一种基于ERNIE3.0_Att_IDCNN_BiGRU_CRF的命名实体识别算法
本发明属于自然语言处理中的中文命名实体识别方法,一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法。
背景技术:
1、随机互联网、智能制造等技术的发展,生产与生活中的信息呈指数倍的增长,如何在这海量的数据中探索有价值的信息就显得尤为重要,因此知识挖掘成为全世界研究热点之一。而命名实体识别作为知识抽取的重要环节之一,已经有一定的研究基础了。例如jib提出了词典+bilstm_crf是最为常见也是最经典的方式之一,它采用不同的特征向量构建方式提取中文文本的多维信息,提升模型识别效果。emma strubell和patrick verga提出了一种由cnn扩大卷积核得到的idcnn,使原本不适用于做序列问题的cnn适用于序列问题,同时还更好的应用cnn的计算优势。由谷歌推出bert以来,该预训练模型表征出的语义词向量在许多的中文任务模型中有着显著的提升,并且晏阳天与杨文明分别使用了bert_bilstm_crf与bert_idcnn_crf算法对命名实体识别进行了探究,并通过实验验证了其较好的性能。
2、但是在实际的知识提取中,由于人工标注的成本高以及专家少精力有限,所以命名实体识别的数据基本上是小样本,并且因为bert预训练模型并未考虑到中文语法和短语以及词的特性,因此,在一些小样本和学科交叉性较高的文本中,命名实体识别任务的精度依旧有限。鉴于上述情况下的命名实体任务在实际生产中的广泛存在,我们对其进行了研究,提出了一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法。这不是简单的替换了预训练模型,还对实体的局部与全局特征进行了更佳准确的表征。
技术实现思路
1、针对上述问题,提出了一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法,提出了一种更适用于中文任务的预训练模型,并且使用多头注意力机制和两种神经网络去提取实体在句子中的序列特征。
2、为实现上述目的,本发明采用以下技术方案。
3、一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法,包括以下步骤:
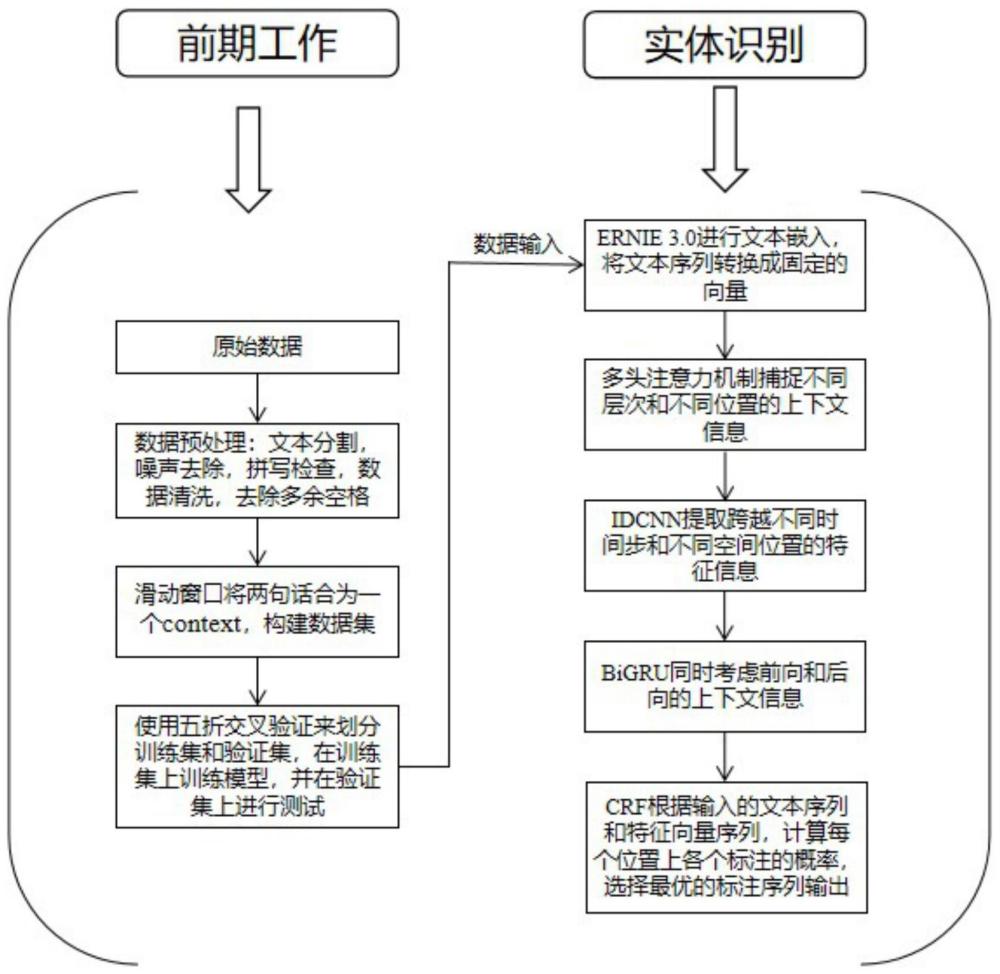
4、步骤1:利用百度发布的大语言模型预训练模型——ernie3.0,作为语义表征模型;
5、步骤2:将上一步利用ernie3.0表征出来的语义词向量加入att(注意力机制)强化实体前后的序列;
6、步骤3:将步骤2输出结果嵌入到idcnn(膨胀卷积神经网络)之中,以获取句子中的实体序列的局部特征;
7、步骤4:将idcnn的输出连接在bigru(双向门控循环单元);
8、步骤5:最后加上分类层与crf(条件随机场)得到最终结果。
9、优选的,所述步骤1之前,使用滑动窗口来将原始数据按照窗口大小(滑动窗口设为i+1,即每两句话为一条语料。)截取语料,构建出格式较为标准的数据集。
10、优选的,所述步骤1中利用的ernie预训练模型,改大语言预训练模型区别于bert预训练模型,前者是以词和短语等具有语法信息的特征知识去掩码,然后通过上下文预测来表征语义,后者而且以单字作为掩码,因此ernie更具有语法特性,能更适用于中文语言任务。
11、优选的,所述步骤2中利用多头注意力机制,将实体上下文的语义加强表征,使其更容易学到其中的函数关系。
12、优选的,所述步骤3中将cnn的卷积核扩大得到idcnn,使其拥有cnn的速度优势情况下,还优化了原本cnn不适用于前后序列问题,将其用于探索实体在句子中的局部特征,使实体特征得到更加准确的表达。
13、优选的,所述步骤4再使用了bigru对全局特征特征进行提取,且比其他使用bilstm(双向长短期记忆网络)等来探索长序列问题的算法更加简单高效。
14、优选的,所述步骤5最后使用了crf对实体的标签进行合理判断,使算法准确率更高。
15、与现有技术对比,本发明具备以下优异效果:
16、在实际的小样本多学科命名实体识别任务重,因文本过于复杂,现有的技术往往会造成识别精度较低的问题,提出一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法。该模型,使用了最懂中文的预训练模型之一的ernie的预训练模型,然后使用了注意力机制与其他神经网络相结合,不但考虑到了实体序列的局部和全局特征,还着重避免了模型因过于复杂计算速度慢的问题。最后还应用了crf考虑到标签类别的合理性。且在基于命名实体识别任务的msra、weibo、人民日报三个中文数据集,进行了一系列实验,验证了该模型的有效性。结果表明,该模型在小样本多学科交叉情况下,命名实体识别的f1性能指标上优于属于机器学习模型或深度学习模型的一些其他比较模型。此外,该模型的速度在诸多模型中也名列前茅。
技术特征:
1.一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法,其特征在于,所述步骤1中利用的ernie3.0预训练模型,改大语言预训练模型区别于bert预训练模型,前者是以词和短语等具有语法信息的特征知识去掩码,然后通过上下文预测来表征语义,后者而且以单字作为掩码,因此ernie更具有语法特性,能更适用于中文语言任务。
3.根据权利要求1所述的一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法,其特征在于,所述步骤2中利用多头注意力机制,将实体上下文的语义加强表征,使其更容易学到其中的函数关系。
4.根据权利要求1所述的一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法,其特征在于,所述步骤3中将cnn的卷积核扩大得到idcnn,使其拥有cnn的速度优势情况下,还优化了原本cnn不适用于前后序列问题,将其用于探索实体在句子中的局部特征,使实体特征得到更加准确的表达。
5.根根据权利要求1所述的一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法,其特征在于,所述步骤4再使用了bigru对全局特征特征进行提取,且比其他使用bilstm(双向长短期记忆网络)等来探索长序列问题的算法更加简单高效。
6.根根据权利要求1所述的一种基于ernie3.0_att_idcnn_bigru_crf的命名实体识别算法,其特征在于,所述步骤5最后使用了crf对实体的标签进行合理判断,使算法准确率更高。
技术总结
一种基于ERNIE3.0_Att_IDCNN_BiGRU_CRF的命名实体识别算法,包括以下步骤:步骤1:利用百度发布的大语言模型预训练模型——ERNIE3.0,作为语义表征模型;步骤2:将上一步利用ERNIE3.0表征出来的语义词向量加入Att(注意力机制)强化实体前后的序列;步骤3:将步骤二输出结果嵌入到IDCNN(膨胀卷积神经网络)之中,以获取句子中的实体序列的局部特征;步骤4:将IDCNN的输出连接在BiGRU(双向门控循环单元);步骤5:最后加上分类层与CRF(条件随机场)得到最终结果。基于命名实体识别任务的MSRA、Weibo、人民日报三个中文数据集进行了一系列实验验证了ERNIE3.0_Att_IDCNN_BiGRU_CRF模型的有效性。
技术研发人员:邱兰,朱波,邹艳华,王选飞,胡朋,荆晓娜,黎魁
受保护的技术使用者:昆明理工大学
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!