一种从逻辑标签直接学习标签分布的标签分布学习方法
本发明涉及一种学习方法,具体涉及一种从逻辑标签直接学习标签分布的标签分布学习方法,属于标签分布学习方法。
背景技术:
1、目前的标签增强算法的目标函数基本上可以用一个公式来概括:
2、
3、其中x,y分别为特征矩阵与逻辑标签矩阵,||·||f表示一个矩阵的frobenius范数,w矩阵建立了一个从特征空间到标签空间的映射,φ(xw,x)对样本的高维几何结构进行了挖掘与建模,以支撑标签分布的恢复。在关于目标函数的优化过程结束后,对xw进行归一化,就得到了原始数据的重构标签分布。(别人方法的大致技术路线)
4、缺点1:首先,衡量xw与y之间的距离是不合理的,因为逻辑标签的可能值只有0与1,因此在线性映射xw与frobenius范数的共同作用下,不同标签的描述程度会趋同。而这等效于结果从标签分布退化到了逻辑标签,这是我们所不希望看到的。此外,frobenius范数也并非描述特征空间与标签空间距离的最佳指标。
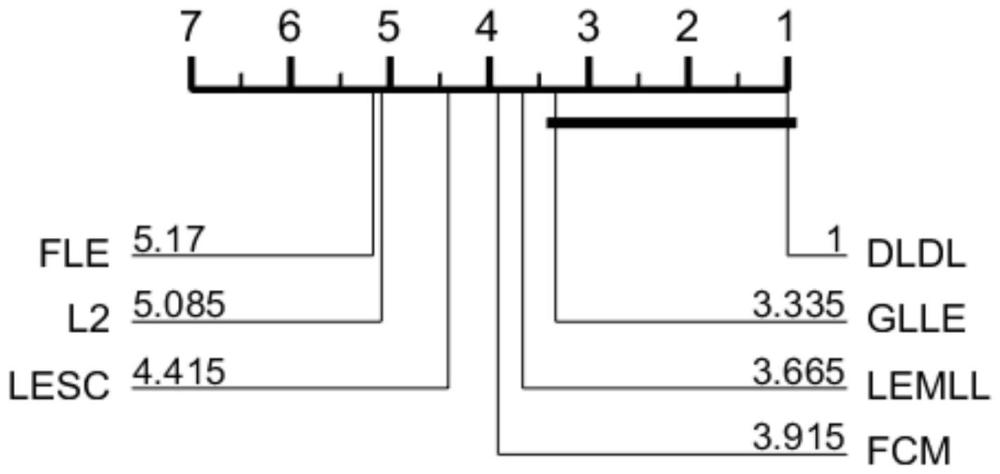
5、缺点2:上述模型的目标函数中并未直接考虑标签分布的约束关系,即其中d为标签分布向量,l为标签个数。该约束的含义是,标签分布向量中各元素和为1,且逻辑标签为0处,对应标签分布必为0;逻辑标签为1处,对应标签分布可从0-1的实数中任取。尽管对xw进行归一化可以解决标签分布的范围问题,但是采用归一化会带来一个新问题:对一个逻辑标签某位置为0的样本的对应位置打上正的标签分布。例如在图1中,在逻辑标签中,human对应的值为0,代表该图中不存在人这一元素。如果恢复的标签分布中human对应的值为正,代表该图中存在部分人的元素,这是十分不合理的。
6、缺点3:标签增强算法的设计初衷,是解决标签分布学习算法中带标签分布数据难获取的问题,但是大多数学者仅仅在单一地研究标签分布学习算法或标签增强算法,而没有考虑到将二者有机结合,以打造一个一体化的、从逻辑标签直接学习标签分布的算法。因此,迫切的需要一种新的方案解决上述技术问题。
技术实现思路
1、本发明正是针对现有技术中存在的问题,提供一种从逻辑标签直接学习标签分布的标签分布学习方法,该技术方案的目的是利用改进后的标签增强算法,从易于获得的逻辑标签重构出标签分布,并在此基础之上结合标签分布学习算法,达到直接从逻辑标签学习标签分布的效果。
2、为了实现上述目的,本发明的技术方案如下,一种从逻辑标签直接学习标签分布的标签分布学习方法,所述方法包括以下步骤:
3、步骤1:初始化标签分布预测权重矩阵w与标签分布恢复矩阵d
4、步骤2:利用梯度下降法更新w
5、步骤3:利用二次规划工具更新d
6、步骤4:交替重复步骤2、3直至更新收敛或达到最大训练次数,并返回训练后的w与d,
7、利用w矩阵完成标签分布的预测。
8、作为本发明的一种改进,步骤1具体如下:
9、1)初始化w为单位矩阵
10、2)初始化d:
11、i)根据各个训练样本的逻辑标签的正负,构建每个标签所对应的样本集(若某样本的某逻辑标签为正,则将其加入该标签的样本集);
12、ii)从各个标签的样本集中选出所有拥有最少正标签的样本作为该标签的目标样本集;
13、iii)为各个标签生成表示特征向量,其值为该标签对应目标样本集中所有目标样本特征向量的平均;
14、iv)令其中dij为d矩阵的第i行第j列,xi为第i个样本的特征向量,rj为第j个标签的表示特征向量,||·||2为向量的2范数,lji为第i个样本的第j个逻辑标签值。
15、作为本发明的一种改进,步骤2具体如下:
16、1)本模型优化目标函数对w求梯度,得
17、
18、其中t(w)为整体优化目标函数中取出与w有关的项组成的函数,wkj为w矩阵中第k行第j列的元素,xik为x矩阵中第i行第k列的元素,dij为d矩阵中第i行第j列的元素,exp()为指数运算,γ为模型参数。
19、2)将此梯度传入bfgs梯度下降工具,更新w矩阵。
20、作为本发明的一种改进,步骤3具体如下:
21、1)本模型优化目标函数对d求梯度,得
22、
23、其中t(d)为整体优化目标函数中取出与d有关的项组成的函数,dij为d矩阵中第i行第j列的元素,pij为预测矩阵p中第i行第j列的元素,ln()为对数运算,α、β、τ均为模型参数,g为本算法根据特征矩阵x生成的图矩阵,b、φ均为中间过程矩阵。
24、2)将此梯度传入bfgs梯度下降工具,更新d矩阵
25、3)列出二次规划式:
26、
27、
28、其中分别为b、d、φ、y矩阵向量化后得到的向量,∑为由g矩阵组成的对角矩阵,τ为模型参数,0nc为内部元素全为0的n*c矩阵,c为标签个数,n为样本个数。
29、4)利用二次规划工具求解此问题,更新b矩阵
30、5)φ=φ+τ(b-d),τ=min(ρτ,τmax),其中min()为取最小值运算,ρ、τmax均为模型参数
31、6)重复步骤1)2)3)4)5),直至‖b-d‖∞≤10-3,其中‖·‖∞意为取矩阵的最大元素
32、7)令d=b,完成对d的更新。
33、相对于现有技术,本发明具有如下优点,1)该技术方案提出了一种将标签增强与标签分布学习技术相结合的、能从逻辑标签直接学习标签分布的标签分布学习方法;2)不使用传统标签增强模型中的用frobenius范数衡量xw与y(逻辑标签)距离的项,而是采用kl散度衡量xw与d(算法恢复的标签分布)之间的距离;3)该方案额外考虑了对标签分布矩阵的约束(即其中di、yi分别为恢复的标签分布矩阵d与逻辑标签矩阵y的第i行,0为内部元素全为0的向量,为d矩阵的第i行第l列元素),并将其纳入模型约束项,使模型产出的结果更加合理;4)大量实验证明,我们的算法在标签增强与标签分布学习方面均优于一众对比算法,足以说明我们算法在这两方面的优越性。
技术特征:
1.一种从逻辑标签直接学习标签分布的标签分布学习方法,其特征在于,所述方法包括以下步骤:
2.根据权利要求1所述的从逻辑标签直接学习标签分布的标签分布学习方法,其特征在于,步骤1具体如下:
3.根据权利要求2所述的从逻辑标签直接学习标签分布的标签分布学习方法,其特征在于,步骤2具体如下:
4.根据权利要求3所述的从逻辑标签直接学习标签分布的标签分布学习方法,其特征在于,步骤3具体如下:
技术总结
本发明涉及一种从逻辑标签直接学习标签分布的标签分布学习方法,所述方法包括以下步骤:步骤1:初始化标签分布预测权重矩阵W与标签分布恢复矩阵D;步骤2:利用梯度下降法更新W;步骤3:利用二次规划工具更新D;步骤4:交替重复步骤2、3直至更新收敛或达到最大训练次数,并返回训练后的W与D,利用W矩阵完成标签分布的预测;该方案额外考虑了对标签分布矩阵的约束(即其中d<subgt;i</subgt;、y<subgt;i</subgt;分别为恢复的标签分布矩阵D与逻辑标签矩阵Y的第i行,0为内部元素全为0的向量,为D矩阵的第i行第l列元素),并将其纳入模型约束项,使模型产出的结果更加合理。
技术研发人员:贾育衡,唐佳蔚
受保护的技术使用者:东南大学
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!