一种基于监督对比学习的隐式情感元素抽取方法
本发明涉及人工智能、自然语言处理的一种情感元素抽取方法,具体涉及了一种基于监督对比学习的隐式情感元素抽取方法。
背景技术:
1、方面级情感分析在当前互联网时代是一种信息智能化的重要技术,其主要目的为提取文本中的观点及其包含的情感极性,通过情感分析技术可以将互联网上大量的非结构化数据转换为结构化数据,从社交媒体意见挖掘到产品评论分析均为该任务的应用范围。方面级情感分析围绕文本中的四种情感元素展开,其中情感四元组抽取任务对文本中的全部四种情感元素进行抽取,是最为全面的方面级情感分析子任务。
2、然而,在情感四元组抽取任务中,现有的技术方法表现出明显的3点缺陷:
3、1、目前针对情感分析的研究重点主要集中在对文本中出现过的显式方面或意见的抽取,但文本中存在着大量隐式的方面或意见,这种含有隐式方面或意见的文本往往占据所有文本总量的30%以上。现有的针对情感元素抽取的工作中,绝大多数工作不能对隐式方面或意见进行检测和抽取。
4、2、在之前的方法中,对于隐式情感元素的检测往往需要添加一个分类器,以此来对隐式情感元素进行检测。然而,使用这种方法往往会使得模型的复杂性增加,限制了模型生成结果的灵活性。
5、3、现有的应用于情感四元组抽取任务的数据集中,种类“categories”这一情感元素的数量过多。因为种类数量众多导致了样本稀疏这一问题,许多种类只包含少量的样本,因此将方面这一情感元素分类到其中一个种类会变得比较困难。
技术实现思路
1、针对现有技术的缺陷与不足,本发明提供了一种基于监督对比学习的隐式情感元素抽取方法,解决了背景技术中涉及的问题。
2、为了实现上述技术目的,本发明通过以下技术方案予以实现:
3、一、一种基于监督对比学习的隐式情感元素抽取方法
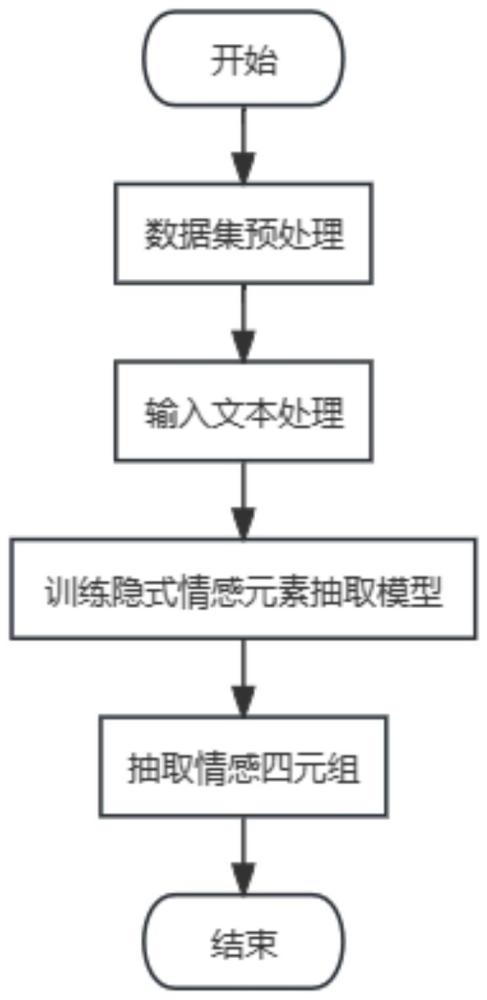
4、s1:对情感数据集进行预处理,获得预处理后的情感数据集;
5、s2:对预处理后的情感数据集对应的各输入文本进行位置标定,获得标定后的输入文本;
6、s3:利用各标定后的输入文本和预处理后的情感数据集对隐式情感元素抽取模型进行训练,获得训练好的隐式情感元素抽取模型;
7、s4:将待处理文本输入到训练好的隐式情感元素抽取模型中,检测当前待处理文本中包含的隐式情感元素并对情感四元组进行抽取。
8、所述s1具体为:
9、将情感数据集的类别“categories”中的所有种类以“#”为界进行分解,将“#”前的数据合并为一个子集,将“#”后的数据合并为另一个子集,从而获得预处理后的情感数据集。
10、所述s2中,在每个输入文本的预设位置均添加标定标签。
11、所述s2中,在每个输入文本的开头均添加标定标签。
12、所述s3中,隐式情感元素抽取模型中编码器和解码器之间通过并联设置的三个全连接层相连,三个全连接层的输出分别是提取的方面特征、意见特征和情感特征,根据提取的方面特征、意见特征和情感特征构建监督对比学习的损失,结合监督对比学习的损失对隐式情感元素抽取模型进行训练。
13、所述监督对比学习的损失的公式如下:
14、
15、其中,c为情感元素,具体为方面特征a、意见特征o和情感特征s,表示情感元素c的对应损失,hci为输入文本xi的情感元素c的表示;p(i)为与输入文本xi有相同标签的示例集合,记为第一集合;b(i)为除输入文本xi之外的所有其他示例的集合,记为第二集合;|p(i)|为第一集合p(i)中元素的数量;hcp为第一集合p(i)中示例p的情感元素c的表示,hcb为第二集合b(i)中示例b的情感元素c的表示,τ为温度参数;sim()表示两个向量之间的相似性。
16、二、一种计算机设备
17、所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时所述方法的步骤。
18、三、一种计算机可读存储介质
19、所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现所述的方法的步骤。
20、综上所述,本发明具有以下有益效果:
21、本发明提供了一种基于监督对比学习的隐式情感元素抽取方法,通过监督对比学习的方法使得模型能够区分的表示三种关键情感元素,从而更准确的检测到隐式情感元素;通过为输入文本添加“<<null>>”标签的方法使得模型可以用统一的方法处理显式与隐式情感元素;并通过拆分原始数据集中“categories”的种类去除其中的冗余部分,解决了样本稀疏的问题。
22、因此,本发明可以更为精准的检测出文本中的隐式方面以及隐式意见,从而推测出文本中的隐式情感,在文本的隐式情感元素抽取上具有一定的优势。
技术特征:
1.一种基于监督对比学习的隐式情感元素抽取方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于监督对比学习的隐式情感元素抽取方法,其特征在于,所述s1具体为:
3.根据权利要求1所述的一种基于监督对比学习的隐式情感元素抽取方法,其特征在于,所述s2中,在每个输入文本的预设位置均添加标定标签。
4.根据权利要求1所述的一种基于监督对比学习的隐式情感元素抽取方法,其特征在于,所述s2中,在每个输入文本的开头均添加标定标签。
5.根据权利要求1所述的一种基于监督对比学习的隐式情感元素抽取方法,其特征在于,所述s3中,隐式情感元素抽取模型中编码器和解码器之间通过并联设置的三个全连接层相连,三个全连接层的输出分别是提取的方面特征、意见特征和情感特征,根据提取的方面特征、意见特征和情感特征构建监督对比学习的损失,结合监督对比学习的损失对隐式情感元素抽取模型进行训练。
6.根据权利要求5所述的一种基于监督对比学习的隐式情感元素抽取方法,其特征在于,所述监督对比学习的损失的公式如下:
7.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至6中任一项所述方法的步骤。
8.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至6中任一项所述的方法的步骤。
技术总结
本发明公开了一种基于监督对比学习的隐式情感元素抽取方法。本发明包括以下步骤:首先,对情感数据集进行预处理,获得预处理后的情感数据集;接着,对预处理后的情感数据集对应的各输入文本进行位置标定,获得标定后的输入文本;然后,利用各标定后的输入文本和预处理后的情感数据集对隐式情感元素抽取模型进行训练,获得训练好的隐式情感元素抽取模型;最后,将待处理文本输入到训练好的隐式情感元素抽取模型中,检测当前待处理文本中包含的隐式情感元素并对情感四元组进行抽取。本发明可以更为精准的检测出文本中的隐式方面以及隐式意见,从而对上述隐式情感元素进行抽取,因此在文本的隐式情感元素抽取上具有一定的优势。
技术研发人员:席康,杨钰铭,刘继元,柴乃全
受保护的技术使用者:重庆大学
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!