一种基于KPCA-ACFSFDP的海量数据清洗方法与流程
本发明涉及数据分析与处理领域,主要是一种对能源发电行业下实时状态数据的清洗方法。
背景技术:
1、对于海量数据的清洗,主要是完成有用数据的提取与数据的分类,满足工作人员不同的需要。目前的海量数据清洗技术主要有基于函数依赖的数据清洗技术、基于相似重复数据的清洗技术等,相关技术能够实现对大量数据的基本清洗。但是能源发电行业下的数据数量大种类多,传统的数据清洗方法无法获取真实的大样本信息,当信息间存在偏差时对清洗的结果也会产生影响。随着科技的进步与发展,人工智能技术越来越多的被应用到能源行业下的数据清洗中。在数据清洗的过程中,通常的方法对数据进行降维以及根据不同的特征对数据进行聚合,实现数据的完整清洗。常见的数据降维方法有主成分分析法、因子分析法等,现有技术只能在目标数据是线性分布的情况下才能得到较好的效果。能源发电行业得到的数据并不是简单的呈线性分布,故采用常见的数据降维方法不能更多地保留全局特征。常见的数据聚类方法有基于划分的聚类方法、基于层次的聚类方法以及基于密度峰值聚类方法等,现有的相关技术并不能根据数据的分布进行自适应性的参数调整,从而构建的模型没有自适应性的能力。
2、在海量数据清洗的过程中,重要的是对数据的特征更多的保留,并且能够针对数据的特有特征与规律进行参数的自适应调整。针对以上问题提出了一种基于kpca-acfsfdp的海量数据清洗方法,通过采用kpca降维方法对海量数据进行降维,并更多地保留数据的全局特征,利用自适应的cfsfdp方法对处理后的数据进行聚类,提高数据的清洗质量。
技术实现思路
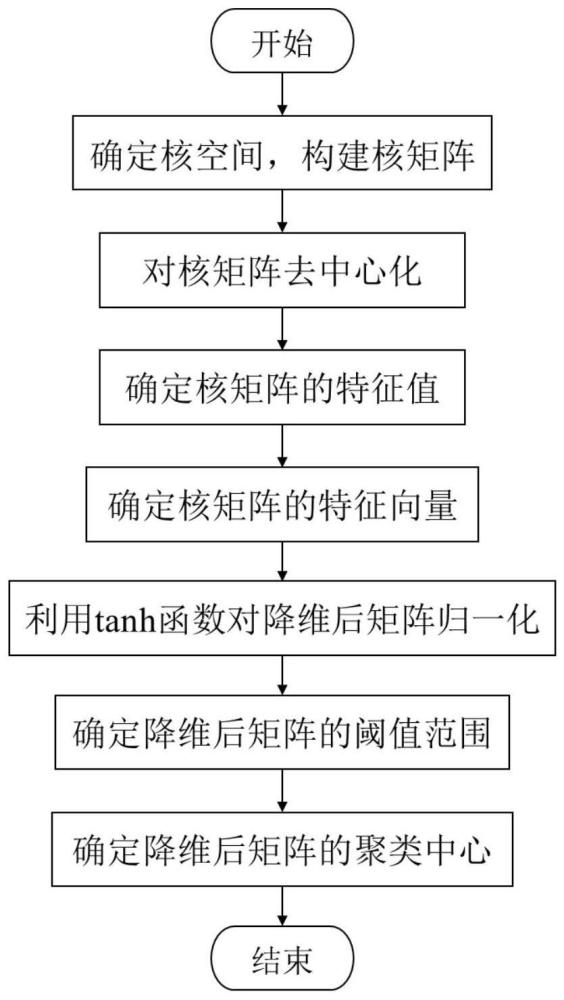
1、针对上述现有技术中存在的问题,本发明要解决的技术问题是提供一种基于kpca-acfsfdp的海量数据清洗方法,其具体流程如图1所示。
2、技术方案实施步骤如下:
3、(1)将数据映射到高阶特征空间,得到核矩阵φ(x):
4、
5、式中,x为原始数据构成的数据集,表示为m表示数据集x的行数,n表示数据集x的列数,xm,n表示原始数据集x在m行n列上对应的值,φ(xm,n)表示数据xm,n经过核函数的映射,对应得到的映射后的数据。
6、(2)对φ(x)进行中心化操作,确定中心化后的核矩阵φ'(x):
7、
8、式中,表示第m行对应的平均值,表示第1行对应的平均值。
9、(3)确定核矩阵φ'(x)的协方差矩阵a:
10、
11、式中,(φ'(x))t表示φ'(x)的转置矩阵。确定a对应的特征值为α1,α2,…,αm,确定a对应的特征向量为η1,η2,…,ηm。确定矩阵其中矩阵g表示为g=[η1,η2,…,ηn]。通过利用固定的降维阶数r对矩阵gagt进行选取操作,确定新的矩阵g'。由于确定降维阶数为r,故对矩阵gagt的前r列进行截取组合,从而确定新得到的矩阵g'=[η'1,η'2,…,η'r]。
12、(4)确定降维后的矩阵结果z:
13、z=g'φ(x)
14、(5)确定矩阵z的高斯核密度ρi:
15、
16、式中,ρi表示数据点i对应的高斯核密度,i与j分别表示数据点i与数据点j,dij表示数据点i与数据点j之间的欧式距离,du表示全局的截断距离。
17、(6)确定矩阵z中数据点i与数据集中其他高集中局部密度数据点之间的最近距离li:
18、
19、(7)确定矩阵的聚类判定中心o:
20、
21、式中,θi表示ρi的归一化值,表示为表示li归一化后得到的值,表示为根据数据集o的分布范围,设定一个合适的阈值,自动选择数据集的聚类中心,从而完成数据的清洗。
22、本发明比现有技术具有的优点:
23、(1)该发明通过引入核主成分分析方法,实现了海量数据的降维和特征提取,并能够保留数据更多的全局特征,提升了数据降维操作的准确性。
24、(2)该发明改善了传统数据清洗过程中,由于传统数据聚类方法缺乏自适应性所产生的效率低速度慢问题,有效的解决了人为选取聚类中心带来的干扰因素,提升了数据自适应聚类的精确度。
技术特征:
1.一种基于kpca-acfsfdp的海量数据清洗方法,其特征在于:(1)将数据映射到高阶特征空间,得到核矩阵φ(x);(2)对φ(x)进行中心化操作,确定中心化后的核矩阵φ'(x);(3)确定核矩阵φ'(x)的协方差矩阵a;(4)确定降维后的矩阵结果z;(5)确定矩阵z的高斯核密度;(6)确定矩阵z中数据点i与数据集中其他高集中局部密度数据点之间的最近距离li;(7)确定矩阵的聚类判定中心o;具体包括以下七个步骤:
技术总结
本发明涉及基于KPCA‑ACFSFDP的海量数据清洗方法,是一种对能源发电行业下实时状态数据的清洗方法,属于数据分析与处理领域,其特征在于采用如下步骤:(1)将数据映射到高阶特征空间,得到核矩阵;(2)确定中心化后的核矩阵;(3)确定中心化后的核矩阵的协方差矩阵;(4)确定降维后的矩阵结果;(5)确定矩阵的高斯核密度;(6)确定矩阵中数据点与数据集中其他高集中局部密度数据点之间的最近距离;(7)确定矩阵的聚类判定中心。该发明通过引入核主成分分析方法,保留数据更多的全局特征,提升了数据降维操作的准确性。同时该方法有效的解决了人为选取聚类中心带来的干扰因素,提升了数据自适应聚类的精确度。
技术研发人员:胡周达,梁小荣,钟漍标,叶德云
受保护的技术使用者:广东省能源集团贵州有限公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!