深度神经网络多核加速器的片上缓存分配方法及相关装置与流程
本申请属于一种片上缓存分配方法,具体涉及一种深度神经网络多核加速器的片上缓存分配方法及相关装置。
背景技术:
1、深度神经网络被广泛应用于解决现实问题,例如图像和自然语言处理等。为了在复杂场景下获得更高的精度和鲁棒性,深度神经网络的规模越来越大,复杂度越来越高,导致对计算和存储的需求不断增加,因此,许多大规模加速器被提出用来满足不断提高的需求。其中,多核架构的加速器,由于其每个核心都可以独立处理特定的计算任务,成为目前最具优势的加速器。
2、尽管大规模的多核加速器拥有丰富的片上计算和存储资源,但如何充分利用其潜力来提升计算性能和资源效率,仍然具有一定的挑战性。据此引入了lp映射,在lp映射中,深度神经网络不同的层分别被分配至特定的核心,它们的计算输出特征映射可以通过网络芯片直接传递到消费层,以避免昂贵的dram(dynamic random access memory,动态随机存取存储器)访问成本。但lp映射仍然存在一个重要的缺点:许多核心的片上缓存区利用率极低。例如,当前lp映射在默认硬件设置上映射resnet-50时,有一半核心的片上缓存器利用率低于25.64%。
技术实现思路
1、本申请的目的在于解决现有技术中的问题,提供一种深度神经网络多核加速器的片上缓存分配方法及相关装置。
2、为了实现上述目的,本申请采用以下技术方案予以实现:
3、第一方面,本申请提出一种深度神经网络多核加速器的片上缓存分配方法,基于dnn对应的有向无环图;包括:
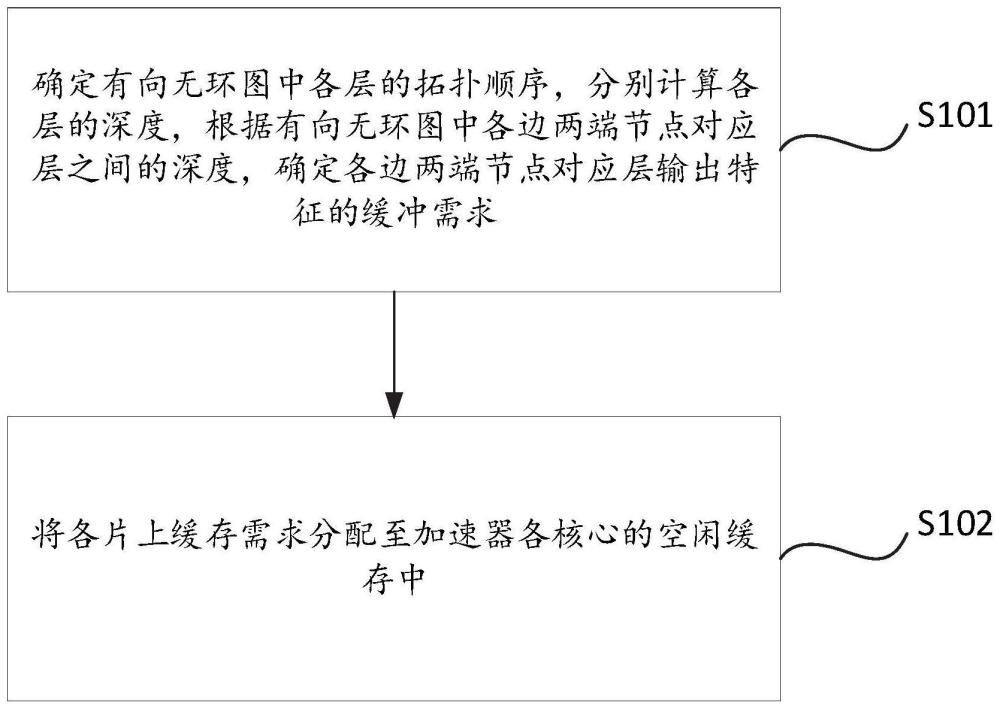
4、确定有向无环图中各层的拓扑顺序,分别计算各层的深度,根据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求;其中,任一层的深度为该层到最顶层的层距离,且最顶层的深度为零;
5、将各片上缓存需求分配至加速器各核心的空闲缓存中。
6、进一步地,所述计算各层的深度,包括:
7、
8、其中,di表示第i层的深度,lj表示第j层,pi表示li层的输入,dj表示第j层的深度,lj层和li层分别为一个边两端的节点,且从lj层指向li层。
9、进一步地,所述根据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求,包括:
10、
11、其中,capj表示lj层输出特征的片上缓存需求,capj,i表示lj→li的片上缓存容量需求,lj→li表示lj层到li层的边,nsb表示亚批总数量,cj表示lj层一个亚批的输出特征的大小。
12、进一步地,所述根据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求之前,还包括:
13、判断di和dj+1之间的关系,若di=dj+1,则没有片上缓存需求,否则,根据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求。
14、进一步地,所述将各片上缓存需求分配至加速器各核心的空闲缓存中,包括:
15、采用贪心算法,将各片上缓存需求分配至加速器各核心的空闲缓存中。
16、进一步地,所述将各片上缓存需求分配至加速器各核心的空闲缓存中,包括:
17、对于每个片上缓存区需求,分别设置一个片上缓存区的最小分配大小阈值l;
18、根据生产者层到消费者层的总noc距离,对所有满足容量要求的核心进行排序;
19、从最近的核心到最远的核心分配大于l的片上缓存需求。
20、进一步地,所述将各片上缓存需求分配至加速器各核心的空闲缓存中,还包括:
21、若所有核心的片上缓存区剩余容量均小于l,则使用dram进行片上缓存。
22、第二方面,本申请提出一种深度神经网络多核加速器的片上缓存分配系统,基于dnn对应的有向无环图;包括:
23、片上缓存区需求计算器,用于确定有向无环图中各层的拓扑顺序,分别计算各层的深度,根据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求;其中,任一层的深度为该层到最顶层的层距离,且最顶层的深度为零;
24、片上缓存分配器,用于将各片上缓存需求分配至加速器各核心的空闲缓存中。
25、第三方面,本申请提出一种计算机设备,包括:
26、存储器,用于存储计算机程序;
27、处理器,用于执行所述计算机程序时实现上述深度神经网络多核加速器的片上缓存分配方法的步骤。
28、第四方面,本申请提出一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时实现上述深度神经网络多核加速器的片上缓存分配方法的步骤。
29、与现有技术相比,本申请具有以下有益效果:
30、本申请提出一种深度神经网络多核加速器的片上缓存分配方法,根据有向无环图中各层的拓扑顺序,依据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求,再将各片上缓存需求分配至加速器各核心的空闲缓存中。采用本申请片上缓存需求计算方法,能够解决lp映射中的时间不匹配问题,大幅提高片上缓存利用率,并降低昂贵的dram访存次数。提高性能和能效。且与最先进的开源lp映射框架tangram相比,本申请的片上缓存分配方法能够降低能耗,降低成本,并降低延迟,显著提高了相应的性能和效率。
31、本申请还提出了一种深度神经网络多核加速器的片上缓存分配系统、计算机设备和计算机存储介质,能够通过不同的硬件形式实现上述片上缓存分配方法,具备上述方法的全部优势。
技术特征:
1.一种深度神经网络多核加速器的片上缓存分配方法,基于dnn对应的有向无环图;其特征在于,包括:
2.根据权利要求1所述一种深度神经网络多核加速器的片上缓存分配方法,其特征在于,所述计算各层的深度,包括:
3.根据权利要求2所述一种深度神经网络多核加速器的片上缓存分配方法,其特征在于,所述根据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求,包括:
4.根据权利要求2或3所述一种深度神经网络多核加速器的片上缓存分配方法,其特征在于,所述根据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求之前,还包括:
5.根据权利要求4所述一种深度神经网络多核加速器的片上缓存分配方法,其特征在于,所述将各片上缓存需求分配至加速器各核心的空闲缓存中,包括:
6.根据权利要求5所述一种深度神经网络多核加速器的片上缓存分配方法,其特征在于,所述将各片上缓存需求分配至加速器各核心的空闲缓存中,包括:
7.根据权利要求6所述一种深度神经网络多核加速器的片上缓存分配方法,其特征在于,所述将各片上缓存需求分配至加速器各核心的空闲缓存中,还包括:
8.一种深度神经网络多核加速器的片上缓存分配系统,基于dnn对应的有向无环图;其特征在于,包括:
9.一种计算机设备,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述深度神经网络多核加速器的片上缓存分配方法的步骤。
技术总结
本申请提出一种深度神经网络多核加速器的片上缓存分配方法,根据有向无环图中各层的拓扑顺序,依据有向无环图中各边两端节点对应层之间的深度,确定各边两端节点对应层输出特征的片上缓存需求,再将各片上缓存需求分配至加速器各核心的空闲缓存中。采用本申请片上缓存需求计算方法,能够解决LP映射中的时间不匹配问题,大幅提高片上缓存利用率,并降低昂贵的DRAM访存次数。提高性能和能效。且与最先进的开源LP映射框架Tangram相比,本申请的片上缓存分配方法能够降低能耗,降低成本,并降低延迟,显著提高了相应的性能和效率。
技术研发人员:蔡经纬,魏宇辰,彭森,吴作同,张延年
受保护的技术使用者:交叉信息核心技术研究院(西安)有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!