一种基于TDC算法的可重构卷积计算电路
本发明涉及卷积神经网络模型的硬件加速领域,具体涉及一种基于tdc算法的可重构卷积计算电路的实现。
背景技术:
1、近年来,带有反卷积层的卷积神经网络(cnn)迅速发展,在图像超分辨、图像生成、图像分割等领域展现出优越的效果。反卷积操作与正向卷积操作存在显著的不同。卷积核尺寸为2*2的正向卷积如图1(a)所示,卷积核尺寸为3*3的正向卷积如图1(b)所示。在图1(a)中i0,i1,i2,i3构成的矩阵为输入特征图,k11,k12,k21,k22构成的矩阵为卷积核,o为卷积计算得到的输出像素点;在图1(b)中,i0,i1,i2,i3,i4,i5,i6,i7,i8构成的矩阵为输入特征图,k11,k12,k13,k21,k22,k23,k31,k32,k33构成的矩阵为卷积核,o为卷积计算得到的输出像素点;与正向卷积相比,反卷积的计算过程更为复杂。根据jiale yan等人给出的计算流程,反卷积计算可分为三个步骤:1)各个输入特征图元素与卷积核相乘,得到一个与卷积核尺寸相同的子矩阵;2)各个子矩阵按其对应元素在原特征图的位置进行排布,然后叠加,得到一个尺寸更大的特征图;3)根据实际需求对得到的特征图进行边界裁剪。jiale yan等人给出的卷积核尺寸为3*3、步长为2的反卷积计算如图2所示,卷积核尺寸为4*4、步长为2的反卷积计算如图3所示。
2、由于反卷积层的计算比正向卷积更为复杂,与传统cnn相比,带有反卷积层的卷积神经网络硬件实现难度更大。卷积神经网络的硬件实现通常需要消耗大量的片上资源,而可重构技术可通过时分复用有效降低硬件资源开销。
3、目前已有一些相关工作的报道。例如,毛文东等人在2019internationalsymposium on circuits and systems会议上提出的可重构硬件加速器可支持卷积核尺寸为4*4的正、反卷积。lin bai等人在2020年international symposium on circuits andsystems会议上提出的可重构硬件加速器可支持卷积核尺寸为3*3的正、反卷积。然而很多卷积神经网络中需要用到的卷积类型不小于3种。例如超分辨卷积神经网络lapsrn中包含卷积核尺寸为3*3的正、反卷积和卷积核尺寸为4*4的反卷积。而前述两种硬件加速器均无法满足lapsrn的部署需求。
技术实现思路
1、针对超分辨卷积神经网络lapsrn的硬件实现需求,本发明提出了一种可支持一种正向卷积和两种反卷积的可重构卷积计算电路,在对特定网络进行硬件部署时采用此电路可有效降低硬件资源消耗。
2、jung-woo chang等人在ieee transactions on circuits and systems forvideo technology期刊上发表的“an energy-efficient fpga-based deconvolutionalneural networks accelerator for single image super-resolution”中提出了将反卷积计算转化成多个卷积计算的tdc方法。但是该方法在卷积核中进行了0的填充,降低了计算效率。lin bai等人在2020international symposium on circuits and systems会议上发表的“a unified hardware architecture for convolutions and deconvolutions incnn”中提出了针对卷积核尺寸为3*3的反卷积的优化计算策略。受这两种方法启发,本发明给出了tdc方法在卷积核尺寸为4*4时的改进策略,并结合3*3情况下的优化计算策略设计了适用于超分辨卷积神经网络lapsrn的可重构卷积计算电路。该电路支持尺寸为3*3、步长为1的正向卷积,尺寸为3*3、步长为2的反卷积,尺寸为4*4、步长为2的反卷积。
3、对于卷积核尺寸为3*3的反卷积应用tdc方法如图4所示。从图4中可看出,tdc方法将反卷积操作转化为多个卷积操作。具体地说,tdc方法可将3*3的反卷积分解为四个卷积核尺寸为2*2的正向卷积。将原卷积核中的9个元素分为元素个数为4,2,2,1的四部分并填充0后,分别得到四个尺寸为2*2的卷积核。分别用这四个卷积核对输入特征图某一位置处的2*2滑窗(如图4中的红色虚线框部分)做卷积操作,可分别得到输出特征图中对应位置的2*2局部块中的四个元素(如图4中红色实线框部分)。
4、对于卷积核尺寸为4*4的反卷积应用tdc方法如图5所示。从图5中可看出,对于上述情况,tdc方法可将4*4的反卷积分解为四个卷积核尺寸为3*3的正向卷积。tdc方法将原卷积核中的16个元素分为元素个数为4的四部分并填充0后,得到四个尺寸为3*3的卷积核。分别用这四个卷积核对输入特征图某一位置处的3*3滑窗(如图5中的红色虚线框部分)做卷积操作,可得到输出特征图中对应位置的2*2局部块中的四个元素(如图5中的红色实线框部分)。
5、针对卷积核尺寸为3*3的反卷积的优化计算策略如图6(b)所示。对于图6(a)中的四个尺寸为2*2的正向卷积(同图1(a)中的正向卷积),在去掉运用tdc方法时填充的0之后可组合为一个类似于3*3正向卷积的多个乘加计算,在图6(b)中分别用不同颜色表示。即:
6、o0=k33·i0+k31·i1+k13·i2+k11·i3
7、o1=k32·i1+k12·i3
8、o2=k23·i2+k21·i3
9、o3=k22·i3
10、tdc方法(针对卷积核尺寸为4*4的反卷积计算)的改进策略如图7(b)所示。从图7(a)中可看出,由tdc方法可以得到与一个4*4反卷积等价的四个尺寸为3*3的正向卷积(同图1(b)中的正向卷积)。图7(b)中包含两个类似3*3正向卷积的乘加计算。考虑到卷积核中0元素的特殊性,每一个类似3*3正向卷积的计算都可以算出图7(a)中的两个3*3卷积的计算结果,在图7(b)中用不同的颜色表示。即:
11、o0=w44·i0+w42·i1+w24·i3+w22·i4 o1=w43·i1+w41·i2+w23·i4+w21·i5
12、o2=w34·i3+w32·i4+w14·i6+w12·i7 o3=w33·i4+w31·i5+w12·i7+w11·i8
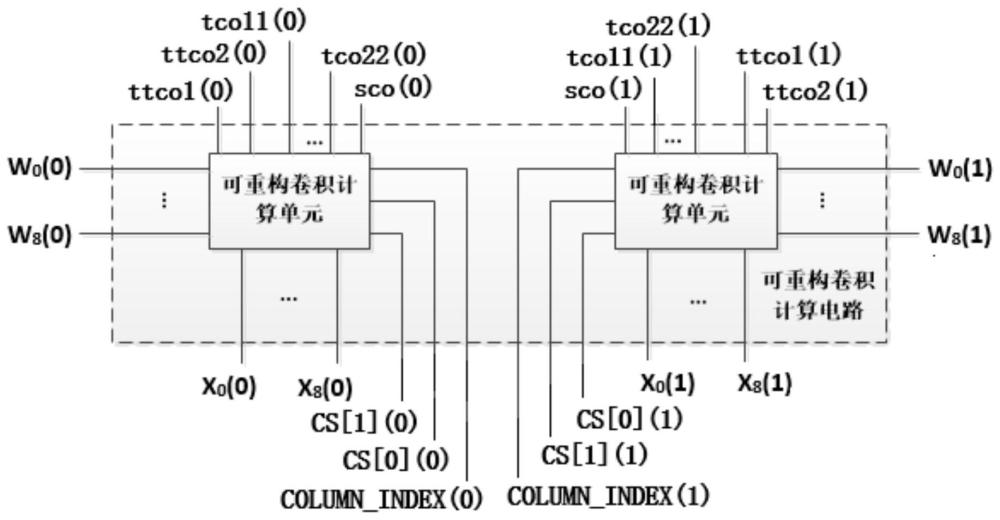
13、所述可重构卷积计算电路由两个可重构卷积计算单元构成;
14、可重构卷积计算单元根据相关配置信号改变内部结构,完成当前任务所需的乘加计算;
技术特征:
1.一种基于tdc(transforming the deconvolutional layer into theconvolutional layer)算法的可重构卷积计算电路及优化计算策略,其特征在于:针对超分辨神经网络lapsrn的部署需求,根据tdc算法及lin bai等人的工作,提出了一种针对反卷积的优化计算策略;基于前述优化计算策略和lin bai等人的计算方法,提出了一种可支持一类正向卷积和两类反卷积的可重构卷积计算电路及相应的计算任务分配策略。
2.根据权利要求1所述的反卷积优化计算策略,其特征在于:该方法实现卷积核尺寸为4*4的反卷积计算,与tdc算法相比,所述的优化计算策略降低了卷积核中填充0的个数,减少了冗余操作。
3.根据权利要求1所述的可支持一类正向卷积和两类反卷积的可重构卷积计算电路,其特征在于:该电路支持尺寸为3*3、步长为1的标准卷积,尺寸为3*3、步长为2的反卷积,尺寸为4*4、步长为2的反卷积。可重构卷积计算电路由两个可重构卷积计算单元构成。该单元通过乘法和加法电路实现局部卷积计算,根据与当前所处理卷积类型相对应的选择信号cs输出当前所需的卷积计算结果。在处理尺寸为3*3、步长为2的标准卷积和尺寸为3*3、步长为2的反卷积时,所述计算电路的乘法器资源利用率可达到100%。在处理尺寸为4*4、步长为2的反卷积时,所述计算电路的乘法器资源利用率可达到89%。尽管在处理尺寸为4*4、步长为2的反卷积时计算量更大,与前两种情况相比这一情形并未消耗额外的硬件资源。
4.根据权利要求1所述的计算任务分配策略,其特征在于:当处理尺寸为3、步长为2的标准卷积和尺寸为3*3、步长为2的反卷积时,一张输入特征图与一个卷积核之间的卷积操作由一个可重构卷积计算单元完成;当处理尺寸为4*4、步长为2的反卷积时,一张输入特征图与一个卷积核之间的卷积操作分成两部分,分别由两个卷积计算单元完成。
技术总结
本发明公开了一种TDC算法的改进计算策略和基于TDC算法的可重构卷积计算电路,目的是提供针对卷积核尺寸为4*4的反卷积的优化计算策略和一种可支持一类正向卷积和两类反卷积的可重构卷积计算电路。与TDC算法相比,本发明所述的优化计算策略降低了卷积核中填充0的个数,减少了冗余操作。本发明所述电路由两个可重构卷积计算单元构成,该计算单元能根据相关配置信号改变内部结构,完成当前任务所需的乘加计算。相较于同领域的其他工作,本发明在不降低硬件计算效率的前提下,实现了更多种类卷积类型的计算,具有更广的应用范围。
技术研发人员:李辉,张朝阳
受保护的技术使用者:电子科技大学
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!