一种多模态三维目标检测方法和系统
本发明属于融合感知与多模态三维目标检测领域,涉及一种深度学习算法,具体涉及一种基于pointpillars(点云-柱)和resnet(深度残差网络)的多模态三维目标检测方法和系统。
背景技术:
1、随着人工智能和机器学习的兴起,自动驾驶在近些年来得到了快速的发展。作为自动驾驶领域的核心技术,目标检测的重要性愈发显著。
2、目前,自动驾驶的目标检测数据主要来源于实景采集和仿真平台生成。实景采集主要依靠各种传感器设备,例如摄像机、激光雷达、毫米波雷达等,摄像机收集图像和视频数据,而各种雷达收集点云数据。基于这些设备,一些研究已经通过实景采集和仿真平台收集了具有应用价值的数据集。基于这些数据集,很多研究者已经提出了可行的目标检测方法。但是,现有的目标检测方法存在一些问题:
3、首先,基于图像和视频数据的目标检测方法不能有效获取空间信息。现有图像和视频数据主要是由车载摄像机收集,而这些图像和视频数据主要反映的是车辆视角下的环境信息。由于观察视角受限,车载摄像机难以准确描述物体的形状和位置,这为精确检测带来了巨大的挑战。着眼于这个问题,一些研究提出了有效的方案,但是这些方法仍需依赖场景先验或几何约束来预测深度,其精确度和可用性相对有限。相比之下,点云数据中包含丰富的空间信息,可以反映物体的位置、轮廓、高度。然而,点云数据关注空间信息,但对场景细节的反映不足。此外,点云数据存在较为明显的稀疏问题:由于现实场景中的远距离、遮挡等问题,雷达不能够收集到足够的有效数据。点云稀疏会导致目标形状不完整,或者目标与环境背景混淆,最终导致错误检测或漏检测。
4、其次,在现实场景中,自动驾驶的部署任务对于目标检测模型的效率提出了较高的要求。由于传感器、芯片等硬件设备的限制,体量较大、结构较复杂的模型在部署中遇到挑战。此外,诸如避障、路径规划等一系列感知的下游任务,对目标检测模型的检测效率提出了要求。然而,大多数现有的算法都相对复杂,且检测效率有限,部署上存在困难。
技术实现思路
1、针对上述问题,本发明的目的是提供一种多模态三维目标检测方法和系统,该方法将pointpillars与resnet、cnn(卷积神经网络)等算法相结合,来完成基于图像数据和点云数据的高精度、高效率、适应性强的多模态三维目标检测。
2、为实现上述目的,本发明采取以下技术方案:
3、第一方面,本发明提供一种多模态三维目标检测方法,包括以下步骤:
4、获取目标车辆采集的图像数据和三维点云数据并进行预处理;
5、将预处理后目标车辆的图像数据和三维点云数据输入预先建立的多模态三维目标检测模型进行处理,得到三维目标检测框预测结果。
6、进一步,所述将预处理后目标车辆的图像数据和三维点云数据输入预先建立的多模态三维目标检测模型进行处理,得到三维目标检测框预测结果,包括:
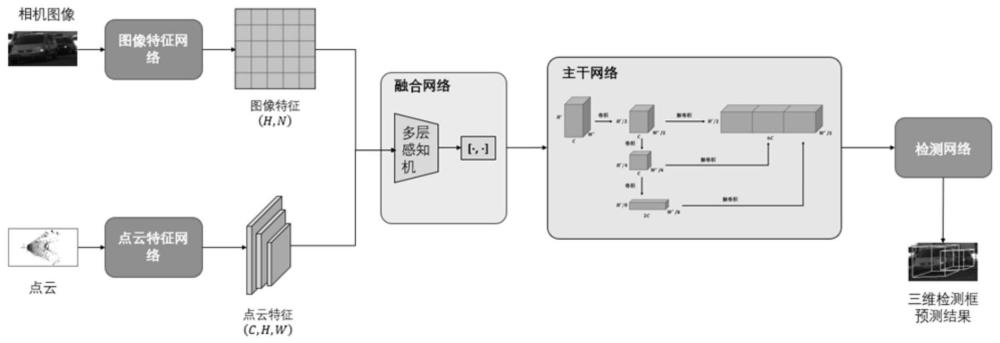
7、分别对获取的图像数据和点云数据进行特征提取,并对提取到的图像特征和点云特征进行融合;
8、将融合特征图输入主干网络进行特征处理,并将特征处理结果输入预先建立的检测框生成网络,得到三维目标检测框结果。
9、进一步,所述分别对获取的图像数据和点云数据进行特征提取,并对提取到的图像特征和点云特征进行融合,包括:
10、利用基于pointpillars的点云特征网络,对预处理后的三维点云数据进行点云特征的提取,得到点云特征;
11、利用基于resnet的图像特征网络,对预处理后的图像数据进行图像特征提取,得到图像特征;
12、利用融合网络将图像特征和点云特征进行融合,得到融合特征图。
13、进一步,所述利用基于pointpillars的点云特征网络,对预处理后的三维点云数据进行点云特征的提取,包括:
14、将点云数据在x-y平面上离散成均匀间隔的网格,并创建一组柱p,对点云数据中的每一个点a进行坐标更新,得到张量(d,p,n);
15、对每个张量(d,p,n),使用线性处理、批正则化和修正线性单元操作,生成张量(c,p,n);
16、对张量(c,p,n)使用最大池化操作,生成输出张量(c,p);
17、基于输出张量(c,p),将特征分散回原柱子p得到点云特征对应的伪图像(c,h,w)。
18、进一步,所述基于resnet的图像特征网络,采用在图像网络数据集上训练得到的resnet-50。
19、进一步,所述融合网络包括mlp模块和融合模块,所述mlp模块用于对输入的二维图像特征进行维度转换,使其与点云特征尺寸匹配;所述融合模块,用于将图像特征和点云特征进行密集融合,得到尺寸为(c,h′,w′)的融合特征图。
20、进一步,所述主干网络包括卷积层、反卷积层和输出层;
21、所述卷积层利用3*3的2d卷积模块对输入的融合特征图进行3次由上而下的采样,得到采样特征;
22、所述反卷积层用于使用batchnorm和relu对各2d卷积模块输出的采样特征进行反卷积;
23、所述输出层用于将各反卷积后的特征进行串联,得到特征处理结果。
24、第二方面,本发明提供一种多模态三维目标检测系统,其特征在于,包括:
25、数据获取模块,用于获取目标车辆采集的图像数据和三维点云数据并进行预处理;
26、目标检测模块,用于将预处理后目标车辆的图像数据和三维点云数据输入预先建立的多模态三维目标检测模型进行处理,得到三维目标检测框预测结果。
27、第三方面,本发明提供一种存储一个或多个程序的计算机可读存储介质,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行任一方法。
28、第四方面,本发明提供一种计算设备,包括:一个或多个处理器及存储器,在所述存储器中存储有一个或多个程序,并被配置为所述一个或多个处理器执行,所述一个或多个程序包括用于执行任一方法的指令。
29、本发明由于采取以上技术方案,其具有以下优点:
30、1、本发明将构建的多模态目标检测模型在kitti数据集上进行训练,经过180个epoch的训练过程,损失函数值趋于0。
31、2、本发明在kitti数据集的公开测试集上验证了提出的多模态目标检测算法。诸多实验结果表明,提出的算法模型在的检测效果比现有诸多算法至少提升3.80%,具体如表1所示。
32、3、本发明使用轻量级的主干网络,使得检测效率显著提升:提出的多模态目标检测算法的检测效率是现有诸多模型的至少2.9倍以上,与很多模型相比实现了明显超前。
33、因此,本发明可以广泛应用于融合感知与多模态三维目标检测领域。
技术特征:
1.一种多模态三维目标检测方法,其特征在于,包括以下步骤:
2.如权利要求1所述的一种多模态三维目标检测方法,其特征在于,所述将预处理后目标车辆的图像数据和三维点云数据输入预先建立的多模态三维目标检测模型进行处理,得到三维目标检测框预测结果,包括:
3.如权利要求2所述的一种多模态三维目标检测方法,其特征在于,所述分别对获取的图像数据和点云数据进行特征提取,并对提取到的图像特征和点云特征进行融合,包括:
4.如权利要求3所述的一种多模态三维目标检测方法,其特征在于,所述利用基于pointpillars的点云特征网络,对预处理后的三维点云数据进行点云特征的提取,包括:
5.如权利要求3所述的一种多模态三维目标检测方法,其特征在于,所述基于resnet的图像特征网络,采用在图像网络数据集上训练得到的resnet-50。
6.如权利要求3所述的一种多模态三维目标检测方法,其特征在于,所述融合网络包括mlp模块和融合模块,所述mlp模块用于对输入的二维图像特征进行维度转换,使其与点云特征尺寸匹配;所述融合模块,用于将图像特征和点云特征进行密集融合,得到尺寸为(c,h′,w′)的融合特征图。
7.如权利要求2所述的一种多模态三维目标检测方法,其特征在于,所述主干网络包括卷积层、反卷积层和输出层;
8.一种多模态三维目标检测系统,其特征在于,包括:
9.一种存储一个或多个程序的计算机可读存储介质,其特征在于,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行如权利要求1至7所述方法中的任一方法。
10.一种计算设备,其特征在于,包括:一个或多个处理器及存储器,在所述存储器中存储有一个或多个程序,并被配置为所述一个或多个处理器执行,所述一个或多个程序包括用于执行如权利要求1至7所述方法中的任一方法的指令。
技术总结
本发明涉及一种多模态三维目标检测方法和系统,包括以下步骤:获取目标车辆采集的图像数据和三维点云数据并进行预处理;将预处理后目标车辆的图像数据和三维点云数据输入预先建立的多模态三维目标检测模型进行处理,得到三维目标检测框预测结果。本发明方法将Pointpillars与ResNet、CNN(卷积神经网络)等算法相结合,来完成基于图像数据和点云数据的高精度、高效率、适应性强的多模态三维目标检测。因此,本发明可以广泛应用于融合感知与多模态三维目标检测领域。
技术研发人员:胡坚明,张羽昂,李星宇,刘晗韬
受保护的技术使用者:清华大学
技术研发日:
技术公布日:2024/1/25
- 还没有人留言评论。精彩留言会获得点赞!