跨模态逐步蒸馏的基础模型轻量化方法、装置及设备
本公开涉及自然语言处理,尤其涉及一种跨模态逐步蒸馏的基础模型轻量化方法、装置、电子设备及介质。
背景技术:
1、部署大型语言模型(large language model,简称llm)具有挑战性,因为它们对于实际应用程序来说内存效率低且计算密集。为了应对上述挑战,研究人员通过使用人类标签进行微调或使用llm生成的标签进行提取来训练较小的任务特定模型。微调是一种改进预训练语言模型的方法。这些模型通过在大量通用文本集合上进行训练生成,能够识别通用的语言模式和结构。为了更好地应对特定任务,可以对预训练模型进行微调,使用额外的数据集重新训练模型的参数,使模型能够更好地理解和代表特定领域或任务的数据和模式,同时还保留了预训练获得的通用语言知识。模型压缩是为了将体积大、参数多且不便于部署的基础模型压缩成相对体积小、参数少且便于部署的小模型。在模型压缩的众多方法中,知识蒸馏表现优异。为了使学生模型达到与教师模型相似的性能,知识蒸馏通过逐步地使用一个较大的教师模型去教导一个较小的学生模型。然而,微调和蒸馏需要大量的训练数据才能实现与llm相当的性能。由于数据的多模态特征,大大加大了标注训练数据所需的人力。此外,不同模态间的数据存在的模态差异也一直是多模态研究领域的一大难题。
技术实现思路
1、鉴于上述问题,本发明提供了一种跨模态逐步蒸馏的基础模型轻量化方法,以解决上述技术问题。
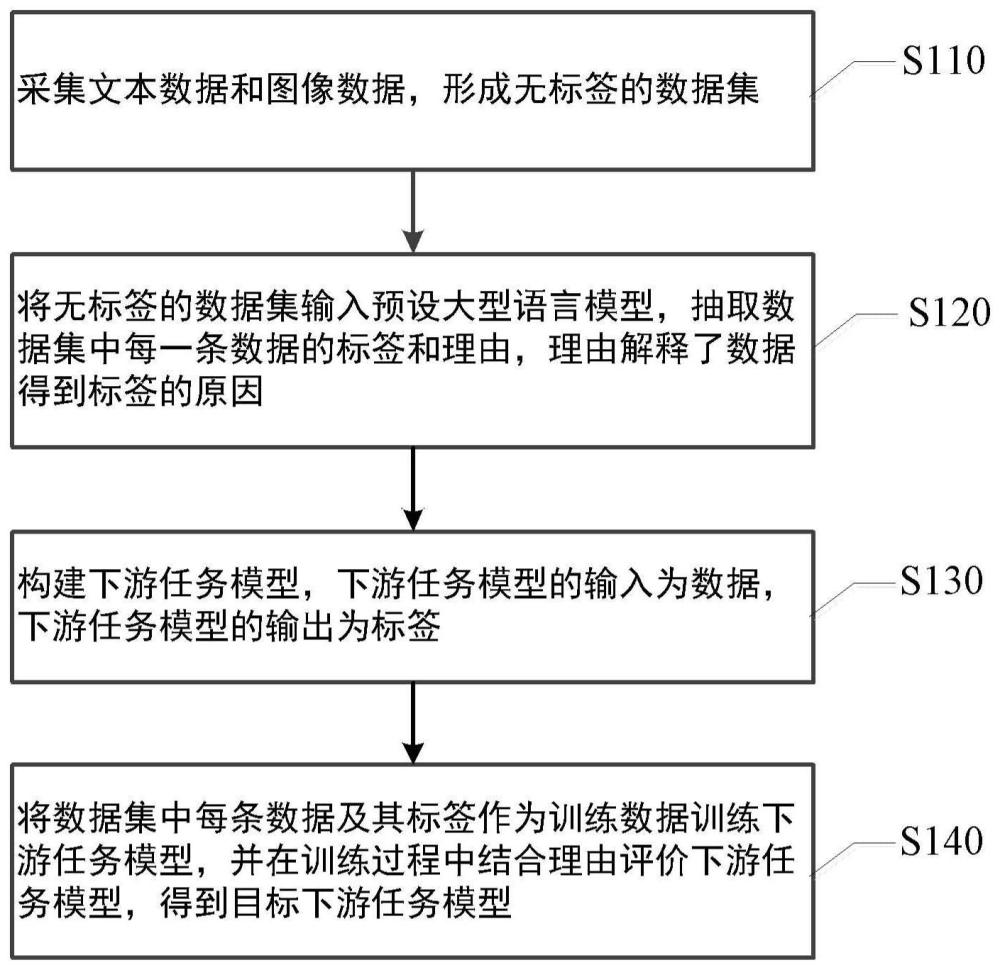
2、本公开的第一个方面提供了一种跨模态逐步蒸馏的基础模型轻量化方法,包括:采集文本数据和图像数据,形成无标签的数据集;将无标签的数据集输入预设大型语言模型,抽取所述数据集中每一条数据的标签和理由,所述理由解释了所述数据得到所述标签的原因;构建下游任务模型,所述下游任务模型的输入为所述数据,所述下游任务模型的输出为所述标签;将所述数据集中每条数据及其标签作为训练数据训练所述下游任务模型,并在训练过程中结合所述理由评价所述下游任务模型,得到目标下游任务模型。
3、根据本公开的实施例,所述将所述数据集中每条数据及其标签作为训练数据训练所述下游任务模型,并在训练过程中结合所述理由评价所述下游任务模型,得到目标下游任务模型包括:基于所述数据及其标签训练所述下游任务模型,并计算所述下游任务模型预测的标签的损失函数;基于下游任务模型预测的标签和所述理由计算关于理由的损失函数;融合所述标签的损失函数和所述关于理由的损失函数,得到模型损失函数;基于所述模型损失函数优化所述下游任务模型的参数;重复上述步骤,直至得到符合优化目标的所述目标下游任务模型。
4、根据本公开的实施例,所述下游任务模型预测标签的损失函数为:
5、
6、其中,llabel表示所述损失函数,f(xi)表示所述下游任务模型的函数表示,xi表示第i个输入所述下游任务模型的数据,表示第i个标签,n表示训练所述下游任务模型的数据总数。
7、根据本公开的实施例,所述计算关于理由的损失函数包括:
8、
9、其中,lrationale表示所述关于理由的损失函数,f(xi)表示所述下游任务模型的函数表示,xi表示第i个输入所述下游任务模型的数据,表示第i个数据的理由,n表示训练所述下游任务模型的数据总数。
10、根据本公开的实施例,所述模型损失函数的计算公式为:
11、l=llabel+λlrationale;
12、其中,l表示所述模型损失函数,llabel表示所述损失函数,lrationale表示所述关于理由的损失函数,λ表示权重参数。
13、根据本公开的实施例,所述将无标签的数据集输入预设大型语言模型,抽取所述数据集中每一条数据的标签和理由包括:设定所述预设大型语言模型的提示模版,所述提示模版包括了所述大型语言模型的输入格式、输出目标和思维逻辑;将所述数据根据预设输入格式输入所述预设大型语言模型,并根据所述思维逻辑进行推导,得到符合输出目标的标签和理由。
14、根据本公开的实施例,所述方法还包括:根据所述思维逻辑将所述数据拆解为多个计划任务,所述多个计划任务分别包括所述数据的部分内容;将所述多个计划任务分别输入不同的预设大型语言模型,并根据所述思维逻辑进行推导,得到标签和理由;将所述多个计划任务的标签和理由整合,得到最终的标签和理由。
15、本公开的第二个方面一种跨模态逐步蒸馏的基础模型轻量化装置,包括:数据采集模块,用于采集文本数据和图像数据,形成无标签的数据集;标签抽取模块,用于将无标签的数据集输入预设大型语言模型,抽取所述数据集中每一条数据的标签和理由,所述理由解释了所述数据得到所述标签的原因;模型构建模块,用于构建下游任务模型,所述下游任务模型的输入为所述数据,所述下游任务模型的输出为所述标签;模型训练模块,用于将所述数据集中每条数据及其标签作为训练数据训练所述下游任务模型,并在训练过程中结合所述理由评价所述下游任务模型,得到目标下游任务模型。
16、在本公开实施例采用的上述至少一个技术方案能够达到以下有益效果:
17、(1)根据本公开实施例提供的跨模态逐步蒸馏的基础模型轻量化方法训练模型,全程无需人工标注,其中,该方法采用预设的llm作为推理的代理模型,通过llm产生标签,达到了不花费人力标注即可获取可靠数据的效果;
18、(2)本公开实施例提供的跨模态逐步蒸馏的基础模型轻量化方法采用了逐步蒸馏的方式,只利用训练好的llm作为推理的代理模型,训练的下游任务模型尺寸小,相比直接训练llm降低了复杂度;
19、(3)该方法没有使用纯微调或蒸馏的方式,无需通过训练大量的数据就能达到与llm相似的效果;
20、(4)根据本公开实施例提供的方法训练模型没有使用带标签的数据集,即使模型尺寸不大,数据量小,模型取得了优秀的性能;
21、(5)根据本公开实施例提供的方法,将llm作为代理模型,所有模态的数据经过llm处理后转化为统一的表现格式,进行了进一步的下游任务的预测,实现了统一模态的功能。
技术特征:
1.一种跨模态逐步蒸馏的基础模型轻量化方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述将所述数据集中每条数据及其标签作为训练数据训练所述下游任务模型,并在训练过程中结合所述理由评价所述下游任务模型,得到目标下游任务模型包括:
3.根据权利要求2所述的方法,其特征在于,所述下游任务模型预测标签的损失函数为:
4.根据权利要求2所述的方法,其特征在于,所述计算关于理由的损失函数包括:
5.根据权利要求1所述的方法,其特征在于,所述模型损失函数的计算公式为:
6.根据权利要求1所述的方法,其特征在于,所述将无标签的数据集输入预设大型语言模型,抽取所述数据集中每一条数据的标签和理由包括:
7.根据权利要求6所述的方法,其特征在于,所述方法还包括:
8.一种跨模态逐步蒸馏的基础模型轻量化装置,其特征在于,包括:
技术总结
本公开提供了一种跨模态逐步蒸馏的基础模型轻量化方法,包括:采集文本数据和图像数据,形成无标签的数据集;将无标签的数据集输入预设大型语言模型,抽取数据集中每一条数据的标签和理由,理由解释了数据得到标签的原因;构建下游任务模型,下游任务模型的输入为数据,下游任务模型的输出为标签;将数据集中每条数据及其标签作为训练数据训练下游任务模型,并在训练过程中结合理由评价下游任务模型,得到目标下游任务模型。该方法可以使用较少的训练数据训练得到性能优秀的小尺寸模型。本公开还提供了一种跨模态逐步蒸馏的模型轻量化装置、设备和介质。
技术研发人员:李树超,张泽群,曾馨逸,金力,姚方龙,李晓宇,刘庆
受保护的技术使用者:中国科学院空天信息创新研究院
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!