一种基于双目测距的多目标人脸定位方法
本发明涉及多目标人脸跟踪技术,并涉及一种基于双目测距的多目标人脸定位方法。
背景技术:
1、人脸跟踪与定位一般是通过对视频流中每帧图像的人脸进行检测,然后实现前后帧人脸的对应匹配,接着根据人脸的结构特征,利用相似三角形原理测得对应人脸的深度信息,从而达到对目标跟踪定位的目的。因此,基于视觉算法的人脸跟踪与定位的主要方法为人脸检测和深度估计,其中,人脸检测算法决定着整个跟踪定位系统的实时性和稳定性,深度估计方法决定着目标定位的精确性。
2、常见的人脸检测方法主要有基于人脸特征的方法(如haar特征和hog特征)和基于深度学习的方法(如卷积神经网络),由于前者需要手动设计特征和参数调整,较适用于单目标人脸跟踪策略,而后者是从原始图像中提取高维抽象特征,故而基于深度学习方法有着更强大的表征能力和更高的准确率,对于多目标的检测和跟踪有着更好的应用场景。此外,传统的深度估计一般基于单目视觉定位,其一般需要一个固定长度的人脸特征,如瞳距等,但人脸在检测过程中,难免会因姿态变化(如偏转头部)导致瞳距等特征变化或消失,使得估算的精度不高,而双目定位只需针对目标中一个关键点,通过选择合适的双目基线和焦距,就能精准测出对应深度信息。因此,传统的多目标跟踪定位存在着精度不高、稳定性差的问题,难以满足实时准确的多目标跟踪要求。鉴于此,需要设计一种新的多目标人脸跟踪定位方法来解决此问题。
技术实现思路
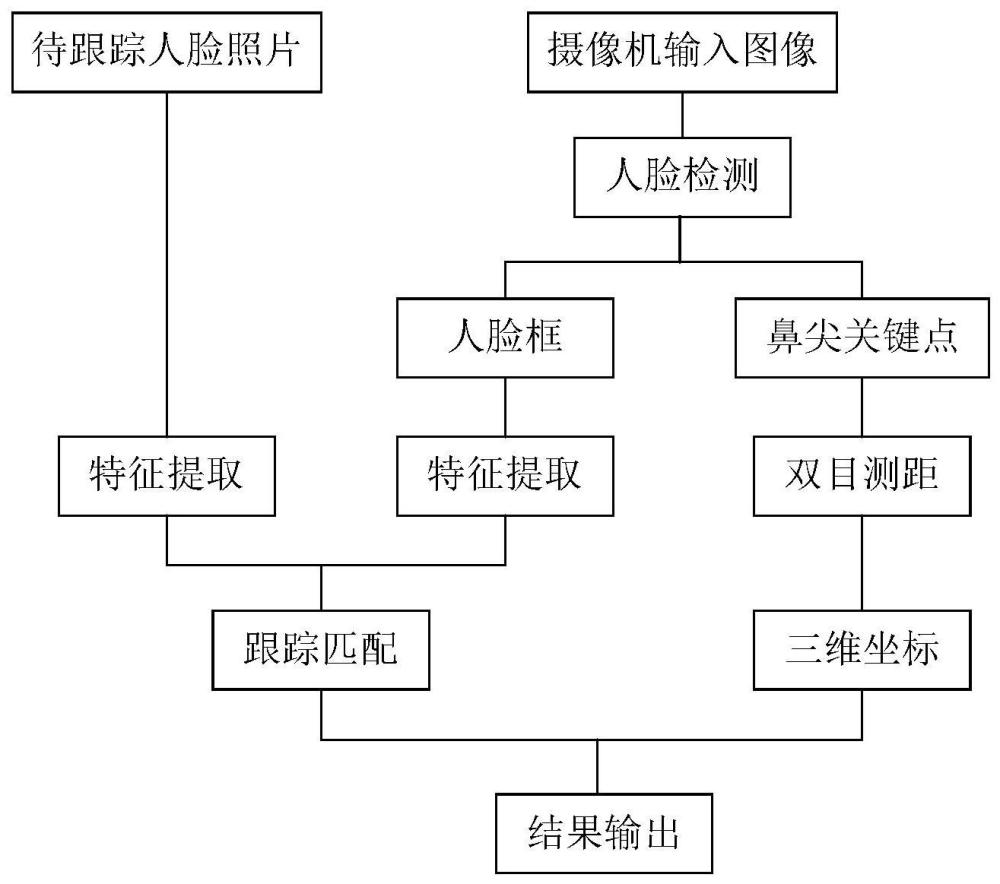
1、本发明的目的在于提供一种基于双目测距的多目标人脸跟踪定位方法,通过检测出视频流中的人脸特征,与后台照片人脸特征匹配形成多目标跟踪,再提取鼻尖关键点的像素坐标,计算出该关键点在摄影机坐标系下的三维坐标。
2、实现本发明目的的技术解决方案为:
3、一种基于双目测距的多目标人脸跟踪定位方法,包含以下步骤:
4、步骤1:采集多个待跟踪人脸正面照片,利用mobilefacenet算法提取每个人脸正面照片中的多维特征;
5、步骤2:检测摄影机输入视频流中的人脸,利用tinaface算法检测出每帧图像中所有人脸的检测框,以及所有人脸鼻尖关键点的像素坐标,并利用mobilefacenet对每个检测框的人脸提取特征;
6、步骤3:将每帧图像中的人脸特征与步骤1中的人脸特征做相似性匹配,从而在输入图像中每个人脸上标出对应步骤1中人脸的序号;
7、步骤4:构建摄影机的小孔成像模型,并利用张正友标定法对模型中的摄影机内参数进行标定;
8、步骤5:基于双目测距原理估算出人脸鼻尖处的深度信息;
9、步骤6:根据鼻尖关键点的像素坐标以及深度信息解算人脸处于摄影机坐标系下的三维坐标。
10、本发明与现有技术相比,其显著优点是:
11、(1)采用tinaface检测算法进行人脸检测和关键点提取,并采用mobilefacenet算法提取人脸高维特征以便于匹配跟踪,其检测跟踪的速度可达每帧20ms,能够实现对人脸目标的实时跟踪。
12、(2)基于双目测距原理实现对目标的深度估计,弥补了单目测距的精度不足的问题,且相比于其他传感器测距(如激光雷达等),有着实现成本更低,适应性强等优点。
技术特征:
1.一种基于双目测距的多目标人脸跟踪定位方法,其特征在于,包含以下步骤:
2.根据权利要求1所述的基于双目测距的多目标人脸跟踪定位方法,其特征在于,解算人脸处于摄影机坐标系下的三维坐标为:
3.根据权利要求2所述的基于双目测距的多目标人脸跟踪定位方法,其特征在于,第i个人脸的深度di为:
4.根据权利要求1所述的基于双目测距的多目标人脸跟踪定位方法,其特征在于,相似度匹配公式如下:
5.根据权利要求1所述的基于双目测距的多目标人脸跟踪定位方法,其特征在于,构建的摄影机小孔成像模型如下:
技术总结
本发明是提出一种基于双目测距的多目标人脸跟踪定位方法,具体包括:步骤1:采集待跟踪的多个正面人脸照片,基于深度卷积神经网络提取待跟踪人脸的特征;步骤2:检测摄影机输入的单帧图像中多个人脸,并提取人脸的鼻尖关键点像素坐标与人脸的特征;步骤3:基于匹配算法并利用步骤1和步骤2中得到的人脸高维特征进行跟踪匹配;步骤4:构建摄影机的小孔成像模型,并对模型内参数进行标定;步骤5:基于双目测距原理估算画面中人脸鼻尖关键点的深度;步骤6:解算人脸鼻尖关键点在摄影机坐标系下的三维坐标。本发明基于双目视觉中人脸图像信息,实现对不同人脸的实时、稳定跟踪,并实现对图像中多目标人脸的三维感知。
技术研发人员:徐骏善,翟雷雷,袁堂晓,刘帅
受保护的技术使用者:南京理工大学
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!