强化多模态语义的对比学习代码搜索技术
本发明涉及强化多模态语义的对比学习代码搜索技术,属于自然语言处理与机器学习领域。
背景技术:
1、早期的代码搜索主要研究方法是将代码看作文本序列,将代码搜索问题转换为代码片段(特殊文本)和查询语句(普通文本)之间的字符匹配问题,通过关键字在代码库中查询目标代码片段。随着技术发展,当下主要研究方法多使用特征分类与深度学习相结合。通过引入抽象语法树(abstract syntax tree,ast)结构丰富代码的结构语义信息,使用各类神经网络,如长短期记忆网络(long short term memory,lstm)打破信息长度限制,从而学习代码片段和查询语句之间的高阶关联。但这些方法在实际应用中存在一些问题。
2、(1)查询语句与代码之间的语义鸿沟问题,查询语句高层级的意图与代码低层级的实现细节之间存在难以准确匹配的问题。现有的工作大多数通过使用单一维度,如token序列、ast树或两者结合的方法提取代码特征,学习代码结构和语义信息。这些方法从单一或两个维度(语义、语法或者逻辑结构等)进行代码分析,对代码信息的利用程度较低,不能准确且完整地描述代码,导致在训练时模型无法准确地学习所有的代码信息,造成最终代码搜索结果不准确。
3、(2)代码搜索过程存在语义塌陷问题,大多数现有的深度学习方法采用孪生网络框架,分别将查询语句和代码编码到特征空间中,并通过计算查询语句向量和代码向量间的余弦相似度来检索代码片段。但这个过程中,查询语句向量和代码向量在特征空间中变化范围小,使得匹配与不匹配的查询语句-代码对之间差异性较小,严重限制了它们的语义表达,导致最终代码搜索结果存在误差。
4、综上所述,现有的代码搜索方法中存在查询语句与代码之间的语义鸿沟和代码搜索过程的语义塌陷问题,所以本发明提出强化多模态语义的对比学习代码搜索技术。
技术实现思路
1、本发明的目的是针对现有代码搜索方法对查询语句和代码之间的语义相关性学习不足,以及查询语句向量和代码向量在特征空间中差异性小的问题,提出了强化多模态语义的对比学习代码搜索技术。
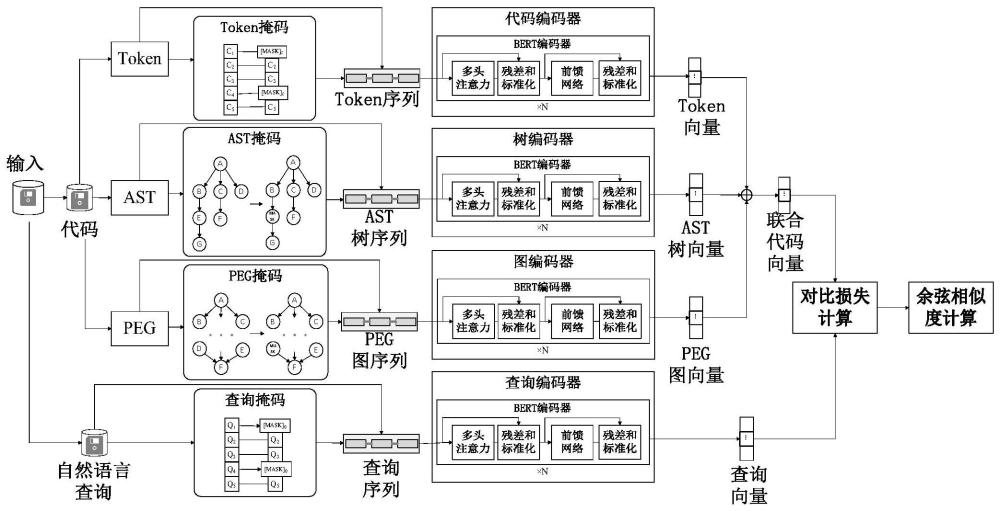
2、本发明的设计原理为:首先,将代码片段表示为token序列、ast树和程序表达式图(program expression graph,peg)三个模态,查询语句生成查询序列,并利用字节对编码(byte pair encoding,bpe)生成对应模态的词表;其次,基于制定的掩码规则对各个模态进行掩码操作,并利用前一阶段生成的词表,将掩码前后的各个模态转化为数字化序列表示;然后,通过bert模型向量化表示各个模态的数字化序列,并将token向量、ast树向量和peg图向量融合为联合代码特征向量;接下来,构建查询语句与代码间以及不同代码间的对比学习损失函数,在查询语句与代码间的对比学习损失函数计算过程中,将查询语句与匹配的代码视为正样本,查询语句与不匹配的代码视为负样本,在不同代码间的对比学习损失函数计算过程中,将掩码前后的代码视为正样本,同一批次的其他掩码前后的代码视为负样本;最后,计算查询语句向量和联合代码特征向量的余弦相似度并对结果排序,检索出与查询语句最匹配的代码片段。
3、本发明的技术方案是通过如下步骤实现的:
4、步骤1,构造查询语句和代码片段的不同模态表示,并利用bpe生成对应模态的词表。
5、步骤1.1,对于代码片段,将其分别转换为token序列、ast树和peg图三个模态;对于查询语句,转换为查询序列。
6、步骤1.2,对各个模态,使用bpe方法生成各自对应的词表。
7、步骤2,各个模态执行特定的掩码操作,并转化为数字化序列表示。
8、步骤2.1,token序列、ast树、peg图和查询序列使用不同的掩码规则进行掩码操作。
9、步骤2.2,通过步骤1.2中生成的词表,将掩码前后的各个模态表示为数字化序列。
10、步骤3,使用bert模型进行编码,并将代码片段的三个模态表示融合为联合代码特征向量。
11、步骤3.1,使用bert模型将掩码前后的token序列、ast树、peg图和查询序列映射到特征空间中,从而生成对应的向量表示。
12、步骤3.2,将token向量、ast树向量和peg图向量拼接融合,生成最终表示代码片段的联合代码特征向量。
13、步骤4,构建查询语句与代码间以及不同代码间的对比学习损失函数。
14、步骤4.1,在查询语句与代码间的对比损失函数计算过程中,查询语句向量与匹配的联合代码特征向量视为正样本,查询语句向量与不匹配的联合代码特征向量视为负样本。
15、步骤4.2,在不同代码间的对比损失函数计算过程中,掩码前后的联合代码特征向量视为正样本,掩码前后的联合代码特征向量与同一批次的其他掩码前后的联合代码特征向量视为负样本。
16、步骤5,计算查询语句向量和联合代码特征向量的余弦相似度并排序,检索出与查询语句最匹配的代码片段。
17、有益效果
18、相比于现有代码搜索方法只使用token序列和ast树,本发明额外引入了peg图表示,补充代码的结构信息,丰富代码的结构和语言信息表示,缓解了查询语句与代码存在语义鸿沟的问题。
19、相比于现有代码搜索方法存在匹配与不匹配的查询语句-代码对之间差异性较小的问题,本发明对不同模态制定了相应的掩码规则,构建查询语句与代码和不同代码间的正负样本,学习查询语句和代码间的相似性以及不同代码间的差异性。
技术特征:
1.强化多模态语义的对比学习代码搜索技术,其特征在于所述方法包括如下步骤:
2.根据权利要求1所述的强化多模态语义的对比学习代码搜索技术,其特征在于:步骤1中使用了额外的模态peg图来更充分地表示代码结构和语义信息。
3.根据权利要求1所述的强化多模态语义的对比学习代码搜索技术,其特征在于:步骤2中对不同模态构建了不同的掩码规则,其中对于token序列和查询序列,使用动态掩码操作,动态体现在每轮训练过程中会重新进行掩码操作,具体掩码规则是选取k个单词,其中80%用[mask]符号替换,10%用随机词汇替换,10%不做操作;对于ast树,本方法使用动态树掩码机制,动态体现在每轮训练过程重新掩码,树掩码规则是选取ast中k个节点,使用[mask]符号替换,其中越靠近终端节点,被替换的可能性越大;对peg图,使用动态图掩码操作,动态体现在每轮训练过程中会重新进行掩码操作,具体掩码规则是选取k个节点,使用[mask]符号替换,其中对于富含更多代码功能和信息的用户定义符号和变量名会以更大的概率被选中替换。
4.根据权利要求1所述的强化多模态语义的对比学习代码搜索技术,其特征在于:步骤4中构建查询语句与代码之间以及不同代码之间的对比学习损失函数,增大匹配与不匹配的查询语句-代码对之间的差异性。
技术总结
本发明涉及强化多模态语义的对比学习代码搜索技术,属于自然语言处理与机器学习领域。本发明首先将代码片段表示为token序列、抽象语法树和程序表达式图三种模态,利用BERT模型生成各模态特征向量,并拼接为联合代码特征向量;然后通过构建一种对比损失函数,缩小查询语句与对应代码片段在特征空间中的距离;最后利用余弦相似度计算查询语句特征向量与联合代码特征向量的距离并排序,输出代码搜索结果。本发明针对现有方法未充分提取代码结构特征、查询语句与代码片段存在语义鸿沟的问题,提出强化多模态语义的对比学习代码搜索技术,提高代码搜索的准确率。
技术研发人员:罗森林,徐程柯,潘丽敏,张凌浩,夏志豪
受保护的技术使用者:北京理工大学
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!