一种基于时序数据库的查询并发控制方法与流程
本发明属于时序数据库、cdn监控相关,尤其涉及一种基于时序数据库的查询并发控制方法。
背景技术:
1、时序数据库因其高吞吐量的写入能力,高压缩率,高效时间窗口、高聚合以及多维度查询能力等优点,被广泛应用于监控领域。
2、在监控系统中,使用时序数据库采集存储各个节点上系统或者应用的指标数据,对大量在空间上离散而时间上连续的数据展现较好的查询能力,方便故障预警、追踪以及数据展示。然而,随着业务规模增大,监控数据量与日俱增,时序数据库的查询压力增大,简单的并发控制很难平衡查询效率与实例稳定性。
技术实现思路
1、本发明所要解决的技术问题是针对背景技术的不足提供本发明提出一种基于时序数据库的查询并发控制方法,在解决时序数据库查询效率和系统稳定性的平衡问题,通过针对查询请求粒度的并发控制,使时序数据库实例在保证不崩溃的情况下,最大负荷的提供查询功能。
2、本发明为解决上述技术问题采用以下技术方案:
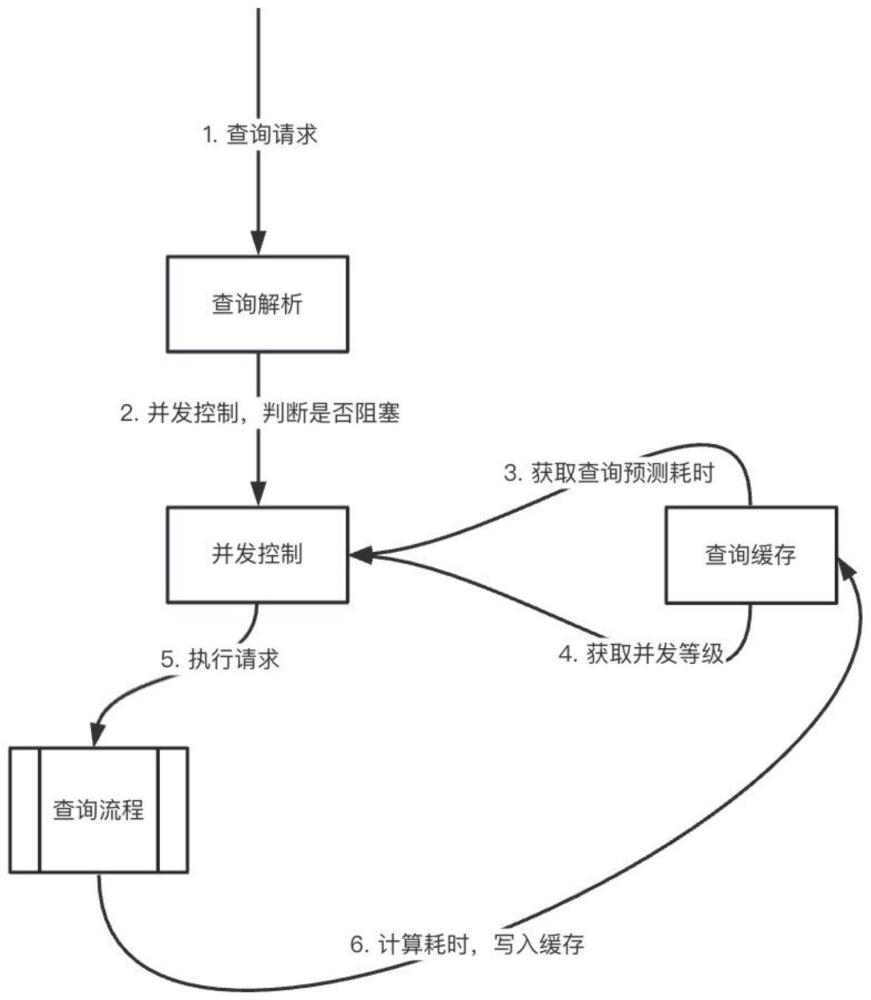
3、一种基于时序数据库的查询并发控制方法,查询前通过缓存预测查询耗时,确定并发等级,根据并发等级获取并发量,从而控制查询继续执行或阻塞,具体包含如下:
4、查询解析:解析查询语句,以此作为索引,写入或插入缓存;
5、查询缓存:量化查询成本并缓存,用于预测查询成本,确定并发等级;
6、并发控制:根据并发等级和配置的比例,确定并发量,控制查询。
7、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,所述查询解析,具体如下:
8、解析查询语句,使用时序数据库对应的语法解析模块,获取查询的指标名称、标签、函数操作和时间范围。
9、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,所述查询缓存,具体如下步骤:
10、步骤1,量化查询成本:查询成本=查询耗时/查询时间范围,其中,单位为s;
11、步骤2,缓存索引:采用map映射以及字典树的方法创建查询索引,每个节点保存查询成本最大值;
12、步骤3,缓存写入:
13、步骤4,缓存查询:
14、步骤5,节点排序:
15、步骤6,预测查询耗时:
16、步骤7,定时清理过期节点:
17、步骤7.1定时遍历节点队列,比较当前时间和节点最新更新时间,判断是否过期;
18、步骤7.2,节点过期则从队列中移除,保持队列有序;并根据节点的上级指针,反向遍历,依次移除叶子节点,且节点没有下级节点。
19、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,所述步骤3具体包含如下步骤,
20、步骤3.1,分别排序每个指标对应的标签和函数操作;再根据指标间的操作关系进行前后连接,形成指标名称->标签->函数操作->指标间操作->指标名称……格式的操作流;
21、步骤3.2,按照步骤3.1中生成的顺序,从根节点开始检索,如果有则更新该节点最大查询成本,跳转到下一个节点;如果没有,则创建节点并插入,更新节点查询成本最大值和该操作流的成本值和总耗时。
22、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,:所述步骤4具体包含如下步骤;
23、步骤4.1,用与缓存写入同样的方法,形成操作流;
24、步骤4.2,按照操作流的顺序,从根节点开始检索,直到检索失败;如果能检索到最后,则用最后一个节点的操作流成本值,如果检索在中间失败了,则用当前节点的最大成本值。
25、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,所述步骤5,具体包含如下步骤;
26、步骤5.1,创建节点有序队列;
27、步骤5.1,缓存写入时,同时将节点插入有序队列,保证队列根据节点的操作流总耗时有序排序。
28、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,所述步骤6具体包含如下步骤;
29、步骤6.1,解析查询语句;
30、步骤6.1,从缓存中获取查询成本;
31、步骤6.1,预测耗时=查询成本*查询时间范围。
32、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,以promql语法为例,所述查询解析,查询语句为:
33、sum(rate(go_cpu_usage{instance="192.168.1.1"}[5m]))
34、通过解析可以获取到:
35、查询指标:go_cpu_usage;
36、标签:instance;
37、函数操作:sum rate;
38、查询时间范围:300秒。
39、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,在步骤2中,所述并发控制,具体如下:
40、并发控制分为四个级别:
41、初始级别:当查询请求没有在缓存中找到成本值时,则使用这个级别;
42、高耗时查询:
43、中耗时查询:
44、低耗时查询:
45、根据并发总量以及每个等级的比例,可以确定每个等级的并发量。
46、作为本发明一种基于时序数据库的查询并发控制方法的进一步优选方案,所述并发控制,用于根据预测的查询耗时确定并发等级,从而得到并发量,再根据当前已使用的并发确定是否立即执行或者阻塞等待;
47、计算并发等级,具体如下:
48、a)向缓存查询预测查询耗时;
49、b)根据节点队列,查询预测耗时处在队列中的位置;
50、c)根据节点队列的长度和所处的位置确定并发等级。
51、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
52、1、本发明一种基于时序数据库的查询并发控制方法,时序数据库查询耗时的量化和索引方法;用指标名、标签、使用函数以及多指标之间的运算进行精准量化;同时,因为时序数据库指标、标签、函数数量有限,以此作为索引可以最大限度的复用量化值,减少缓存;
53、2、本发明采用并发分级控制的方法;根据耗时将并发分为不同级别,首先,保证查询效率,避免高耗时查询阻塞低耗时查询;其次,保证了查询的稳定性,适当提高高耗时查询的并发量,可以控制不同耗时的查询在大并发查询是使用时间接近;
54、3、本发明隔离不同耗时查询,避免高耗时查询过多而阻塞其他耗时较低的查询;
55、4、本发明灵活控制并发量,可根据实际的业务场景调节不同耗时查询的并发,用较低的并发总量使查询效率和稳定性达到最大化。
技术特征:
1.一种基于时序数据库的查询并发控制方法,其特征在于:查询前通过缓存预测查询耗时,确定并发等级,根据并发等级获取并发量,从而控制查询继续执行或阻塞,具体包含如下:
2.根据权利要求1所述的一种基于时序数据库的查询并发控制方法,其特征在于:所述查询解析,具体如下:
3.根据权利要求1所述的一种基于时序数据库的查询并发控制方法,其特征在于:所述查询缓存,具体如下步骤:
4.根据权利要求1所述的一种基于时序数据库的查询并发控制方法,其特征在于:所述步骤3具体包含如下步骤,
5.根据权利要求1所述的一种基于时序数据库的查询并发控制方法,其特征在于:所述步骤4具体包含如下步骤;
6.根据权利要求1所述的一种基于时序数据库的查询并发控制方法,其特征在于:所述步骤5,具体包含如下步骤;
7.根据权利要求1所述的一种基于时序数据库的查询并发控制方法,其特征在于:所述步骤6具体包含如下步骤;
8.根据权利要求2所述的一种基于时序数据库的查询并发控制方法,其特征在于:以promql语法为例,所述查询解析,查询语句为:
9.根据权利要求1所述的一种基于时序数据库的查询并发控制方法,其特征在于:在步骤2中,所述并发控制,具体如下:
10.根据权利要求9所述的一种基于时序数据库的查询并发控制方法,其特征在于:所述并发控制,用于根据预测的查询耗时确定并发等级,从而得到并发量,再根据当前已使用的并发确定是否立即执行或者阻塞等待;
技术总结
本发明公开了一种基于时序数据库的查询并发控制方法,涉及时序数据库、CDN监控相关技术领域,查询前通过缓存预测查询耗时,确定并发等级,根据并发等级获取并发量,从而控制查询继续执行或阻塞,具体包含如下:查询解析:解析查询语句,以此作为索引,写入或插入缓存;查询缓存:量化查询成本并缓存,用于预测查询成本,确定并发等级;并发控制:根据并发等级和配置的比例,确定并发量,控制查询。在解决时序数据库查询效率和系统稳定性的平衡问题,通过针对查询请求粒度的并发控制,使时序数据库实例在保证不崩溃的情况下,最大负荷的提供查询功能。
技术研发人员:李良伟,苏泽峰,黄全新,杨杰
受保护的技术使用者:天翼云科技有限公司
技术研发日:
技术公布日:2024/5/8
- 还没有人留言评论。精彩留言会获得点赞!