一种基于爬虫的社交网络数据采集系统的制作方法
本发明涉及数据处理领域,尤其涉及一种基于爬虫的社交网络数据采集系统。
背景技术:
1、现有技术中,为了获取社交网络中的目标用户的所发布的信息,通常会采用爬虫技术对目标用户的主页进行数据爬取。但是由于过于密集的爬虫访问会增加社交网络的服务器的处理压力,导致正常用户的访问速度变慢,因此,服务器中通常会设置有反爬虫机制。为了应对反爬虫机制,常用的方法是采用较大的爬取间隔,避免出现短时间内爬取大量数据的情况。但是,由于相关的爬取间隔都是人为设定的,这就导致可能出现爬取间隔过大的情况,从而无法及时获取目标用户所发布的信息。
技术实现思路
1、本发明的目的在于公开一种基于爬虫的社交网络数据采集系统,解决如何确定合适的爬取间隔,在降低服务器的处理压力的同时,更加及时地获取目标用户在社交网络中发布的信息的问题。
2、为了达到上述目的,本发明提供如下技术方案:
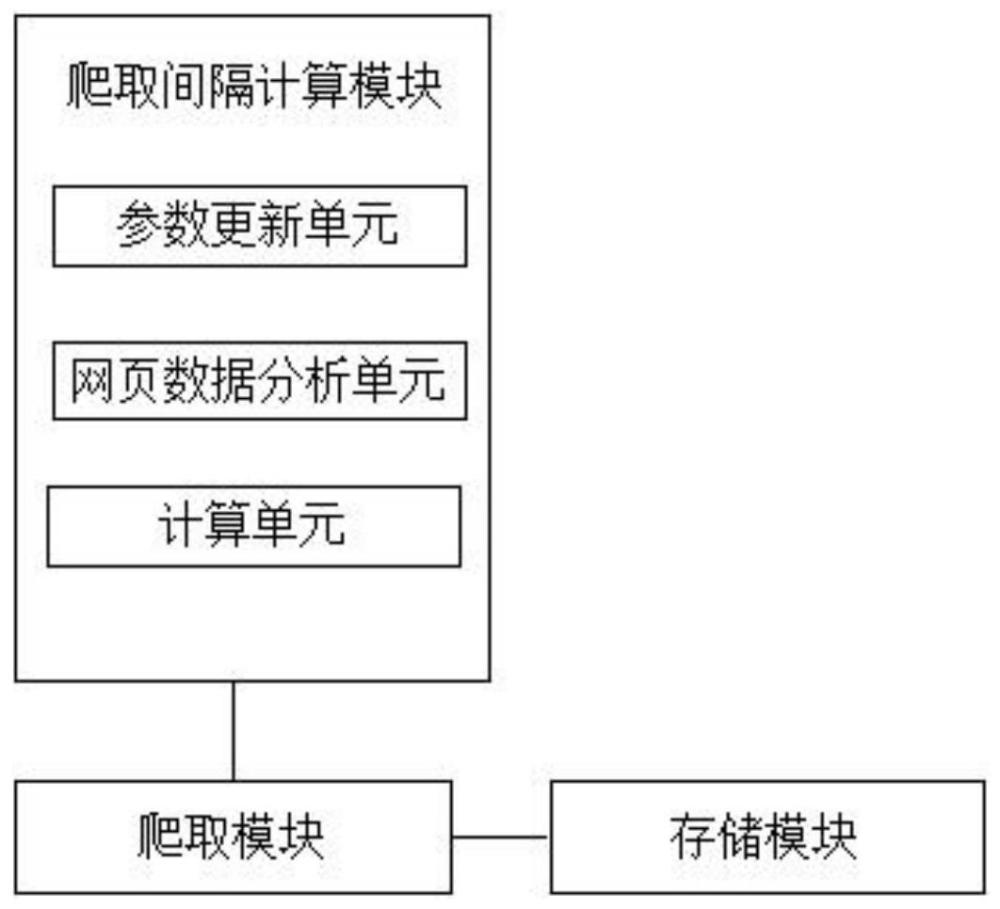
3、本发明提供了一种基于爬虫的社交网络数据采集系统,包括爬取间隔计算模块、爬取模块和存储模块;
4、爬取间隔计算模块用于计算爬取间隔;
5、爬取模块用于基于爬取间隔对目标用户发布信息的主页进行爬取,得到网页数据;
6、存储模块用于对网页数据进行存储;
7、其中,爬取间隔计算模块包括参数更新单元、网页数据分析单元和计算单元;
8、参数更新单元用于在计算爬取间隔时,对目标用户的主页进行访问,获得网络延迟;
9、网页数据分析单元用于在计算爬取间隔时,对预设时间段内爬取所得到的网页数据进行分析,得到用户发布信息的发布时间的集合和发布的信息所占用的空间的集合;
10、计算单元用于采用如下公式计算爬取间隔:
11、
12、crawitrq+1和crawitrq分别表示第q+1次和第q次计算爬取间隔时得到的爬取间隔;latq+1和latq分别表示第q+1次和第q次计算爬取间隔时所得到的网络延迟;获取预设时间段内每次爬取所得到的网页数据的发布时间,将发布时间从早到晚进行排序,得到集合timeu;reltimq+1,1和reltimq+1,2分别表示第一时间长度和第二时间长度;reltimq+1,1=actimk-actimk-1,reltimq+1,2=actimk-1-actimk-2;k表示timeu中的发布时间的总数,actimk、actimk-1和actimk-2分别表示timeu中的第k个、第k-1个和第k-2个发布时间;spaq+1,1和spaq+1,2分别表示发布时间为actimk和actimk-1的网页数据的大小,w1、w2和w3分别表示网络延迟的权重、时间长度的权重和数据大小的权重。
13、可选的,用tq+1表示第q+1次计算爬取间隔的开始时间,则预设时间段为t表示设定的时间长度。
14、可选的,还包括设置模块;
15、设置模块用于设置爬虫参数,爬虫参数包括目标用户发布信息的主页的网址。
16、可选的,第q次对目标用户发布信息的主页进行爬取的过程完成后,爬取间隔计算模块便立刻开始第q+1次计算爬取间隔。
17、可选的,基于爬取间隔对目标用户发布信息的主页进行爬取,得到网页数据,包括:
18、基于爬取间隔计算下一次对目标用户发布信息的主页进行爬取的开始时间;
19、判断当前的时间是否为下一次对目标用户发布信息的主页进行爬取的开始时间,若是,则采用爬虫算法对目标用户发布信息的主页进行爬取。
20、可选的,基于爬取间隔计算下一次对目标用户发布信息的主页进行爬取的开始时间,包括:
21、用gtq表示第q次对目标用户发布信息的主页进行爬取的开始时间,则第q+1次对目标用户发布信息的主页进行爬取的开始时间的计算公式为:
22、gtq+1=gtq+crawitrq
23、gtq+1表示第q+1次对目标用户发布信息的主页进行爬取的开始时间。
24、可选的,采用爬虫算法对目标用户发布信息的主页进行爬取,包括:
25、判断目标用户发布信息的主页是否有更新的网页数据,若是,则对更新的网页数据进行爬取,得到本次爬取所得到的网页数据。
26、可选的,判断目标用户发布信息的主页是否有更新的网页数据,包括:
27、获取目标用户发布信息的主页的url链接的集合a;
28、获取前一次对发布信息的主页进行爬取时,获得的用户发布信息的主页的url链接的集合b;
29、判断集合a中是否包含不属于集合b的url链接,若是,则表示发布信息的主页有更新的网页数据。
30、可选的,对更新的网页数据进行爬取,得到本次爬取所得到的网页数据,包括:
31、对集合a中不属于集合b的所有url链接对应的页面进行爬取,得到本次爬取所得到的网页数据。
32、可选的,对目标用户的主页进行访问,获得网络延迟,包括:
33、在开始计算爬取间隔之后,对目标用户的主页进行n次访问,基于n次访问的网络延迟获取最终确定的网络延迟。
34、有益效果:
35、与现有技术相比,本发明并不是采用固定的爬取间隔来对目标用户发布信息的主页进行爬取,而是基于相邻两次计算爬取间隔的网络延迟、相邻两次发布的时间之间的时间差值以及相邻两次发布的信息所对应的网页数据的大小三个方面来综合计算爬取间隔,使得爬取间隔能够随着网络延迟、时间差值以及网页数据的大小的变化而自适应地变化,从而能够在及时获取目标用户在社交网络中发布的信息的同时,避免过于密集地对目标用户发布信息的主页进行数据爬取,有效地降低社交网络的服务器的处理压力。
技术特征:
1.一种基于爬虫的社交网络数据采集系统,其特征在于,包括爬取间隔计算模块、爬取模块和存储模块;
2.根据权利要求1所述的一种基于爬虫的社交网络数据采集系统,其特征在于,用tq+1表示第q+1次计算爬取间隔的开始时间,则预设时间段为t表示设定的时间长度。
3.根据权利要求1所述的一种基于爬虫的社交网络数据采集系统,其特征在于,还包括设置模块;
4.根据权利要求1所述的一种基于爬虫的社交网络数据采集系统,其特征在于,第q次对目标用户发布信息的主页进行爬取的过程完成后,爬取间隔计算模块便立刻开始第q+1次计算爬取间隔。
5.根据权利要求1所述的一种基于爬虫的社交网络数据采集系统,其特征在于,基于爬取间隔对目标用户发布信息的主页进行爬取,得到网页数据,包括:
6.根据权利要求5所述的一种基于爬虫的社交网络数据采集系统,其特征在于,基于爬取间隔计算下一次对目标用户发布信息的主页进行爬取的开始时间,包括:
7.根据权利要求5所述的一种基于爬虫的社交网络数据采集系统,其特征在于,采用爬虫算法对目标用户发布信息的主页进行爬取,包括:
8.根据权利要求7所述的一种基于爬虫的社交网络数据采集系统,其特征在于,判断目标用户发布信息的主页是否有更新的网页数据,包括:
9.根据权利要求8所述的一种基于爬虫的社交网络数据采集系统,其特征在于,对更新的网页数据进行爬取,得到本次爬取所得到的网页数据,包括:
10.根据权利要求8所述的一种基于爬虫的社交网络数据采集系统,其特征在于,对目标用户的主页进行访问,获得网络延迟,包括:
技术总结
本发明属于数据处理领域,公开了一种基于爬虫的社交网络数据采集系统,包括爬取间隔计算模块、爬取模块和存储模块;爬取间隔计算模块用于计算爬取间隔;爬取模块用于基于爬取间隔对目标用户发布信息的主页进行爬取,得到网页数据;存储模块用于对网页数据进行存储;爬取间隔计算模块包括参数更新单元、网页数据分析单元和计算单元;参数更新单元用于获取网络延迟;网页数据分析单元用于基于预设时间段内爬取所得到的网页数据获取用户发布信息的发布时间的集合和发布的信息所占用的空间的集合;计算单元用于计算爬取间隔。本发明能够在及时获取目标用户在社交网络中发布的信息的同时,避免过于密集地对目标用户发布信息的主页进行数据爬取。
技术研发人员:黄春燕,郑志亮,彭高山
受保护的技术使用者:武汉威克睿特科技有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!