一种基于视觉语言模型的变电站视觉的场景描述方法与流程
本发明涉及图像生成文本领域,更具体的说是涉及一种基于视觉语言模型的变电站视觉的场景描述方法。
背景技术:
1、在变电站的监控、维护过程中,对变电站图像或视频进行描述是一项重要任务。然而,传统的手动描述方法费时费力且容易出错,因此,需要一种自动化的算法来实现对变电站视觉场景的描述,提高工作效率和准确性。
技术实现思路
1、针对现有技术存在的不足,本发明的目的在于提供一种基于视觉语言模型的变电站视觉的场景描述方法。
2、为实现上述目的,本发明提供了如下技术方案:一种基于视觉语言模型的变电站视觉的场景描述方法,用于描述带有提示文本的图像,其特征在于:包括如下步骤:
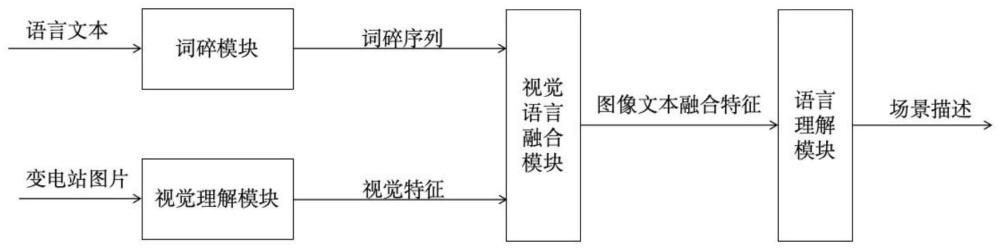
3、步骤一,使用词碎模块对文本进行分词和序列化;
4、步骤二,使用视觉理解模块提取视觉特征;
5、步骤三,使用语言视觉特征融合模块,对视觉特征和文本信息进行融合;
6、步骤四,使用语言理解模块,对融合的特征生成描述文本。
7、作为本发明的进一步改进,所述步骤一中使用词碎模块对文本进行分词和序列化的具体步骤如下:
8、步骤一一,对提示文本进行分词,并将提示文本分词后映射为序号,以对输入的自然语言文本进行分词和标记,将文本切分成词语的序列;
9、其中,提示文本分词的方式为采用中文分词方法将提示文本分成词碎,每个词碎表示文本的最小单位,提示文本分词后映射为序号的方式为每个词碎对应一个固定的序号,获取词碎的特征向量。
10、1、作为本发明的进一步改进,所述步骤二中使用视觉理解模块提取视觉特征的具体步骤如下:
11、步骤二一,对视觉图像进行像素缩放,将视觉图像切分小块,并获得小块的特征信息;
12、其中,视觉图像像素缩放的方式为采用下采样方法将将图像像素长和宽映射到224x224大小,用于提取固定数量的图像特征数,将切分好的图像小块输入transformer模块,之后提取带有小块特征信息的特征向量;
13、视觉图像切分小块,并获得小块的特征信息的方式为将224x224的图像以14x14的像素大小进行切分,共切分成16x16个像素块,将切分好的图像小块输入transformer模块,提取带有小块特征信息的特征向量,共256个特征作为图像特征。
14、作为本发明的进一步改进,所述步骤三中使用语言视觉特征融合模块,对视觉特征和文本信息进行融合的具体步骤如下:
15、步骤三一,将视觉理解模块获得的图像特征和词碎模块获取的文本特征进行拼接融合,256个图像特征拼接文本特征,得到融合后的图文特征。
16、作为本发明的进一步改进,所述步骤四中使用语言理解模块,对融合的特征生成描述文本的具体步骤如下:
17、步骤四一,使用大语言模型对图文特征进行理解和生成,实现相应的变电站场景图像描述。
18、本发明的有益效果,本发明的算法利用自然语言处理和计算机视觉技术,实现对变电站图像或视频的自动化描述。算法包括词碎模块、视觉理解模块、语言视觉特征融合模块和语言理解模块,通过将自然语言和视觉特征进行融合,生成准确、连贯的自然语言描述,提供了一种有效的变电站场景理解和文档化方法,通过采用视觉图像和提示文本融合的多模态方法,文本特征和图像特征融合,可以使模型更好的,更准确实现变电站场景的描述本发明对变电站视觉场景的图像,算法能够自动化地对变电站图像或视频进行描述,减少人工操作的工作量。
技术特征:
1.一种基于视觉语言模型的变电站视觉的场景描述方法,用于描述带有提示文本的图像,其特征在于:包括如下步骤:
2.根据权利要求1所述的基于视觉语言模型的变电站视觉的场景描述方法,其特征在于:所述步骤一中使用词碎模块对文本进行分词和序列化的具体步骤如下:
3.根据权利要求2所述的基于视觉语言模型的变电站视觉的场景描述方法,其特征在于:所述步骤二中使用视觉理解模块提取视觉特征的具体步骤如下:
4.根据权利要求3所述的基于视觉语言模型的变电站视觉的场景描述方法,其特征在于:所述步骤三中使用语言视觉特征融合模块,对视觉特征和文本信息进行融合的具体步骤如下:
5.根据权利要求4所述的基于视觉语言模型的变电站视觉的场景描述方法,其特征在于:所述步骤四中使用语言理解模块,对融合的特征生成描述文本的具体步骤如下:
技术总结
本发明涉及一种基于视觉语言模型的变电站视觉场景描述算法,该算法利用自然语言处理和计算机视觉技术,实现对变电站图像或视频的自动化描述。算法包括词碎模块、视觉理解模块、语言视觉特征融合模块和语言理解模块,通过将自然语言和视觉特征进行融合,生成准确、连贯的自然语言描述,提供了一种有效的变电站场景理解和文档化方法。
技术研发人员:刘志鹏,刘远超,刘全,陈元建,雷东,王欢,周建,吴超,黄以诚
受保护的技术使用者:国网湖北省电力有限公司超高压公司
技术研发日:
技术公布日:2024/3/31
- 还没有人留言评论。精彩留言会获得点赞!