一种基于对抗学习的海关进出口商品税率检测方法
本发明涉及自然语言处理,具体涉及一种基于对抗学习的海关进出口商品税率检测方法。
背景技术:
1、海关商品税率检测是指对海关进出口商品进行分类,根据商品类别对其进行征税。由于海关商品数据的复杂性和特殊性,导致分类模型在海关进出口商品税率检测任务中表现较差。通过使用对比学习和对抗训练,可以加强模型的泛化能力,减轻数据不平衡问题的影响,实现海关商品税率预测准确的提升。
2、自然语言处理技术使计算机能够对文本信息进行理解、分析、处理以及生成,因此将自然语言处理技术应用在海关税率检测任务中,可以有效提高海关税率检测的准确性和效率,为海关业务提供智能化技术支持。但海关进出口商品申报文本中,由于不同类别的商品数量不同,导致部分词语高频出现,模型会过多关注高频词,忽视了低频词的表达内容,不能完整地表达出申报文本的语义信息,进而降低了模型分类效果。
技术实现思路
1、本申请的目的在于提供一种海关进出口商品税率预测方法,创新地使用对比学习和对抗训练,使模型学习到数据文本中更多的语义信息,减轻数据不平衡问题,提高了海关商品税率预测准确率。
2、为实现上述目的,本申请的技术方案为:
3、一种基于对抗学习的海关进出口商品税率检测方法,步骤如下:
4、步骤1:对输入文本进行数据预处理;
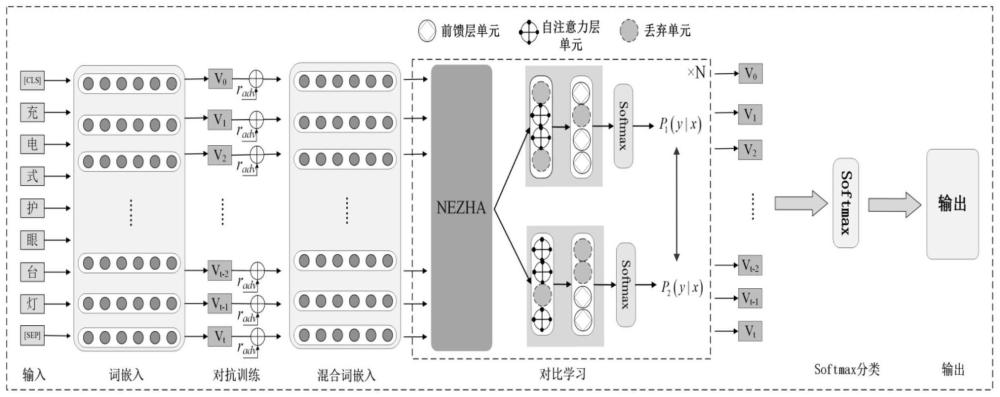
5、步骤2:将预处理好的文本,按顺序逐条送入clat-nezha(contrastive learningand adversarial training with nezha)深度学习模型中。其中,clat-nezha模型包括:词嵌入层、对抗训练层、nezha(neural contextualized representation for chineselanguage understanding)对比学习层以及softmax输出层。预处理好的文本首先送入词嵌入层,完成从文本到词向量的转变;
6、步骤3:针对步骤2得到的海关文本词向量,送入对抗训练层,对词向量添加扰动来模拟模型可能存在的错误,使模型学习到数据文本中更多的语义信息,最终形成一份融合了扰动的海关文本词向量;
7、步骤4:将步骤3得到的融合扰动的海关文本词向量,与原始词向量进行拼接后,送入nezha对比学习层进行对比学习;
8、步骤5:将nezha对比学层输出的向量送入softmax层进行税率检测。
9、本发明由于采用以上技术方案,能够取得如下的技术效果:
10、使用基于对比学习和对抗训练的深度学习方法,解决了海关商品数据中语义不同导致的一词多义现象以及海关商品数据类别分布不均衡的问题,提高了海关商品税率预测准确性。
技术特征:
1.一种基于对抗学习的海关进出口商品税率检测方法,其特征在于,步骤如下:
2.如权利要求1所述的一种基于对抗学习的海关进出口商品税率检测方法,其特征在于,所述的步骤3中,具体操作如下:
3.如权利要求1或2所述的一种基于对抗学习的海关进出口商品税率检测方法,其特征在于,所述的步骤4中,具体操作如下:
4.如权利要求1或2所述的一种基于对抗学习的海关进出口商品税率检测方法,其特征在于,所述的步骤1中,具体操作如下:
5.如权利要求3所述的一种基于对抗学习的海关进出口商品税率检测方法,其特征在于,所述的步骤1中,具体操作如下:
技术总结
本发明涉及自然语言处理技术领域,具体涉及一种基于对抗学习的海关进出口商品税率检测方法。使用基于对比学习和对抗训练的深度学习方法,解决了海关商品数据中语义不同导致的一词多义现象以及海关商品数据类别分布不均衡的问题,提高了海关商品税率预测准确性。
技术研发人员:张强,周成杰,车超,吴安奇
受保护的技术使用者:大连理工大学
技术研发日:
技术公布日:2024/2/1
- 还没有人留言评论。精彩留言会获得点赞!