一种用于大模型问答的文本分割检索方法与流程
本发明属于自然语言处理,具体涉及一种用于大模型问答的文本分割检索方法。
背景技术:
1、文本检索(text retrieval)亦称为自然语言检索,是指根据文本内容,如文本所包含的词语、语意等对文本集合进行检索、分类、过滤等处理。文本检索与图像检索、声音检索、图片检索等都是信息检索的一部分。通常,文本检索的结果可以通过准确率和召回率这两大基本指标进行衡量。其中,准确率通常是指检索到的相关文档除以所有被检索到的文档得到的比率;召回率也称查全率,通常是指检索出的相关文档与相关文档总数的比率。因此,如何提高文本检索的准确率或召回率是文本检索需要解决的关键问题。在文件处理方面,常规技术只处理文本或者图片中识别后的文本,对非文本类的图片信息会有丢失,对表格也是简单的文本提取处理,表格中隐藏的关系也会丢失;另外内容检索方面,单一的关键字或者语义检索,对一些较隐晦的内容检索效果较弱。
技术实现思路
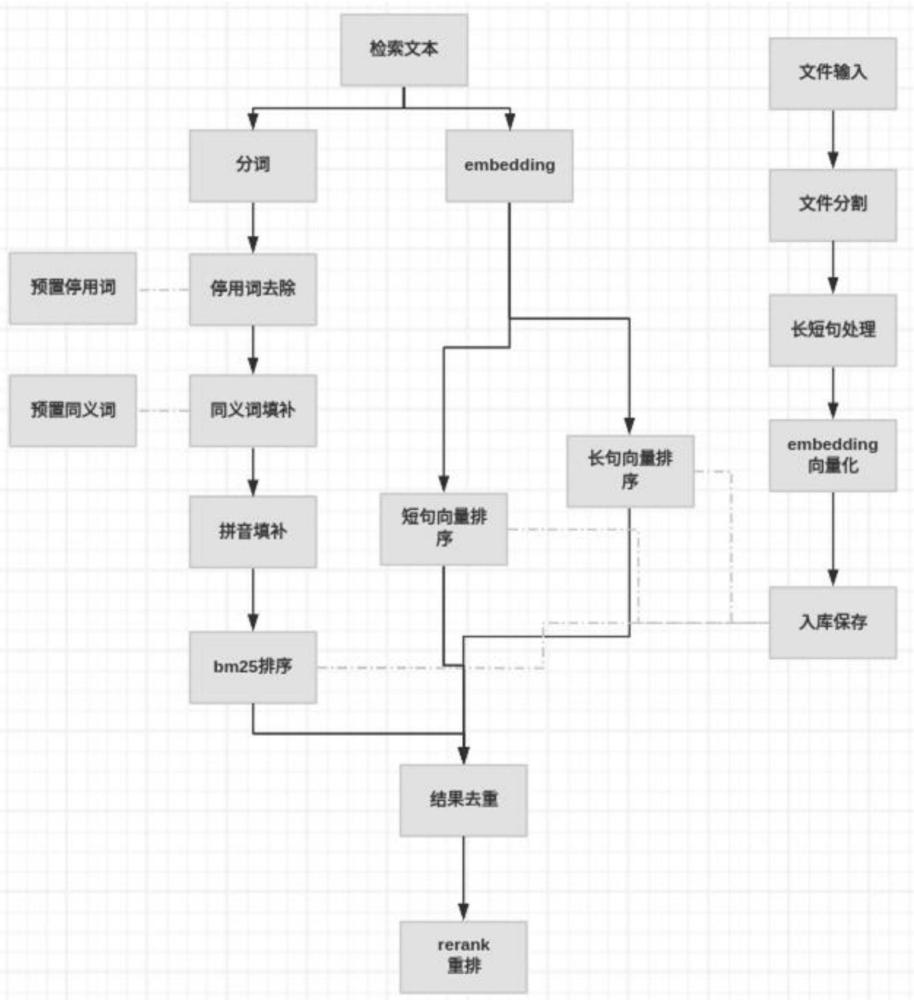
1、为解决以上现有技术存在的问题,本发明提出了一种用于大模型问答的文本分割检索方法,该方法包括:构建文本数据库和索引;获取待检索的文本数据;对待检索的文本进行分割处理;对分割后的文本数据进行嵌入处理和分词,对分词后的文本进行预处理,其中预处理包括去除停用词、拼音补充和同义词补充;通过文本数据库采用多种检索方式对预处理后的文本进行检索;采用重排模型对检索结果进行重排,得到最终的检索结果。
2、优选的,构建文本数据库和索引包括:获取完整文本数据,对完整文本数据进行分割处理;采用句末符号对分割后的语句进行短句拆分;获取拆分后的短句和段落的隶属关系,并在每个段落中生成唯一id,将id保留在子短语中;对短语和段落进行嵌入处理,得到短语的嵌入向量表示和段落的嵌入向量表示;将短句、段落、短句的嵌入向量、段落的嵌入向量以及短句隶属的段落id保存到数据库中,并建立索引。
3、进一步的,对完整文本数据进行分割处理包括:识别完整文本中的标题,采用递归分割算法对文本的标题进行分割;对文本的正文内容进行分割;识别分割后的文本中的图片信息和表格信息,根据识别出的文本信息对图片和表格进行文本替换;对经过替换后的文本数据进行字数判断,若超过字数限制,则对替换后的数据文本进行重复交叉分割,直到文本字数满足要求;当字数满足要求,则保存该文本块。
4、进一步的,采用递归分割算法对文本的标题进行分割包括:设置标题的文本长度阈值,获取待检索的文本标题字数,将标题字数与文本长度阈值进行对比,若标题字数大于文本长度阈值,则不对标题进行分割,若大于文本长度阈值,则对标题进行分割,得到一级标题和剩余标题字数;将剩余标题字数与文本长度阈值进行对比,直到标题字数符号文本长度阈值,则停止分割。
5、优选的,采用多种检索方式对预处理后的文本进行检索包括:采用ann算法对短句的嵌入向量进行比对排序;采用ann算法对段落的嵌入向量进行比对排序;采用bm25算法对段落进行关键字比对排序;根据段落id对三种检索结果进行去重。
6、进一步的,采用ann算法对短句的嵌入向量进行比对排序包括:
7、步骤1、构造数据,该数据包括生成的文本数据,文本数据包括长句和短句;
8、步骤2、将构造的数据通过embedding层映射为1024维度的数据;
9、步骤3、根据1024维度的数据通过hnsw构建20层的数据索引;索引构建过程为:设置索引构建参数,其中索引构建参数包括度量计算方法中的欧氏距离、最大连接数16以及每层的最大数目2的层数次方;遍历构造数据,随机确定每个点层数位置,对数据进行分层,每层按每个点最近的点位连接各个点,形成图;每个上层数据通过找到下层最近的一个点,形成层与层之间的连接;直到形成20层数据,得到数据索引;
10、步骤4、将查询数据向量化,即将查询数据通过embedding层映射到1024维度;
11、步骤5、采用近似最近邻搜索算法对数据索引从上层往下层进行搜索,并通过欧氏距离作为度量标准,得到搜索结果;
12、步骤6、按欧氏距离度量对搜索结果进行排序。
13、进一步的,采用bm25算法对段落进行关键字比对排序包括:关键字包含汉字和汉字对应的拼音;根据分词词表将分割后的文本进行分词;根据停用词词表剔除匹配的停用词;将剩余分词转换成拼音;统计每个分词出现的次数;并将本句子和分词关联形成倒排索引,并储存到数据库中;用户输入问题语句,对问题语句进行分词、剔除停用词以及转拼音操作;将问题语句中的中文分词和拼音分词与数据库匹配,找到匹配后的句子,并采用bm25计算公式计算该分词的得分,直到所有的分词均匹配完成,将句子中的所有分词中的得分相加,得到句子的最终得分;根据句子的最终得分值进行排序。
14、优选的,采用重排模型对检索结果进行重排包括:
15、步骤1、初步检索,使用词汇匹配模型搜索相关candidate文档,取前n个作为输入;
16、步骤2、对candidate和查询文本进行预处理,该预处理包括分词、转换小写、去停用词以及添加类bert特殊符号;
17、步骤3、构建模型输入序列,包括:查询和每个candidate用"[sep]"隔开,添加cls和sep符号,构建输入id序列;
18、步骤4、将序列输入pre-trained bert基本模型,经过12层transformer编码、最后一层output后,输出隐状态序列;
19、步骤5、对应位置提取查询和candidate隐状态,包括:查询状态h_q,candidate状态h_c;
20、步骤6、计算匹配分数scores;即对h_q与h_c内积后添加并行attention和局部特征,得到匹配分数scores;
21、步骤7、将scores通过sigmoid函数进行归一化映射,得到重排归一化权重;
22、步骤8、根据重排归一化权重对候选文档进行重新排序;
23、步骤9、输出topn作为最终结果。
24、本发明的有益效果:
25、本发明采用ann算法和bm25算法分别对短句的嵌入向量、段落的嵌入向量以及段落进行比对排序,再根据段落id对三种检索结果进行去重处理,从而降低了文本检索的复杂度,提高了检索的准确度;本发明采用递归分割算法对文本的标题进行分割,从而更加准确的提高了文本分类的准确性。
技术特征:
1.一种用于大模型问答的文本分割检索方法,其特征在于,包括:构建文本数据库和索引;获取待检索的文本数据;对待检索的文本进行分割处理;对分割后的文本数据进行嵌入处理和分词,对分词后的文本进行预处理,其中预处理包括去除停用词、拼音补充和同义词补充;通过文本数据库采用多种检索方式对预处理后的文本进行检索;采用重排模型对检索结果进行重排,得到最终的检索结果。
2.根据权利要求1所述的一种用于大模型问答的文本分割检索方法,其特征在于,构建文本数据库和索引包括:获取完整文本数据,对完整文本数据进行分割处理;采用句末符号对分割后的语句进行短句拆分;获取拆分后的短句和段落的隶属关系,并在每个段落中生成唯一id,将id保留在子短语中;对短语和段落进行嵌入处理,得到短语的嵌入向量表示和段落的嵌入向量表示;将短句、段落、短句的嵌入向量、段落的嵌入向量以及短句隶属的段落id保存到数据库中,并建立索引。
3.根据权利要求2所述的一种用于大模型问答的文本分割检索方法,其特征在于,对完整文本数据进行分割处理包括:识别完整文本中的标题,采用递归分割算法对文本的标题进行分割;对文本的正文内容进行分割;识别分割后的文本中的图片信息和表格信息,根据识别出的文本信息对图片和表格进行文本替换;对经过替换后的文本数据进行字数判断,若超过字数限制,则对替换后的数据文本进行重复交叉分割,直到文本字数满足要求;当字数满足要求,则保存该文本块。
4.根据权利要求3所述的一种用于大模型问答的文本分割检索方法,其特征在于,采用递归分割算法对文本的标题进行分割包括:设置标题的文本长度阈值,获取待检索的文本标题字数,将标题字数与文本长度阈值进行对比,若标题字数大于文本长度阈值,则不对标题进行分割,若大于文本长度阈值,则对标题进行分割,得到一级标题和剩余标题字数;将剩余标题字数与文本长度阈值进行对比,直到标题字数符号文本长度阈值,则停止分割。
5.根据权利要求1所述的一种用于大模型问答的文本分割检索方法,其特征在于,采用多种检索方式对预处理后的文本进行检索包括:采用ann算法对短句的嵌入向量进行比对排序;采用ann算法对段落的嵌入向量进行比对排序;采用bm25算法对段落进行关键字比对排序;根据段落id对三种检索结果进行去重。
6.根据权利要求5所述的一种用于大模型问答的文本分割检索方法,其特征在于,采用ann算法对短句的嵌入向量进行比对排序包括:
7.根据权利要求5所述的一种用于大模型问答的文本分割检索方法,其特征在于,采用bm25算法对段落进行关键字比对排序包括:关键字包含汉字和汉字对应的拼音;根据分词词表将分割后的文本进行分词;根据停用词词表剔除匹配的停用词;将剩余分词转换成拼音;统计每个分词出现的次数;并将本句子和分词关联形成倒排索引,并储存到数据库中;用户输入问题语句,对问题语句进行分词、剔除停用词以及转拼音操作;将问题语句中的中文分词和拼音分词与数据库匹配,找到匹配后的句子,并采用bm25计算公式计算该分词的得分,直到所有的分词均匹配完成,将句子中的所有分词中的得分相加,得到句子的最终得分;根据句子的最终得分值进行排序。
8.根据权利要求1所述的一种用于大模型问答的文本分割检索方法,其特征在于,采用重排模型对检索结果进行重排包括:
技术总结
本发明属于自然语言处理技术领域,具体涉及一种用于大模型问答的文本分割检索方法,包括:构建文本数据库和索引;获取待检索的文本数据;对待检索的文本进行分割处理;对分割后的文本数据进行嵌入处理和分词,对分词后的文本进行预处理,其中预处理包括去除停用词、拼音补充和同义词补充;通过文本数据库采用多种检索方式对预处理后的文本进行检索;采用重排模型对检索结果进行重排,得到最终的检索结果;本发明采用ANN算法和BM25算法分别对短句的嵌入向量、段落的嵌入向量以及段落进行比对排序,再根据段落ID对三种检索结果进行去重处理,从而降低了文本检索的复杂度,提高了检索的准确度。
技术研发人员:齐鹏,沈国阳,李斌,丁建勇
受保护的技术使用者:沪渝人工智能研究院
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!