文本的处理方法、装置、电子设备和存储介质与流程
本发明涉及自然语言处理,特别涉及一种文本的处理方法、装置、电子设备和存储介质。
背景技术:
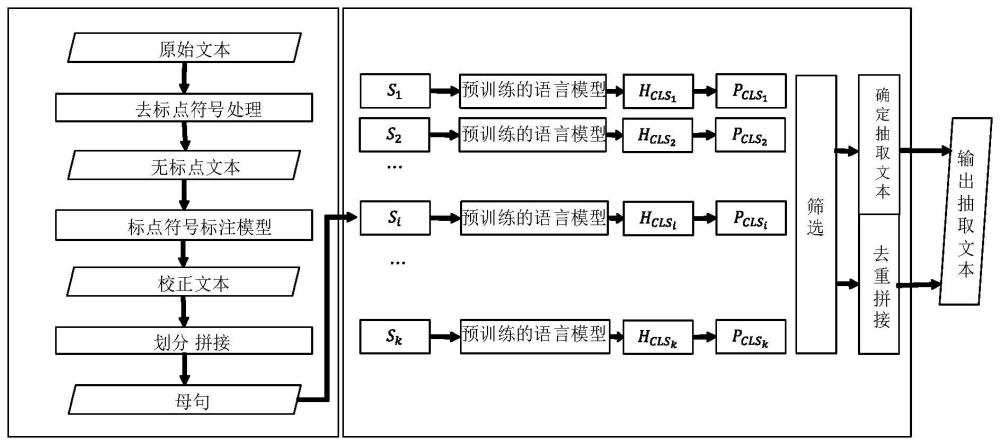
1、现有的文本抽取方式要么是通过传统的规则模板进行抽取,要么是通过命名实体识别算法等机器学习的方法对文本中的字段进行抽取。其中,规则模板需要手动编写,缺乏灵活性,因此机器学习的方法应用的更加广泛。然而,机器学习的方法需要大量的高质量的标注数据,即对原始文本进行子句拆分,筛选以及聚合等,从而得到子句集合作为抽取的文本。拆分时往往根据文本中的标点符号进行拆分,但是由于不同人语言习惯的不同,以及手误等,原始文本中的标点符号很多都是不规范的,这大大增加了机器学习中进行阅读理解的难度,从而导致文本数据处理的不准确,进而导致文本抽取的精确度不够。
技术实现思路
1、本发明要解决的技术问题是为了克服现有技术中文本处理的准确性低的缺陷,提供一种文本的处理方法、装置、电子设备和存储介质。
2、本发明是通过下述技术方案来解决上述技术问题:
3、本发明的第一方面提供一种文本的处理方法,所述处理方法包括:
4、获取待抽取的原始文本;
5、对所述原始文本进行去标点符号处理,得到无标点文本;
6、将所述无标点文本输入标点符号标注模型进行标点符号添加,得到校正文本;其中,所述标点符号标注模型为具有可控时间延迟变换层的神经网络模型。
7、较佳地,所述标点符号包括句末标点符号和句内标点符号,所述将所述无标点文本输入标点符号标注模型进行标点符号添加的步骤之后还包括:
8、根据所述句末标点符号对所述校正文本进行划分,得到分句;
9、根据所述句内标点符号对所述分句进行划分,得到子句;
10、分别判断分句中的每个目标子句是否包括预设的关键词,若包括,则将所述分句中与所述目标子句相邻的子句与所述目标子句进行拼接,得到与所述目标子句对应的母句;若不包括,则直接将所述目标子句确定为对应的母句;
11、其中,所述目标子句为对应分句中的任意一个子句。
12、较佳地,所述处理方法还包括:
13、将所有母句输入预先训练的语言模型进行识别,得到每个所述母句的类别标签;
14、从所有母句中筛选所述类别标签为目标标签的目标母句。
15、较佳地,所述从所有母句中筛选所述类别标签为目标标签的目标母句的步骤之后还包括:
16、判断任意两个目标母句之间是否存在组合关系,若是,则将所述两个目标母句进行去重拼接处理以作为抽取文本;
17、若否,则直接分别将每个所述目标母句确定为抽取文本;
18、其中,所述组合关系包括两个目标母句的内容重叠和/或在所述原始文本中的语序相邻。
19、本发明的第二方面提供一种文本的处理装置,所述处理装置包括获取模块、标点去除模块、标点添加模块:
20、所述获取模块用于获取待抽取的原始文本;
21、所述标点去除模块用于对待抽取的原始文本进行去标点符号处理,得到无标点文本;
22、所述标点添加模块将所述无标点文本输入标点符号标注模型进行标点符号添加,得到校正文本;其中,所述标点符号标注模型为具有可控时间延迟变换层的神经网络模型。
23、较佳地,所述标点符号包括句末标点符号和句内标点符号,所述处理装置还包括第一划分模块、第二划分模块、第一判断模块、第一拼接模块、第一确定模块:
24、所述第一划分模块用于根据所述句末标点符号对所述校正文本进行划分,得到分句;
25、所述第二划分模块用于根据所述句内标点符号对所述分句进行划分,得到子句;
26、所述第一判断模块用于分别判断分句中的每个目标子句是否包括预设的关键词,若包括,则调用所述第一拼接模块;若不包括,则调用所述第一确定模块;
27、所述第一拼接模块用于将所述分句中与所述目标子句相邻的子句与所述目标子句进行拼接,得到与所述目标子句对应的母句;
28、所述第一确定模块用于直接将所述目标子句确定为对应的母句;
29、其中,所述目标子句为对应分句中的任意一个子句。
30、较佳地,所述处理装置还包括识别模块、筛选模块:
31、所述识别模块用于将所有母句输入预先训练的语言模型进行识别,得到每个所述母句的类别标签;
32、所述筛选模块用于从所有母句中筛选所述类别标签为目标标签的目标母句。
33、较佳地,所述处理装置还包括第二判断模块、第二拼接模块和第二确定模块:
34、所述第二判断模块用于判断任意两个目标母句之间是否存在组合关系,若是,则调用所述第二拼接模块;若否,则调用所述第二确定模块;
35、所述第二拼接模块用于将所述两个目标母句进行去重拼接处理以作为抽取文本;
36、所述第二确定模块用于直接分别将每个所述目标母句确定为抽取文本;
37、其中,所述组合关系包括两个目标母句的内容重叠和/或在所述原始文本中的语序相邻。
38、本发明的第三方面提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明的文本的处理方法。
39、本发明的第四方面提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现本发明的文本的处理方法。
40、在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
41、本发明的积极进步效果在于:本发明利用具有可控时间延迟变换层的神经网络模型作为标点符号添加模型,该模型可以自适应地学习文本中的语法和语义信息,从而能够更精确地预测文本中的标点符号,进而将去标签符号处理后的文本输入标点符号标注模型添加相应的标点符号,得到校正后的文本,解决了语义错误截断的问题,其语义完整性能更好的被语言模型识别,提高了后续文本处理的精准度。
技术特征:
1.一种文本的处理方法,其特征在于,所述处理方法包括:
2.根据权利要求1所述的文本的处理方法,其特征在于,所述标点符号包括句末标点符号和句内标点符号,所述将所述无标点文本输入标点符号标注模型进行标点符号添加的步骤之后还包括:
3.根据权利要求2所述的文本的处理方法,其特征在于,所述处理方法还包括:
4.根据权利要求3所述的文本的处理方法,其特征在于,所述从所有母句中筛选所述类别标签为目标标签的目标母句的步骤之后还包括:
5.一种文本的处理装置,其特征在于,所述处理装置包括获取模块、标点去除模块、标点添加模块:
6.根据权利要求5所述的文本的处理装置,其特征在于,所述标点符号包括句末标点符号和句内标点符号,所述处理装置还包括第一划分模块、第二划分模块、第一判断模块、第一拼接模块、第一确定模块:
7.根据权利要求6所述的文本的处理装置,其特征在于,所述处理装置还包括识别模块、筛选模块:
8.根据权利要求7所述的文本的处理装置,其特征在于,所述处理装置还包括第二判断模块、第二拼接模块和第二确定模块:
9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1-4中任一项所述的文本的处理方法。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-4中任一项所述的文本的处理方法。
技术总结
本发明公开了一种文本的处理方法、装置、电子设备和存储介质。该处理方法包括获取待抽取的原始文本;对原始文本进行去标点符号处理,得到无标点文本;将无标点文本输入标点符号标注模型进行标点符号添加,得到校正文本;其中,标点符号标注模型为具有可控时间延迟变换层的神经网络模型。利用具有可控时间延迟变换层的神经网络模型作为标点符号添加模型,该模型可以自适应地学习文本中的语法和语义信息,从而能够更精确地预测文本中的标点符号,得到校正后的文本,解决了语义错误截断的问题,其语义完整性能更好的被语言模型识别,提高了后续文本处理的精准度。
技术研发人员:华倩龄,赵华,鞠剑勋,李健
受保护的技术使用者:上海携旅信息技术有限公司
技术研发日:
技术公布日:2024/1/25
- 还没有人留言评论。精彩留言会获得点赞!