block的数量,从而减少对高速缓存的需求,增加并行过程中命中高速缓存的概率。
4、根据本公开的对cuda内核的softmax函数进行分段处理的方法,其中所述共享存储单元按照4个字节或8个字节被划分到32而bank中,由此避免bank访问的冲突。
5、根据本公开的另一个方面,还提供了一种对cuda内核的softmax函数进行分段处理的系统,包括:wrap处理组件,通过采用gpu调度并行执行的32个线程的基本单元wrap执行一行或两行的计算,从而使得每个wrap处理一行或两行元素,其中每行的reduce操作需要做wrap内的reduce操作,由此通过warpallreduce来完成wrap内各线程间的global max和global sum处理操作,其中所述warpallreduce是通过wrap级别原语shfl_xor_sync实现;以及block处理组件,对于需要借助共享存储单元所保存的中间结果的数据的情况,通过一个block处理一行元素,由此基于所输入的共享存储单元所保存的中间结果的数据,在block内执行reduce操作以及在block线程内进行同步操作,从而利用blockallreduce来完成block内各线程间的global max和global sum处理操作,其中所述blockallreduce是通过cub的blockreuce方法来实现。
6、根据本公开的对cuda内核的softmax函数进行分段处理的系统,还包括:block处理组件对于不需要借助共享存储单元所保存的中间结果的数据的情况,通过一个block处理一行元素,由此重复重新读取中间结果的数据,在block内执行reduce操作以及在block线程内进行同步操作,从而利用blockallreduce来完成block内各线程间的global max和global sum处理操作,其中所述blockallreduce是通过cub的blockreuce方法来实现。
7、根据本公开的对cuda内核的softmax函数进行分段处理的系统,其中所述block的尺寸可以根据需要增大以便减少并行的block的数量,从而减少对高速缓存的需求,增加并行过程中命中高速缓存的概率。
8、根据本公开的对cuda内核的softmax函数进行分段处理的系统,其中所述共享存储单元按照4个字节或8个字节被划分到32而bank中,由此避免bank访问的冲突。
9、根据本公开的对cuda内核的softmax函数进行分段处理的方法及系统,实现了的softmax cuda kernel的优化,从而使得softmax对显存带宽的利用率可以接近理论上限,远高于cudnn的实现。
10、应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本申请。
技术特征:
1.一种对cuda内核的softmax函数进行分段处理的方法,包括:
2.根据权利要求1所述的对cuda内核的softmax函数进行分段处理的方法,还包括:
3.根据权利要求2所述的对cuda内核的softmax函数进行分段处理的方法,其中所述block的尺寸可以根据需要增大以便减少并行的block的数量,从而减少对高速缓存的需求,增加并行过程中命中高速缓存的概率。
4.根据权利要求1所述的对cuda内核的softmax函数进行分段处理的方法,其中所述共享存储单元按照4个字节或8个字节被划分到32而bank中,由此避免bank访问的冲突。
5.一种对cuda内核的softmax函数进行分段处理的系统,包括:
6.根据权利要求1所述的对cuda内核的softmax函数进行分段处理的系统,还包括:
7.根据权利要求1所述的对cuda内核的softmax函数进行分段处理的系统,其中所述block的尺寸可以根据需要增大以便减少并行的block的数量,从而减少对高速缓存的需求,增加并行过程中命中高速缓存的概率。
8.根据权利要求1所述的对cuda内核的softmax函数进行分段处理的系统,其中所述共享存储单元按照4个字节或8个字节被划分到32而bank中,由此避免bank访问的冲突。
技术总结
本公开涉及一种对CUDA内核的Softmax函数进行分段处理的方法,包括:通过采用GPU调度并行执行的32个线程的基本单元WRAP执行一行或两行的计算,从而使得每个WRAP处理一行或两行元素,其中每行的Reduce操作需要做WRAP内的REDUCE操作,由此通过WarpAllReduce来完成WRAP内各线程间的Global Max和Global Sum处理操作,其中所述WarpAllReduce是通过WRAP级别原语shfl_xor_sync实现;以及对于需要借助共享存储单元所保存的中间结果的数据的情况,通过一个BLOCK处理一行元素,由此基于所输入的共享存储单元所保存的中间结果的数据,在BLOCK内执行REDUCE操作以及在BLOCK线程内进行同步操作,从而利用BlockAllReduce来完成BLOCK内各线程间的Global Max和Global Sum处理操作,其中所述BlockAllReduce是通过Cub的BlockReuce方法来实现。
技术研发人员:柳俊丞,郭冉,郑泽康,谢暄
受保护的技术使用者:北京一流科技有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!