文本语义相似度对比方法、装置、设备及可读存储介质与流程
本发明涉及自然语言处理领域,尤其涉及一种文本语义相似度对比方法、装置、设备及可读存储介质。
背景技术:
1、传统的文本语义相似度计算方法,大多都是通过度量文本间的距离来进行相似度计算的,通过度量的文本中每个字符的差异来判断文本的相似度。但是传统的文本语义相似度计算方法在处理大规模复杂的文本数据时仍有较大的缺陷。因此,如何进行高性能和高效的文本语义相似度对比便成为了亟待解决的技术问题。
技术实现思路
1、本发明提供一种文本语义相似度对比方法、装置、设备及可读存储介质,用以解决如何进行高性能和高效的文本语义相似度对比的技术问题。
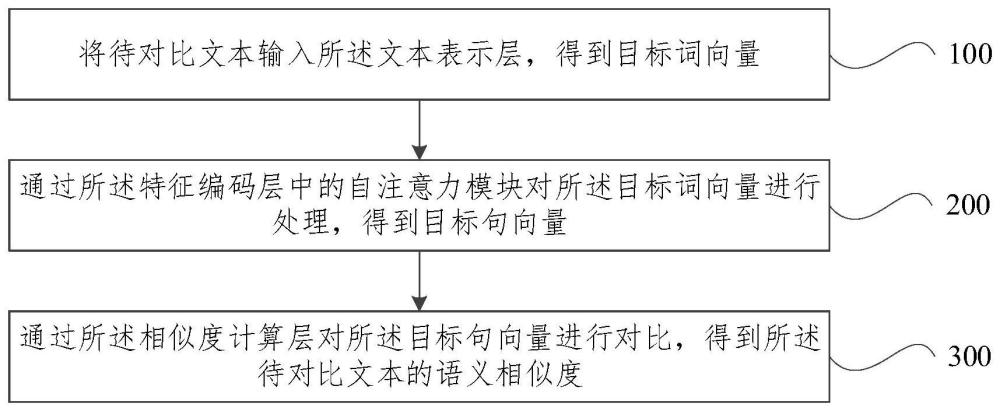
2、本发明提供一种文本语义相似度对比方法,应用于文本语义相似度对比模型,所述文本语义相似度对比模型包括文本表示层、特征编码层以及相似度计算层;文本语义相似度对比方法包括:
3、将待对比文本输入所述文本表示层,得到目标词向量;
4、通过所述特征编码层中的自注意力模块对所述目标词向量进行处理,得到目标句向量;
5、通过所述相似度计算层对所述目标句向量进行对比,得到所述待对比文本的语义相似度。
6、根据本发明提供的一种文本语义相似度对比方法,所述文本表示层包括编解码器;所述将待对比文本输入所述文本表示层,得到目标词向量包括:
7、确定待对比文本中各字符的序列化输入向量;
8、通过所述编解码器对各所述字符的序列化输入向量进行训练,得到目标词向量。
9、根据本发明提供的一种文本语义相似度对比方法,所述通过所述特征编码层中的自注意力模块对所述目标词向量进行处理,得到目标句向量包括:
10、通过所述特征编码层中的自注意力模块,确定所述待对比文本中的关键词信息;
11、通过全局最大池化和全局平均池化,基于所述关键词信息对所述目标词向量进行句向量信息抽取,得到目标句向量。
12、根据本发明提供的一种文本语义相似度对比方法,所述通过所述特征编码层中的自注意力模块,确定所述待对比文本中的关键词信息包括:
13、确定多个权重矩阵;
14、基于所述目标词向量和各所述权重矩阵,确定所述待对比文本中各个词的权值;
15、基于所述待对比文本中各个词的权值,确定所述待对比文本中的关键词信息。
16、根据本发明提供的一种文本语义相似度对比方法,所述基于所述待对比文本中各个词的权值,确定所述待对比文本中的关键词信息包括:
17、基于所述待对比文本中各个词的第一权值和第二权值,确定所述待对比文本中各个词的内积;
18、基于所述待对比文本中各个词的内积和第三权值,确定所述待对比文本中各个词的特征值;
19、根据所述待对比文本中各个词的特征值,确定所述待对比文本中的关键词信息。
20、根据本发明提供的一种文本语义相似度对比方法,所述相似度计算层包括匹配层和全连接层;所述通过所述相似度计算层对所述目标句向量进行对比,得到所述待对比文本的语义相似度包括:
21、通过所述匹配层中的连接函数对所述目标句向量进行处理,得到文本交互向量;
22、将所述文本交互向量输入所述全连接层,得到所述待对比文本的语义相似度。
23、根据本发明提供的一种文本语义相似度对比方法,所述全连接层使用归一化指数函数作为激活函数,使用多类交叉熵作为损失函数。
24、本发明还提供一种文本语义相似度对比装置,包括:
25、目标词向量确定模块,用于将待对比文本输入文本表示层,得到目标词向量;
26、目标句向量确定模块,用于通过特征编码层中的自注意力模块对所述目标词向量进行处理,得到目标句向量;
27、文本语义相似度对比模块,用于通过相似度计算层对所述目标句向量进行对比,得到所述待对比文本的语义相似度。
28、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述文本语义相似度对比方法。
29、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述文本语义相似度对比方法。
30、本发明提供的文本语义相似度对比方法、装置、设备及可读存储介质,通过文本表示层将原始文本表示为字级别的向量,在特征编码层从文本字向量表示中抽取得到句向量信息,最终经过相似度计算层得到待对比文本的语义相似度,实现了更高效的文本语义相似度对比。
技术特征:
1.一种文本语义相似度对比方法,其特征在于,应用于文本语义相似度对比模型,所述文本语义相似度对比模型包括文本表示层、特征编码层以及相似度计算层;所述文本语义相似度对比方法包括:
2.根据权利要求1所述的文本语义相似度对比方法,其特征在于,所述文本表示层包括编解码器;所述将待对比文本输入所述文本表示层,得到目标词向量包括:
3.根据权利要求1所述的文本语义相似度对比方法,其特征在于,所述通过所述特征编码层中的自注意力模块对所述目标词向量进行处理,得到目标句向量包括:
4.根据权利要求3所述的文本语义相似度对比方法,其特征在于,所述通过所述特征编码层中的自注意力模块,确定所述待对比文本中的关键词信息包括:
5.根据权利要求4所述的文本语义相似度对比方法,其特征在于,所述基于所述待对比文本中各个词的权值,确定所述待对比文本中的关键词信息包括:
6.根据权利要求1所述的文本语义相似度对比方法,其特征在于,所述相似度计算层包括匹配层和全连接层;所述通过所述相似度计算层对所述目标句向量进行对比,得到所述待对比文本的语义相似度包括:
7.根据权利要求6所述的文本语义相似度对比方法,其特征在于,所述全连接层使用归一化指数函数作为激活函数,使用多类交叉熵作为损失函数。
8.一种文本语义相似度对比装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7任一项所述文本语义相似度对比方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述文本语义相似度对比方法。
技术总结
本发明涉及自然语言处理领域,本发明提供一种文本语义相似度对比方法、装置、设备及可读存储介质,该方法包括:将待对比文本输入文本表示层,得到目标词向量;通过特征编码层中的自注意力模块对目标词向量进行处理,得到目标句向量;通过相似度计算层对目标句向量进行对比,得到待对比文本的语义相似度。本发明通过文本表示层将原始文本表示为字级别的向量,在特征编码层从文本字向量表示中抽取得到句向量信息,最终经过相似度计算层得到待对比文本的语义相似度,实现了更高效的文本语义相似度对比。
技术研发人员:李艳艳,李晓群,严佳梅,虞云飞,胡钊龙,盛平
受保护的技术使用者:国家电网有限公司客户服务中心南方分中心
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!