基于机器翻译与语义相似度对比的句对齐方法、装置及计算机可读存储介质与流程
本发明属于机器翻译,具体地说,是涉及一种基于机器翻译与语义相似度对比的句对齐方法、装置及计算机可读存储介质。
背景技术:
1、在语料收集上,如若遇到格式不统一的双文档,需要将文档里的对译句子提取出来。现有技术中,针对上述的双文档,一般采用语料对齐工具实现对齐,其工作原理是:通过拆句后,根据句子的顺序进行语料对齐,该方式主要存在以下不足:(1)会因为文档格式不对或者不同的语言分句出现纰漏而不对应,需要人工后校验才能成为完整的句对;(2)当遇到格式比较混乱的双文档时,基本无法进行实现对齐。
技术实现思路
1、本发明的目的在于提供一种基于机器翻译与语义相似度对比的句对齐方法,以解决现有技术所存在的技术问题。
2、为了实现上述目的,本发明采取的技术方案如下:
3、基于机器翻译与语义相似度对比的句对齐方法,其特征在于,包括以下步骤:
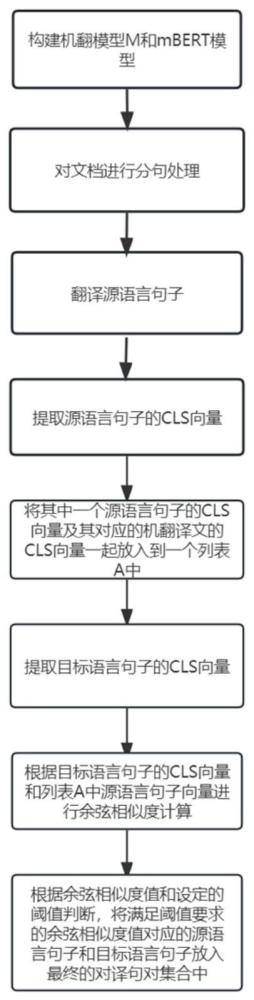
4、步骤s1:构建机翻模型m和mbert模型;
5、步骤s2:对文档进行分句处理,得到若干句子,并将所有句子分别放入源语言句子列表和目标语言句子列表;
6、步骤s3:将源语言句子列表中的所有句子通过所述机翻模型m翻译成机翻译文;
7、步骤s4:将源语言句子列表中的所有句子及其对应的机翻译文输入mbert模型,并从mbert模型的输出里提取其cls向量;
8、步骤s5:将源语言句子列表中的所有源语言句子的cls向量s_i_cls及其对应的机翻译文的cls向量s_mt_i_cls,一起放入到一个列表a中;
9、步骤s6:将目标语言句子列表中的所有句子输入mbert模型,并从mbert模型的输出里提取其cls向量;
10、步骤s7:遍历所述步骤s6中的所有cls向量,并分别与所述列表a中的源语言句子的cls向量s_i_cls以及机翻译文的cls向量s_mt_i_cls进行余弦相似度计算并相加得出余弦相似度值cls_i_cosin;
11、步骤s8:选取最大的余弦相似度值cls_i_cosin,若该余弦相似度值cls_i_cosin大于设定的阈值,则将对应的源语言句子列表中的句子和目标语言句子列表中的句子,放入最终的对译句对集合中。
12、在一种实施方案中,在所述步骤s2中,若文档为双文档,则分别根据双文档的语言对双文档分句后的句子进行语言检测,删除掉不符合语言检测结果的句子;若文档为单文档,则分别对单文档分句后的句子进行语言检测,然后根据检测出来的结果进行分类,并删掉不符合两个语言的句子。
13、在一种实施方案中,所述步骤s7中余弦相似度值采用如下公式计算:
14、
15、式中,a和b是需要比较的两个向量,“·”表示向量的内积,“||||”表示向量的范数。
16、在一种实施方案中,所述步骤s8中的阈值为超参数,属于经验值。
17、为实现上述目的,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行,以实现所述的基于机器翻译与语义相似度对比的句对齐方法。
18、为实现上述目的,本发明还提供了一种基于机器翻译与语义相似度对比的句对齐装置,包括处理器和存储器;所述存储器用于存储计算机程序;所述处理器与所述存储器相连,用于执行所述存储器存储的计算机程序,以使得所述基于机器翻译与语义相似度对比的句对齐装置执行上述的基于机器翻译与语义相似度对比的句对齐方法。
19、与现有技术相比,本发明具备以下有益效果:
20、本发明通过机器翻译以及语义相似度对比后,可以对分句后的句子分别进行语义匹配,能保证匹配到的句子是完整对译的,对文档的格式没有要求,单文档里出现的双语语料也可以进行提取,对格式比较混乱的文档也能够做到精准对齐的效果,相较于现有技术而言,不仅句对齐准确率高,不需要人工的后校验,而且对双文档没有格式要求,适应性强。
技术特征:
1.一种基于机器翻译与语义相似度对比的句对齐方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于机器翻译与语义相似度对比的句对齐方法,其特征在于,在所述步骤s2中,若文档为双文档,则分别根据双文档的语言对双文档分句后的句子进行语言检测,删除掉不符合语言检测结果的句子;若文档为单文档,则分别对单文档分句后的句子进行语言检测,然后根据检测出来的结果进行分类,并删掉不符合两个语言的句子。
3.根据权利要求2所述的基于机器翻译与语义相似度对比的句对齐方法,其特征在于,所述步骤s7中余弦相似度值采用如下公式计算:
4.根据权利要求3所述的基于机器翻译与语义相似度对比的句对齐方法,其特征在于,所述步骤s8中的阈值为超参数,属于经验值。
5.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行,以实现如权利要求1~4中任一项所述的基于机器翻译与语义相似度对比的句对齐方法。
6.一种基于机器翻译与语义相似度对比的句对齐装置,其特征在于,包括:处理器和存储器;所述存储器用于存储计算机程序;所述处理器与所述存储器相连,用于执行所述存储器存储的计算机程序,以使得所述基于机器翻译与语义相似度对比的句对齐装置执行如权利要求1~4中任一项所述的基于机器翻译与语义相似度对比的句对齐方法。
技术总结
本发明属于机器翻译技术领域,提供了一种基于机器翻译与语义相似度对比的句对齐方法、装置及计算机可读存储介质,本发明通过机器翻译以及语义相似度对比后,可以对分句后的句子分别进行语义匹配,能保证匹配到的句子是完整对译的,可以对不匹配的句子进行删除,以达到提取的语料为高质量句对的目的,并且对文档的格式没有要求,单文档里出现的双语语料也可以进行提取,对格式比较混乱的文档也能够做到精准对齐的效果,相较于现有技术而言,不仅句对齐准确率高,不需要人工的后校验,而且对双文档没有格式要求,适应性强。
技术研发人员:吴阳剑,朱宪超,霍展羽
受保护的技术使用者:四川语言桥信息技术有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!