一种用于LLM模型的数据训练方法及存储介质与流程
本发明涉及大语言模型训练,特别是涉及一种用于llm模型的数据训练方法及存储介质。
背景技术:
1、大语言模型llm是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义;大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等。目前,随着chatgpt的迅速发展,使用chatgpt或其它大语言模型进行问答获取到想要的问题或答案的需求越来越多,如何对大语言模型进行训练或引导使得大语言模型输出想要的答案至关重要。
技术实现思路
1、针对上述技术问题,本发明采用的技术方案为:一种用于llm模型的数据训练方法,所述方法包括如下步骤:
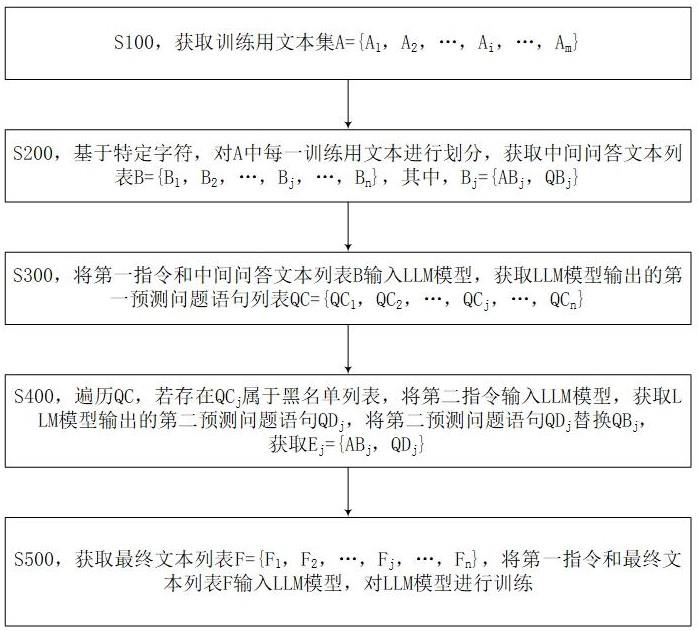
2、s100,获取训练用文本集a={a1,a2,…,ai,…,am},ai是第i条训练用文本,i的取值范围是1到m,m是训练用文本的数量,所述训练用文本ai包括目标领域中关于同一预设场景的p个第一语句和p+1个第二语句,其中,ai中第q个第二语句是根据第q个第一语句提出的问题语句,第q个第三语句为关于预设场景的陈述语句,且同时为第q-1个第二语句的回答语句,q的取值范围是1到p,且当q=1时,第q个第一语句为关于预设场景的陈述语句;所述预设场景为所述目标领域中多个指定场景中的一个;
3、s200,基于特定字符,对a中每一训练用文本进行划分,获取中间问答文本列表b={b1,b2,…,bj,…,bn},bj是第j个中间问答文本,j的取值范围是1到n,n是训练用文本集a中所有训练用文本进行划分后的中间问答文本的数量;
4、其中,bj={abj,qbj},abj是第j个中间问答文本bj包含的回答语句,qbj是第j个中间问答文本bj包含的问题语句,qbj是基于abj提出的问题语句;
5、s300,将第一指令和中间问答文本列表b输入llm模型,获取llm模型输出的第一预测问题语句列表qc={qc1,qc2,…,qcj,…,qcn},所述第一指令为:基于abj生成问题语句;qcj是llm模型输出的abj对应的第一预测问题语句;
6、s400,遍历qc,若存在qcj属于黑名单列表,将第二指令输入llm模型,获取llm模型输出的第二预测问题语句qdj,将第二预测问题语句qdj替换qbj,获取ej={abj,qdj};
7、所述黑名单列表为预设的无意义语句列表;
8、所述第二指令为:基于abj和k条领域摘要语句生成问题语句;所述领域摘要语句是目标领域内的预设语句;
9、s500,获取最终文本列表f={f1,f2,…,fj,…,fn},将第一指令和最终文本列表f输入llm模型,对llm模型进行训练;其中,fj是第j个最终文本,若qcj属于黑名单列表,fj=ej;若qcj不属于黑名单列表,fj=bj。
10、一种非瞬时性计算机可读存储介质,所述存储介质中存储有至少一条指令或至少一段程序,所述至少一条指令或所述至少一段程序由处理器加载并执行以实现上述方法。
11、本发明至少具有以下有益效果:
12、综上,获取训练用文本集,基于特定字符,对每一训练用文本进行划分,获取中间问答文本列表,将第一指令和中间问答文本列表b输入llm模型,获取llm模型的输出的第一预测问题语句列表,遍历第一预测问题语句列表,若存在第一预测问题语句属于黑名单列表,将第二指令输入llm模型,获取llm模型输出的第二预测问题语句,将第二预测问题语句替换问题语句,获取最终文本列表,将第一指令和最终文本列表输入llm模型,对llm模型进行训练,通过对llm模型输出的第一预测问题语句进行是否属于黑名单列表的判断,使得获取到合理的最终文本列表,对llm模型进行训练,从而达到引导llm模型的目的,使得llm输出目标领域相关的、有意义的问题。
技术特征:
1.一种用于llm模型的数据训练方法,其特征在于,所述方法包括如下步骤:
2.根据权利要求1所述的用于llm模型的数据训练方法,其特征在于,s500具体包括如下步骤:
3.根据权利要求1所述的用于llm模型的数据训练方法,其特征在于,还包括:
4.根据权利要求2所述的用于llm模型的数据训练方法,其特征在于,还包括:
5.根据权利要求4所述的用于llm模型的数据训练方法,其特征在于,第b个构造样本列表kb通过如下步骤获取:
6.根据权利要求5所述的用于llm模型的数据训练方法,其特征在于,d1,d2,…,db,…,dc满足预设比例要求。
7.根据权利要求5所述的用于llm模型的数据训练方法,其特征在于,c≤3。
8.根据权利要求7所述的用于llm模型的数据训练方法,其特征在于,c=2。
9.一种非瞬时性计算机可读存储介质,所述存储介质中存储有至少一条指令或至少一段程序,其特征在于,所述至少一条指令或所述至少一段程序由处理器加载并执行以实现如权利要求1-8中任意一项的所述方法。
技术总结
本发明提供了一种用于LLM模型的数据训练方法及存储介质,涉及大语言模型训练技术领域,所述方法包括:获取训练用文本集,基于特定字符,对每一训练用文本进行划分,获取中间问答文本列表,将第一指令和中间问答文本列表输入LLM模型,获取LLM模型的输出的第一预测问题语句列表,若存在第一预测问题语句属于黑名单列表,将第二指令输入LLM模型,获取LLM模型输出的第二预测问题语句,将第二预测问题语句替换问题语句,获取最终文本列表,将第一指令和最终文本列表输入LLM模型,对LLM模型进行训练,从而达到引导LLM模型的目的。
技术研发人员:靳雯,于伟,王全修,石江枫,赵洲洋,吴凡
受保护的技术使用者:北京睿企信息科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!