一种基于Transformer的跨模态细粒度检索方法
本发明涉及多模态数据特征提取,融合技术,尤其涉及到transformer编码器结构中的注意力机制计算原理。
背景技术:
1、随着社会的发展,跨模态检索技术在搜索引擎中是十分重要的。跨模态细粒度检索技术可以针对任意模态类型的查询,返回各种模态类型的检索结果。现有的研究主要采用一个统一的范式,那就是预训练再迁移学习,其在多模态的许多下游任务中都取得了巨大的成功。其代表任务有跨模态检索,视觉问答,图像字幕,图文匹配等。
2、当前的视觉语言跨模态检索中主要分为两种主流方法,分别为单流方法和双流方法。单流模型通常将图像和文本数据拼接到一起共同输入给跨模态融合模块,图像和文本数据在该模块内部进行有效地细粒度交互。单流方法的做法简单,性能优越。其中最具有代表行的工作为vl-bert,imagebert,uniter。而双流方法和单流方法区别在于它对文本和图像数据分别采用各自的编码器进行编码,由于对图像和文本数据的特征提取是独立的,这大大提高了跨模态检索的效率。当然,其缺点就是缺少各个模态之间的信息交互,算法性能是有限的。其中最具有代表性的工作为clip,align,wenlan。而跨模态细粒度检索存在的最大的难点在于数据异构性的差异,来自不同模态的数据表征不一致,隶属于不同的特征空间。
技术实现思路
1、本发明的目的为解决真实场景中的跨模态细粒度检索问题,为跨模态细粒度检索的后续研究提供了重要的技术支持,可应用于搜索引擎,精准推送等应用领域。
2、为了实现上述目的,本发明采用的技术方案是:一种基于transformer的跨模态细粒度检索方法,其特征在于,包括以下步骤:
3、步骤1:获取数据集,选取并划分细粒度跨模态检索任务所需的训练集。
4、步骤2:对训练集的数据(图像,视频,音频和文本四个模态)分别进行预处理。
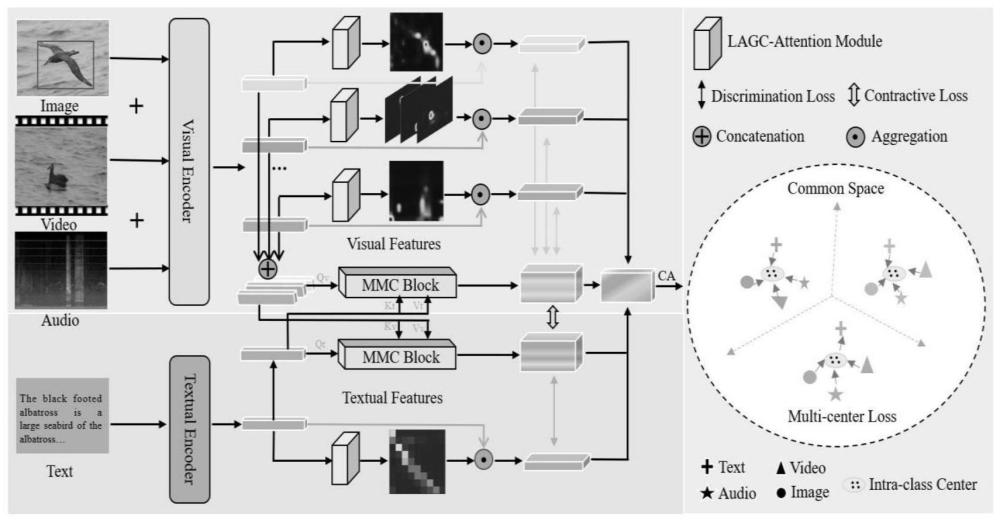
5、步骤3:将步骤2处理后的数据输入到基于pytorch开源深度学习框架设计的transformer结构中。其中,图像,视频和音频数据采用视觉编码器,文本数据采用文本编码器,并加载类别标签。
6、步骤4:将步骤3视觉和文本编码器处理后得到的特征分别输入lagc-attention模块和自设计的mmc特征融合模块,lagc-attention模块可以辅助细粒度样本进行高效特征提取,而mmc模块可获得每个模态的混合特征表达。
7、步骤5:计算每个模态的分类交叉熵损失和视觉文本对称的对比损失值,训练并优化该跨模态检索模型。
8、步骤6:利用优化后的模型参数,获得每个模态的特征表达,计算两两之间的余弦相似度,完成跨模态检索任务。
9、与现有技术相比,本发明具有以下有益效果:
10、本发明基于transfromer结构,首先为视觉和文本数据输入单独设计了transformer编码器,加载了预训练权重,保证了视觉和文本特征的有效特征提取。其次分别设计了(local and global cross-attention)lagc-attention模块和(multi-modalcross-attention)mmc模块,其也是基于transfromer搭建的。在视觉和文本的特征被有效提取之后,分别进行有效的特征融合,进行一次通道权重再分配,提升了有效特征所在通道的权重。最后,在网络模型训练的过程中引入了除了分类损失函数以外的对比学习损失函数。
技术特征:
1.一种基于transformer的跨模态细粒度检索方法,其特征在于,包括以下步骤:
2.根据权利要求1所述一种基于transformer的跨模态细粒度检索方法,其特征在于:步骤1)所述训练集划分,数据集来自于北大开源的fg-xmedia,一共包含了200种被细粒度分类的鸟类。分别有11788张图像(5994训练,5794测试),8000文本(4000训练,4000测试),18350视频(12666训练,5684测试),12000音频(6000训练,6000测试)。
3.根据权利要求1所述基于transformer的跨模态细粒度检索方法,其特征在于:步骤2)所述训练集预处理,对图像按照目标所在位置的像素坐标进行切割,避免除目标外的噪声干扰;对视频数据进行抽帧处理;对音频数据进行短时傅里叶编码转换为图像;文本数据保持原始形态。
4.根据权利要求1所述基于transformer的跨模态细粒度检索方法,其特征在于:步骤3)所述编码器如下:
5.根据权利要求1所述基于transformer的跨模态细粒度检索方法,其特征在于:步骤4)所述lagc-attention注意力模块采用了卷积神经网络搭建,其输入为各个模态经过backbone后浅层特征向量,将该特征向量通过矩阵映射为q,k,v三个表征,并采用3*3卷积提取k的信息,与q进行粘连,再通过两次3*3卷积获得注意力矩阵,再与v进行计算得到输出值,最终通过通道注意力cam进行修正,完成单模态特异性特征提取;所述mmc特征融合模块采用bert模型中的注意力交互层搭建,文本侧的token数目为当前输入的文本侧的最大长度,图像侧的token数目则为图像的张数(此处为13,由10张视频帧,1张音频,一张图像)。图像侧和文本侧数据经过mmc模块交互特征后,则会获得最终的特征输出。
6.根据权利要求1所述基于transformer的跨模态细粒度检索方法,其特征在于:步骤5)所述的损失函数共分为两类,分别为交叉熵损失和对称对比损失。交叉熵损失函数是每个模态的输出的分类损失。其公式如下:
技术总结
本发明公开了一种基于Transformer的跨模态细粒度检索方法,包括选取并制作跨模态检索任务所需的训练集数据和验证集数据,分别包含了图像,视频,音频和文本四个模态,以及它们各自的标签文件。本方法核心创新分为两部分,第一部分为模态特异性特征提取,将来自各模态的数据通过各自的编码器后,接LAGC‑Attention模块完成细粒度特征提取;第二部分为跨模态信息交互,通过自设计的跨模态交互的MMC模块完成,该模块可以充分融合来自不同模态的特征信息,并对不同模态的公共特征表达进行对齐。因此,每个模态提取得到的特征表达不仅包含了其单模态的有效信息,还包含了不同模态之间的联系与共性。这极大地增强了每一个模态的特征表达能力,尤其是缩小了文本模态与图像模态之间的异构性。因此在跨模态检索任务中,各模态皆可高效且准确地搜寻到其他模态。本发明为后续的跨模态细粒度检索和推荐算法等研究提供了重要的技术支持,可广泛应用于搜索引擎,精准推送等现实场景。
技术研发人员:陈乔松,张冶,刘峻卓,李远路,陈浩
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!