一种基于小型化深度学习模型的噪声分类方法及装置与流程
本发明涉及噪声分类领域,尤其涉及一种基于小型化深度学习模型的噪声分类方法及装置。
背景技术:
1、以gpt-4等技术为代表的大规模预训练模型为了得到优异的性能,往往从海量数据中提取有用的知识。与此对应,模型参数的个数也非常庞大。eat架构的网络可以配置并训练成一种基于深度学习的端到端噪声分类大模型,具有上述特点。
2、从资源受限的设备来看,预训练大模型的主要问题是,计算量和参数数量十分庞大,实现成本高,推理计算速度慢,对设备资源要求高。这些问题的存在限制了预训练大模型的应用范围,尤其是不利于在大量资源受限的移动终端或者边缘设备中部署,而噪声分类经常需要在现场使用移动终端或者边缘设备采集噪声数据,因此使用受到很大限制。
技术实现思路
1、本发明目的在于针对现有技术的不足,提出一种基于小型化深度学习模型的噪声分类方法及装置。
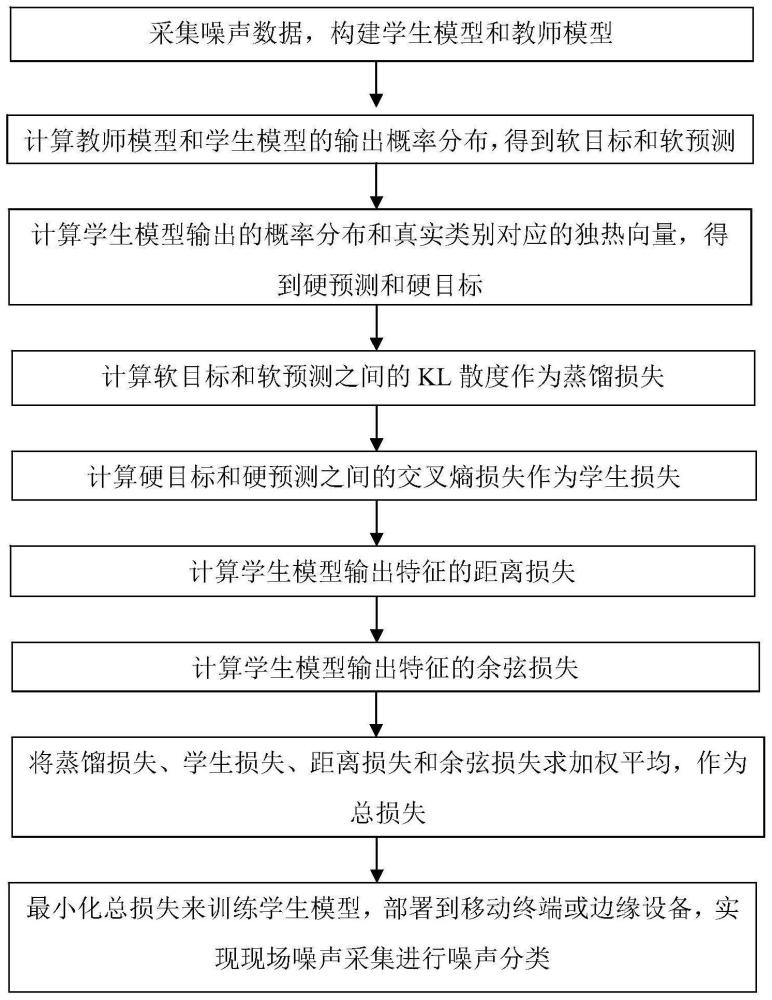
2、本发明的目的是通过以下技术方案来实现的:第一方面,本发明提供了一种基于小型化深度学习模型的噪声分类方法,该方法包括以下步骤:
3、(1)采集噪声数据构建噪声训练数据集,并构造学生模型和教师模型,预先完成教师模型的训练;
4、(2)在softmax层的温度t=2的情况下,将噪声训练数据集每一条噪声训练样本数据作为输入分别送入教师模型和学生模型,计算得到这两个模型的输出概率分布,即噪声分类结果,分别称为软目标和软预测;
5、(3)在softmax层的温度t=1的情况下,计算学生模型输出的概率分布,称为硬预测,输入噪声训练样本数据的真实类别对应的独热向量称为硬目标;
6、(4)分别计算软目标和软预测之间的kl散度作为蒸馏损失,硬目标和硬预测之间的交叉熵损失作为学生损失,学生模型输出特征的距离损失以及余弦损失;各损失求加权平均作为总损失;
7、(5)采用小批量梯度下降算法最小化总损失来训练学生模型直至模型收敛,利用学生模型部署在移动终端或者边缘设备,在应用现场采集噪声数据实现噪声分类。
8、进一步地,学生模型和教师模型均采用eat架构。
9、进一步地,假设xi是第i个输入噪声训练样本数据,ft(xi),fs(xi)分别表示教师模型和学生模型最后1个编码器层的输出特征;按照下面公式计算距离损失;
10、
11、其中,加权系数的计算公式如下:
12、
13、n(i)表示在小批量χ中和特征ft(xi)距离最近的k个特征组成的集合,即i的邻域,σ表示缩放因子。
14、进一步地,对于小批量χ中的每个三样本组合xi,xj,xk,计算三个样本的关系ψa[fs(xi),fs(xj),fs(xk)]=eijekj/(|eij||ekj|),即两个矢量之间夹角的余弦;eij=fs(xi)-fs(xj)表示第i个噪声训练样本特征和第j个噪声训练样本特征的向量差,用同样方法计算ψa[ft(xi),ft(xj),ft(xk)];按照下面公式计算余弦损失:
15、
16、其中加权系数的计算公式如下:
17、
18、m(j)表示在小批量中和特征ft(xj)距离最近的m个特征组成的集合,即j的邻域,σ表示缩放因子。
19、进一步地,将蒸馏损失、学生损失、距离损失和余弦损失求加权平均,作为总损失,计算公式如下:
20、ltotal=lkl+αlce+βldist+γlcos
21、加权系数预先定义,取经验值。
22、第二方面,本发明提供了一种基于小型化深度学习模型的噪声分类装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的一种基于小型化深度学习模型的噪声分类方法。
23、第三方面,本发明提供了一种计算机可读存储介质,其上存储有程序,所述程序被处理器执行时,实现所述的一种基于小型化深度学习模型的噪声分类方法。
24、本发明的有益效果:本发明通过知识蒸馏技术可以解决模型小型化的问题。采用一个预训练的大型模型,称为教师模型,通过知识蒸馏将其知识迁移到小模型,也称学生模型。与大模型相比,小模型的推理速度更快,参数个数更少,同时分类准确率下降不多。对于无法部署大模型的设备,例如移动终端设备,可以部署小模型在移动终端或边缘设备作为替代方案,能够在噪声现场进行噪声采集实现噪声分类。
技术特征:
1.一种基于小型化深度学习模型的噪声分类方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的一种基于小型化深度学习模型的噪声分类方法,其特征在于,学生模型和教师模型均采用eat架构。
3.根据权利要求1所述的一种基于小型化深度学习模型的噪声分类方法,其特征在于,假设xi是第i个输入噪声训练样本数据,ft(xi),fs(xi)分别表示教师模型和学生模型最后1个编码器层的输出特征;按照下面公式计算距离损失;
4.根据权利要求3所述的一种基于小型化深度学习模型的噪声分类方法,其特征在于,对于小批量χ中的每个三样本组合xi,xj,xk,计算三个样本的关系ψa[fs(xi),fs(xj),fs(xk)]=eijekj/(|eij||ekj|),即两个矢量之间夹角的余弦;eij=fs(xi)-fs(xj)表示第i个噪声训练样本特征和第j个噪声训练样本特征的向量差,用同样方法计算ψa[ft(xi),ft(xj),ft(xk)];按照下面公式计算余弦损失:
5.根据权利要求4所述的一种基于小型化深度学习模型的噪声分类方法,其特征在于,将蒸馏损失、学生损失、距离损失和余弦损失求加权平均,作为总损失,计算公式如下:
6.一种基于小型化深度学习模型的噪声分类装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,其特征在于,所述处理器执行所述可执行代码时,实现如权利要求1-5中任一项所述的一种基于小型化深度学习模型的噪声分类方法。
7.一种计算机可读存储介质,其上存储有程序,其特征在于,所述程序被处理器执行时,实现如权利要求1-5中任一项所述的一种基于小型化深度学习模型的噪声分类方法。
技术总结
本发明公开了一种基于小型化深度学习模型的噪声分类方法及装置,首先采集噪声数据构建噪声训练数据集,并构造学生模型和教师模型;然后计算两个模型的输出概率分布,分别称为软目标和软预测;并计算学生模型输出的概率分布,称为硬预测,输入噪声训练样本数据的真实类别对应的独热向量称为硬目标;之后分别计算软目标和软预测之间的KL散度作为蒸馏损失,硬目标和硬预测之间的交叉熵损失作为学生损失,教师模型和学生模型输出特征的距离损失以及余弦损失;各损失求加权平均作为总损失;最后采用小批量梯度下降算法最小化总损失来训练学生模型直至模型收敛,利用学生模型部署在移动终端或者边缘设备,在应用现场采集噪声数据实现噪声分类。
技术研发人员:任军军,赵明,罗浩,孙云云
受保护的技术使用者:杭州艾力特数字科技有限公司
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!