一种语言模型的训练方法及装置与流程
本申请涉及人工智能,尤其涉及一种语言模型的训练方法及装置。
背景技术:
1、大语言模型是一种基于深度学习的自然语言处理技术,这些模型通常包含数十亿甚至数千亿个参数,可以在大规模的文本数据上进行预训练和微调,从而实现多种自然语言理解和生成的任务。
2、但是,现有技术中,大语言模型需要大量的计算资源来进行训练和推理,这会带来巨大的成本和环境影响,加大了大语言模型的训练和优化难度,一定程度上会阻碍小型研究实验室和独立研究人员在大型语言模型领域的研究进展,限制了该领域的创新和多样性。
技术实现思路
1、有鉴于此,本申请实施例提供了一种语言模型的训练方法及装置,能通过一种相对高保真、高准确度的方式,降低计算资源的同时,使小型的语言模型可以达到大语言模型的效果。
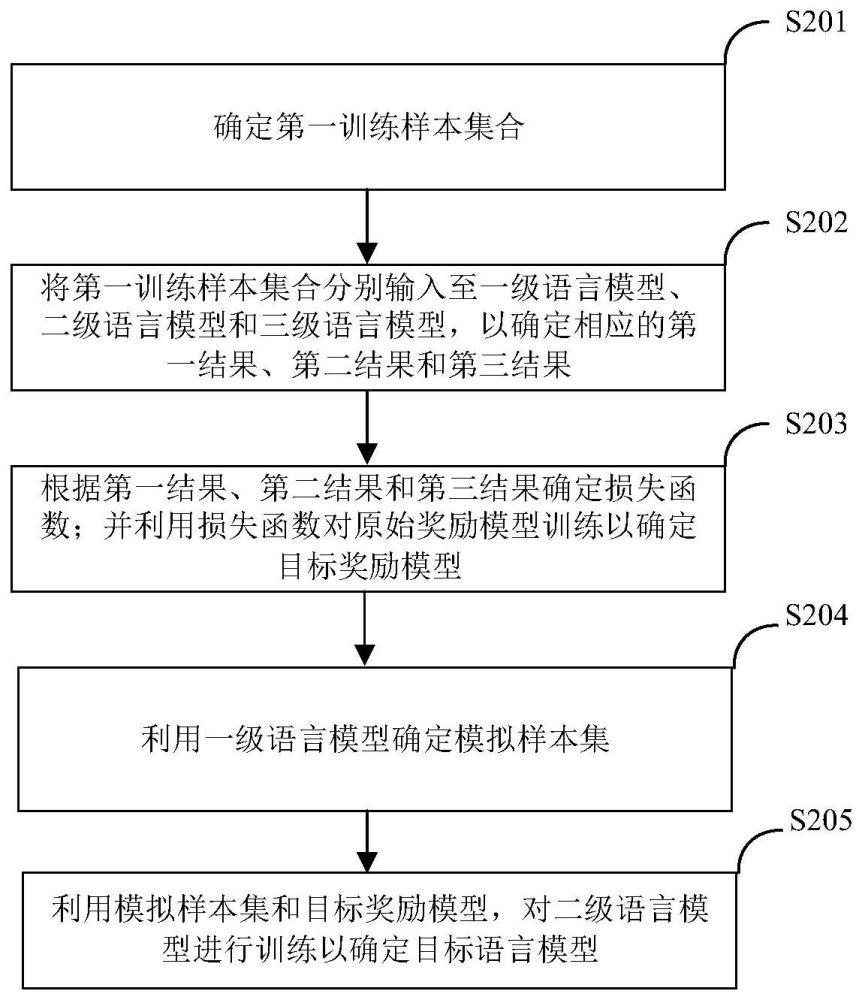
2、本申请实施例的第一方面,提供了一种语言模型的训练方法,该方法包括:
3、确定第一训练样本集合;
4、将第一训练样本集合分别输入至一级语言模型、二级语言模型和三级语言模型,以确定相应的第一结果、第二结果和第三结果;
5、根据第一结果、第二结果和第三结果确定损失函数;并利用损失函数对原始奖励模型训练以确定目标奖励模型;
6、利用一级语言模型确定模拟样本集;
7、利用模拟样本集和目标奖励模型,对二级语言模型进行训练以确定目标语言模型。
8、本申请实施例的第二方面,提供了一种语言模型的训练装置,包括:
9、第一训练样本集合确定模块,用于确定第一训练样本集合;
10、结果确定模块,用于将第一训练样本集合分别输入至一级语言模型、二级语言模型和三级语言模型,以确定相应的第一结果、第二结果和第三结果;
11、目标奖励模型确定模块,用于根据第一结果、第二结果和第三结果确定损失函数;并利用损失函数对原始奖励模型训练以确定目标奖励模型;
12、模拟样本集确定模块,用于利用一级语言模型确定模拟样本集;
13、目标语言模型确定模块,用于利用模拟样本集和目标奖励模型,对二级语言模型进行训练以确定目标语言模型。
14、本申请实施例的第三方面,提供了一种电子设备,包括存储器、处理器以及存储在存储器中并且可在处理器上运行的计算机程序,该处理器执行计算机程序时实现上述方法的步骤。
15、本申请实施例的第四方面,提供了一种可读存储介质,该可读存储介质存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。
16、本申请实施例与现有技术相比存在的有益效果是:本申请实施例通过结合大语言文本生成模型更加准确的优势,生成数据集样本用于新的小型文本生成模型的训练,可以降低小型文本生成模型所需数据源的采集难度,利用奖励模型加入奖励机制,将大语言模型的生成的数据作为正向反馈,否则为负向反馈,充分利用大语言模型的生成文本准确的优势,节省人工标注成本,提升小型文本生成模型的学习能力和泛化能力。同时,基于大语言文本生成模型输出的数据集作为训练样本,实现将大语言文本生成模型的知识到小型文本生成模型的迁移,可以有效缩短小型文本生成模型训练需要的时间,减少计算资源的需求,提高了模型的可用性和可扩展性。
技术特征:
1.一种语言模型的训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,在将所述第一训练样本集合分别输入至一级语言模型、二级语言模型和三级语言模型之前,还包括:
3.根据权利要求1所述的方法,其特征在于,所述根据所述第一结果、所述第二结果和所述第三结果确定损失函数包括:
4.根据权利要求3所述的方法,其特征在于,所述基于所述第一分数、所述第二分数和所述第三分数建立所述损失函数包括:
5.根据权利要求1所述的方法,其特征在于,所述第一训练样本集合中包括历史询问文本;所述利用所述一级语言模型确定模拟样本集包括:
6.根据权利要求1~5任意一项所述的方法,其特征在于,所述利用所述模拟样本集和目标奖励模型,对所述二级语言模型进行训练以确定目标语言模型包括:
7.根据权利要求6所述的方法,其特征在于,所述利用预设的梯度更新函数和所述匹配分数,调整所述二级语言模型的模型参数以进行训练包括:
8.一种语言模型的训练装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器以及存储在所述存储器中并且可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7中任一项所述方法的步骤。
10.一种可读存储介质,所述可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述方法的步骤。
技术总结
本申请提供了一种语言模型的训练方法及装置。该方法包括:确定第一训练样本集合;将第一训练样本集合分别输入至一级语言模型、二级语言模型和三级语言模型,以确定相应的第一结果、第二结果和第三结果;根据第一结果、第二结果和第三结果确定损失函数;并利用损失函数对原始奖励模型训练以确定目标奖励模型;利用一级语言模型确定模拟样本集;利用模拟样本集和目标奖励模型,对二级语言模型进行训练以确定目标语言模型。本申请利用奖励模型加入奖励机制,将大语言模型的生成的数据作为正向反馈,充分利用大语言模型的生成文本准确的优势,基于大语言模型输出的数据集作为训练样本,实现将大语言模型的知识到小型文本生成模型的迁移。
技术研发人员:徐琳,王芳,暴宇健
受保护的技术使用者:深圳须弥云图空间科技有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!