一种对话处理方法及系统与流程
本发明涉及人机交互的,特别是涉及一种对话处理方法及系统
背景技术:
1、人机对话系统通过自然语言处理技术分析用户会话,生成合适的回答或执行恰当的动作。当前,人机对话系统被广泛应用于智能客服、个人助手和社交聊天等领域,极大便利了人们的生活。
2、为了确保机器在对话过程中能与用户的主题保持一致,绝大多数的对话系统首先会通过意图识别模块确定用户输入的主题。意图识别模块本质是一个文本分类器,首先根据对话系统关心的领域预设所有可能的类别,然后对意图识别模块进行训练,使其能对用户的输入输出预设类别中的一种。
3、然而在实际中用户的输入很可能包含多个意图。比如在面向医疗的对话系统中,用户的输入可能是“糖尿病能吃减肥药吗,能治愈吗?”。这句话既包含了意图“药品效用”,也包含了意图“疾病治疗预期”。系统需要同时检测到以上两种意图,才能获得完整的回复。
4、针对上述问题,目前主流的解决方法是,训练一个多标签的意图识别模块,该模块对用户的输入判断多个可能的类别,而这种方式存在系统切换成本和风险较高、需要构建多标签的训练数据集,获取足够多的高质量多标签数据较难、简单的做多标签分类可能无法获得理想的效果。
5、因此,提供一种成本风险较低、无需获取足够多的多标签数据且有效的对话处理方法及系统是本领域技术人员亟待解决的问题。
技术实现思路
1、本发明的目的在于提供一种对话处理方法及系统,该方法逻辑清晰,安全、有效、可靠且操作简便,能有效降低成本和风险,无需获取足够多的多标签数据。
2、基于以上目的,本发明提供的技术方案如下:
3、一种对话处理方法,包括如下步骤:
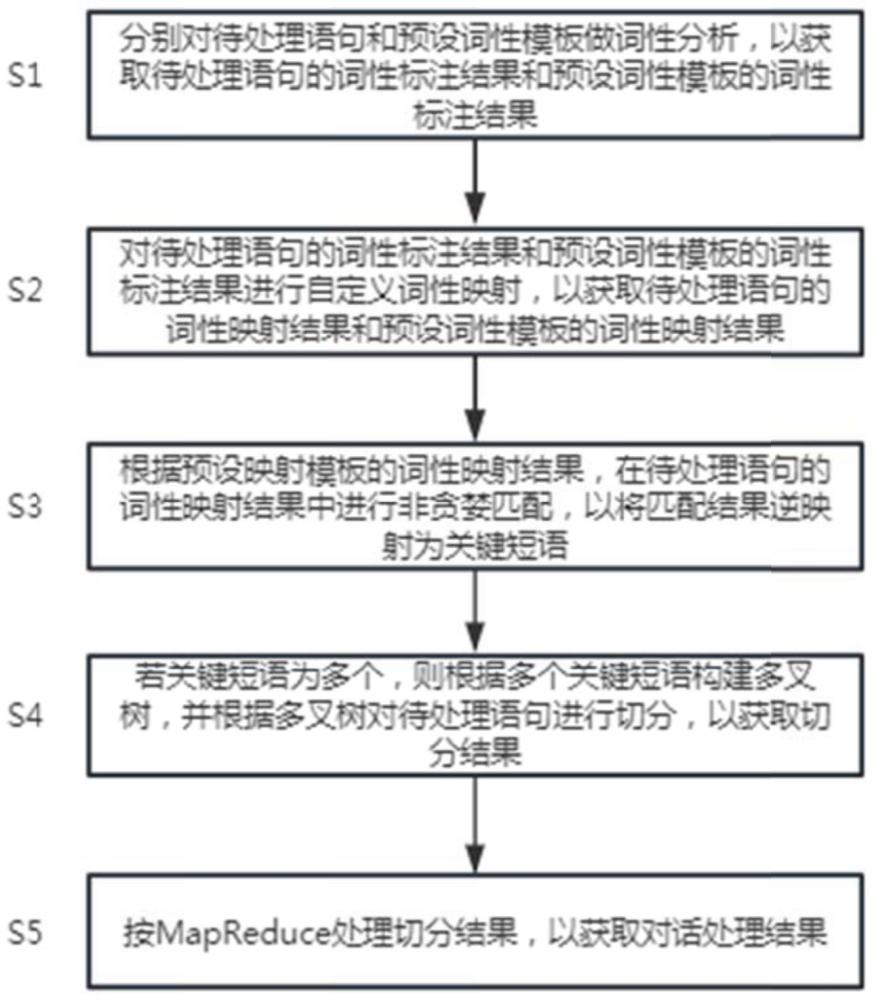
4、分别对待处理语句和预设词性模板做词性分析,以获取待处理语句的词性标注结果和预设词性模板的词性标注结果;
5、对所述待处理语句的词性标注结果和所述预设词性模板的词性标注结果进行自定义词性映射,以获取待处理语句的词性映射结果和预设词性模板的词性映射结果;
6、根据所述预设映射模板的词性映射结果,在所述待处理语句的词性映射结果中进行非贪婪匹配,以将匹配结果逆映射为关键短语;
7、若所述关键短语为多个,则根据多个所述关键短语构建多叉树,并根据所述多叉树对所述待处理语句进行切分,以获取切分结果;
8、按mapreduce处理所述切分结果,以获取对话处理结果。
9、优选地,对待处理语句的所述词性标注结果和所述预设词性模板的词性标注结果进行自定义词性映射,以获取待处理语句的词性映射结果和预设词性模板的词性映射结果,包括如下步骤:
10、定义词性标注集到自定义集合的映射关系;
11、将所述待处理语句的词性标注结果和所述预设词性模板的词性标注结果按已定义的映射关系进行自定义词性映射,以获取待处理语句的词性映射结果和预设词性模板的词性映射结果;
12、其中,所述词性标注集包括:所述待处理语句的词性标注结果和所述预设词性模板的词性标注结果的集合。
13、优选地,所述根据所述预设映射模板的词性映射结果,在所述待处理语句的词性映射结果中进行非贪婪匹配,以将匹配结果逆映射为关键短语之后,还包括如下步骤:
14、判断所述关键短语的数量;
15、若所述关键短语为零个,则按mapreduce处理所述待处理语句,作为所述对话处理结果;
16、若所述关键短语为一个,则按mapreduce处理所述关键短语,作为所述对话处理结果。
17、优选地,所述根据多个所述关键短语构建多叉树,包括如下步骤:
18、以位于所述待处理语句中的所述关键短语之前的名词作为根节点;
19、依次将所有所述关键短语作为所述根节点的子节点;
20、以所述待处理语句中的句末标点作为所述多叉树的叶子节点。
21、优选地,所述根据所述多叉树对所述待处理语句进行切分,以获取切分结果,包括如下步骤:
22、根据所述多叉树,按深度优先遍历算法对所述待处理语句进行切分,以获取切分结果。
23、优选地,所述按mapreduce处理所述切分结果,以获取对话处理结果,包括如下步骤:
24、在map阶段,通过单标签意图识别算法对所述切分结果进行意图分类,以获取分类结果;
25、在reduce阶段,将所述分类结果通过自然语言生成算法,生成所述对话处理结果。
26、一种对话处理系统,包括:
27、词性分析模块,用于分别对待处理语句和预设词性模板做词性分析,以获取待处理语句的词性标注结果和预设词性模板的词性标注结果;
28、词性映射模块,用于对所述待处理语句的词性标注结果和所述预设词性模板的词性标注结果进行自定义词性映射,以获取待处理语句的词性映射结果和预设词性模板的词性映射结果;
29、关键短语模块,用于根据所述预设映射模板的词性映射结果,在所述待处理语句的词性映射结果中进行非贪婪匹配,以将匹配结果逆映射为关键短语;
30、切分模块,用于若所述关键短语为多个,则根据多个所述关键短语构建多叉树,并根据所述多叉树对所述待处理语句进行切分,以获取切分结果;
31、对话处理模块,用于按mapreduce处理所述切分结果,以获取对话处理结果。
32、本发明公开了一种对话处理方法,是通过对待处理语句做词性分析,得到待处理语句的词性标注结果,同时对预设词性模板做词性分析,得到预设词性模板的词性标注结果;对待处理语句的词性标注结果和预设词性模板的词性标注结果进行自定义词性映射,从而得到待处理语句的词性映射结果和预设词性模板的词性映射结果;根据预设映射模板的词性映射结果,在待处理语句的词性映射结果中进行非贪婪匹配,将由非贪婪匹配的匹配结果逆映射为关键短语;此时,进行判断,如果关键短语有多个,则根据多个关键短语构建多叉树,并根据多叉树对待处理语句进行切分,从而获得切分结果;按照mapreduce对切分结果进行处理,从而获取对话处理结果。
33、相比于现有技术,本发明成本风险较低,且可以在不更换意图识别模块,不对意图数据做重新标注和训练的基础上,实现多标签意图的准确分类,完成最终的系统回复。
34、本发明还公开了一种对话处理系统,由于与该方法解决相同的技术问题,属于相同的技术构思,理应具有相同的有益效果,在此不再赘述。
技术特征:
1.一种对话处理方法,其特征在于,包括如下步骤:
2.如权利要求1所述的对话处理方法,其特征在于,对待处理语句的所述词性标注结果和所述预设词性模板的词性标注结果进行自定义词性映射,以获取待处理语句的词性映射结果和预设词性模板的词性映射结果,包括如下步骤:
3.如权利要求1所述的对话处理方法,其特征在于,所述根据所述预设映射模板的词性映射结果,在所述待处理语句的词性映射结果中进行非贪婪匹配,以将匹配结果逆映射为关键短语之后,还包括如下步骤:
4.如权利要求1所述的对话处理方法,其特征在于,所述根据多个所述关键短语构建多叉树,包括如下步骤:
5.如权利要求4所述的对话处理方法,其特征在于,所述根据所述多叉树对所述待处理语句进行切分,以获取切分结果,包括如下步骤:
6.如权利要求1所述的对话处理方法,其特征在于,所述按mapreduce处理所述切分结果,以获取对话处理结果,包括如下步骤:
7.一种对话处理系统,其特征在于,包括:
技术总结
本发明提供了一种对话处理方法及系统,方法包括如下步骤:分别对待处理语句和预设词性模板做词性分析,以获取待处理语句的词性标注结果和预设词性模板的词性标注结果;对待处理语句的词性标注结果和预设词性模板的词性标注结果进行自定义词性映射,以获取对应的词性映射结果;根据预设映射模板的词性映射结果,在待处理语句的词性映射结果中进行非贪婪匹配,以将匹配结果逆映射为关键短语;若关键短语为多个,则根据多个关键短语构建多叉树,并根据多叉树对待处理语句进行切分,按MapReduce处理切分结果,得到对话处理结果。该方法成本风险较低,且可以在不更换意图识别模块,实现多标签意图的准确分类。该系统具有相同有益效果。
技术研发人员:马源,王晓龙,李国庆,刘永军,谢喜林,陈涛
受保护的技术使用者:智慧眼科技股份有限公司
技术研发日:
技术公布日:2024/2/1
- 还没有人留言评论。精彩留言会获得点赞!