视频生成方法以及参数生成模型训练方法与流程
本说明书实施例涉及计算机,特别涉及视频生成方法以及参数生成模型训练方法。
背景技术:
1、随着计算机技术的发展,说话人视频生成逐渐成为研究重点。说话人视频生成可以分析处理语音信号,帮助用户创作出说话人视频,满足用户对创作和娱乐的需求,广泛应用于动画制作、虚拟代理、视频会议以及其他多媒体应用中。
2、然而,传统的说话人视频生成过程中会出现模式坍塌的问题,难以保证说话人视频的生动性以及准确度,因此,亟需一种生动且准确性高的视频生成方案。
技术实现思路
1、有鉴于此,本说明书实施例提供了视频生成方法。本说明书一个或者多个实施例同时涉及一种参数生成模型训练方法,视频生成装置,一种参数生成模型训练装置,一种计算设备,一种计算机可读存储介质以及一种计算机程序,以解决现有技术中存在的技术缺陷。
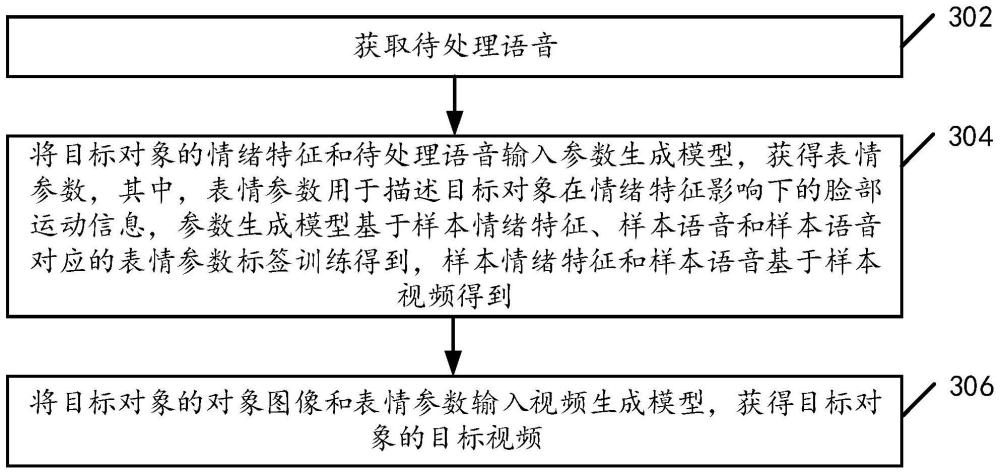
2、根据本说明书实施例的第一方面,提供了一种视频生成方法,包括:
3、获取待处理语音;
4、将目标对象的情绪特征和待处理语音输入参数生成模型,获得表情参数,其中,表情参数用于描述目标对象在情绪特征影响下的脸部运动信息,参数生成模型基于样本情绪特征、样本语音和样本语音对应的表情参数标签训练得到,样本情绪特征和样本语音基于样本视频得到;
5、将目标对象的对象图像和表情参数输入视频生成模型,获得目标对象的目标视频。
6、根据本说明书实施例的第二方面,提供了一种视频生成方法,包括:
7、接收用户发送的视频生成请求,其中,视频生成请求携带待处理语音;
8、将目标对象的情绪特征和待处理语音输入参数生成模型,获得表情参数,其中,表情参数用于描述目标对象在情绪特征影响下的脸部运动信息,参数生成模型基于样本情绪特征、样本语音和样本语音对应的表情参数标签训练得到,样本情绪特征和样本语音基于样本视频得到;
9、将目标对象的对象图像和表情参数输入视频生成模型,获得视频生成请求对应的目标视频;
10、向用户发送视频生成请求对应的目标视频。
11、根据本说明书实施例的第三方面,提供了一种参数生成模型训练方法,应用于云侧设备,包括:
12、获取多个包括样本对象的样本视频;
13、从样本视频中提取样本语音和样本语音对应的表情参数标签;
14、将样本对象的样本情绪特征和样本语音输入初始参数生成模型,获得预测表情参数;
15、根据预测表情参数和表情参数标签,调整初始参数生成模型的模型参数,获得训练完成的参数生成模型。
16、根据本说明书实施例的第四方面,提供了一种视频生成装置,包括:
17、第一获取模块,被配置为获取待处理语音;
18、第一输入模块,被配置为将目标对象的情绪特征和待处理语音输入参数生成模型,获得表情参数,其中,表情参数用于描述目标对象在情绪特征影响下的脸部运动信息,参数生成模型基于样本情绪特征、样本语音和样本语音对应的表情参数标签训练得到,样本情绪特征和样本语音基于样本视频得到;
19、第二输入模块,被配置为将目标对象的对象图像和表情参数输入视频生成模型,获得目标对象的目标视频。
20、根据本说明书实施例的第五方面,提供了一种视频生成装置,包括:
21、第一接收模块,被配置为接收用户发送的视频生成请求,其中,视频生成请求携带待处理语音;
22、第三输入模块,被配置为将目标对象的情绪特征和待处理语音输入参数生成模型,获得表情参数,其中,表情参数用于描述目标对象在情绪特征影响下的脸部运动信息,参数生成模型基于样本情绪特征、样本语音和样本语音对应的表情参数标签训练得到,样本情绪特征和样本语音基于样本视频得到;
23、第四输入模块,被配置为将目标对象的对象图像和表情参数输入视频生成模型,获得视频生成请求对应的目标视频;
24、发送模块,被配置为向用户发送视频生成请求对应的目标视频。
25、根据本说明书实施例的第六方面,提供了一种参数生成模型训练装置,应用于云侧设备,包括:
26、第二获取模块,被配置为获取多个包括样本对象的样本视频;
27、提取模块,被配置为从样本视频中提取样本语音和样本语音对应的表情参数标签;
28、第五输入模块,被配置为将样本对象的样本情绪特征和样本语音输入初始参数生成模型,获得预测表情参数;
29、调整模块,被配置为根据预测表情参数和表情参数标签,调整初始参数生成模型的模型参数,获得训练完成的参数生成模型。
30、根据本说明书实施例的第七方面,提供了一种计算设备,包括:
31、存储器和处理器;
32、所述存储器用于存储计算机可执行指令,所述处理器用于执行所述计算机可执行指令,该计算机可执行指令被处理器执行时实现上述第一方面或者第二方面或者第三方面所提供方法的步骤。
33、根据本说明书实施例的第八方面,提供了一种计算机可读存储介质,其存储有计算机可执行指令,该指令被处理器执行时实现上述第一方面或者第二方面或者第三方面所提供方法的步骤。
34、根据本说明书实施例的第九方面,提供了一种计算机程序,其中,当所述计算机程序在计算机中执行时,令计算机执行上述第一方面或者第二方面或者第三方面所提供方法的步骤。
35、本说明书一个实施例提供的视频生成方法,获取待处理语音;将目标对象的情绪特征和待处理语音输入参数生成模型,获得表情参数,其中,表情参数用于描述目标对象在情绪特征影响下的脸部运动信息,参数生成模型基于样本情绪特征、样本语音和样本语音对应的表情参数标签训练得到,样本情绪特征和样本语音基于样本视频得到;将目标对象的对象图像和表情参数输入视频生成模型,获得目标对象的目标视频。通过基于情绪特征和待处理语音生成表情参数,进一步根据表情参数生成目标视频,在保证目标视频中语音和表情同步的前提下,在目标视频中融入了多样化情绪信息,提高了目标视频的准确性与生动性。
技术特征:
1.一种视频生成方法,包括:
2.根据权利要求1所述的方法,所述将目标对象的情绪特征和所述待处理语音输入参数生成模型,获得表情参数之前,还包括:
3.根据权利要求2所述的方法,所述情绪参考数据包括情绪参考视频;
4.根据权利要求3所述的方法,所述第二特征提取模型包括序列提取单元、序列编码单元和自注意力池化单元;
5.根据权利要求1所述的方法,所述参数生成模型包括编码单元和解码单元;
6.根据权利要求1所述的方法,所述将目标对象的情绪特征和所述待处理语音输入参数生成模型,获得表情参数之前,还包括:
7.根据权利要求1所述的方法,所述将目标对象的情绪特征和所述待处理语音输入参数生成模型,获得表情参数之前,还包括:
8.根据权利要求1所述的方法,所述将所述目标对象的对象图像和所述表情参数输入视频生成模型,获得所述目标对象的目标视频之前,还包括:
9.一种视频生成方法,包括:
10.根据权利要求9所述的方法,所述向所述用户发送所述视频生成请求对应的目标视频之后,还包括:
11.一种参数生成模型训练方法,应用于云侧设备,包括:
12.一种计算设备,包括:
13.一种计算机可读存储介质,其存储有计算机可执行指令,该计算机可执行指令被处理器执行时实现权利要求1至8任意一项或者权利要求9至10任意一项或者权利要求11所述方法的步骤。
技术总结
本说明书实施例提供视频生成方法以及参数生成模型训练方法,其中所述视频生成方法包括:获取待处理语音;将目标对象的情绪特征和待处理语音输入参数生成模型,获得表情参数,其中,表情参数用于描述目标对象在情绪特征影响下的脸部运动信息,参数生成模型基于样本情绪特征、样本语音和样本语音对应的表情参数标签训练得到,样本情绪特征和样本语音基于样本视频得到;将目标对象的对象图像和表情参数输入视频生成模型,获得目标对象的目标视频。通过基于情绪特征和待处理语音生成表情参数,进一步根据表情参数生成目标视频,在保证目标视频中语音和表情同步的前提下,在目标视频中融入了多样化情绪信息,提高了目标视频的准确性与生动性。
技术研发人员:马一丰,张士伟,张迎亚
受保护的技术使用者:浙江阿里巴巴机器人有限公司
技术研发日:
技术公布日:2024/4/24
- 还没有人留言评论。精彩留言会获得点赞!