基于网络拓扑和图邻居采样联合优化的联邦图学习方法
本发明实施例涉及一种面向资源受限的边缘设备分布式图神经网络训练,尤其涉及一种基于网络拓扑和图邻居采样联合优化的联邦图学习方法。
背景技术:
1、在现实应用中大量的数据以图的形式存在,这些图由节点和边组成。为了处理这类图数据,人们提出了图卷积网络(graph convolutional networks,gcns)。
2、为了减少边缘网络中联邦图学习模型训练的通信开销,现有的技术主要采用以下几种方案:(1)一些现有技术提出通过每个客户端选择若干个对自己贡献最大的邻居进行连接,以此来构造一个网络拓扑,交换模型进行聚合时该客户端只和这些选中的邻居进行通信,以此来减少通信量。(2)另一些现有技术提出了一种邻居图节点采样策略,该策略为每一个客户端都分配一个不同的图邻居节点采样率,客户端根据自己的采样率进行图节点,得到一定数量用于训练的图节点,因此在训练的时候能减少不同客户端之间通信的图节点嵌入的数目。(3)还有一些现有技术提出了一种周期性的图节点采样策略,在训练时并不是每一轮都要进行图节点采样,而是每经过一段时间间隔后才采样一次,决策出最优的图采样周期也能够减少一部分通信开销。
3、然而,现有的技术方案在训练的前几轮中,每个客户端会评测周围邻居的本地模型对自己模型训练的贡献,以此进行网络拓扑的构造。但是当网络拓扑构造完成后,拓扑就一直保持不变。在动态的边缘网络中,训练的环境在不断变化,固定不变的网络拓扑无法适应变化的场景,因此会损害模型的训练效率,另外网络中训练慢的客户端会拖慢整个系统的训练速度。此外,现有的图邻居节点采样技术主要应用于传统的具有参数服务器的联邦图学习,因此在现实场景中去中心化的联邦图学习中动态的网络拓扑场景下不再适用。
技术实现思路
1、本发明提供一种基于网络拓扑和图邻居采样联合优化的联邦图学习方法,以节约网络通信资源和客户端计算资源的同时,保证分布式模型训练的高效收敛性能,并且尽可能降低系统空闲等待时间,提高训练效率。
2、本发明实施例提供了一种基于网络拓扑和图邻居采样联合优化的联邦图学习方法,定义强化学习中的状态空间、动作空间和奖励函数,所述方法包括:
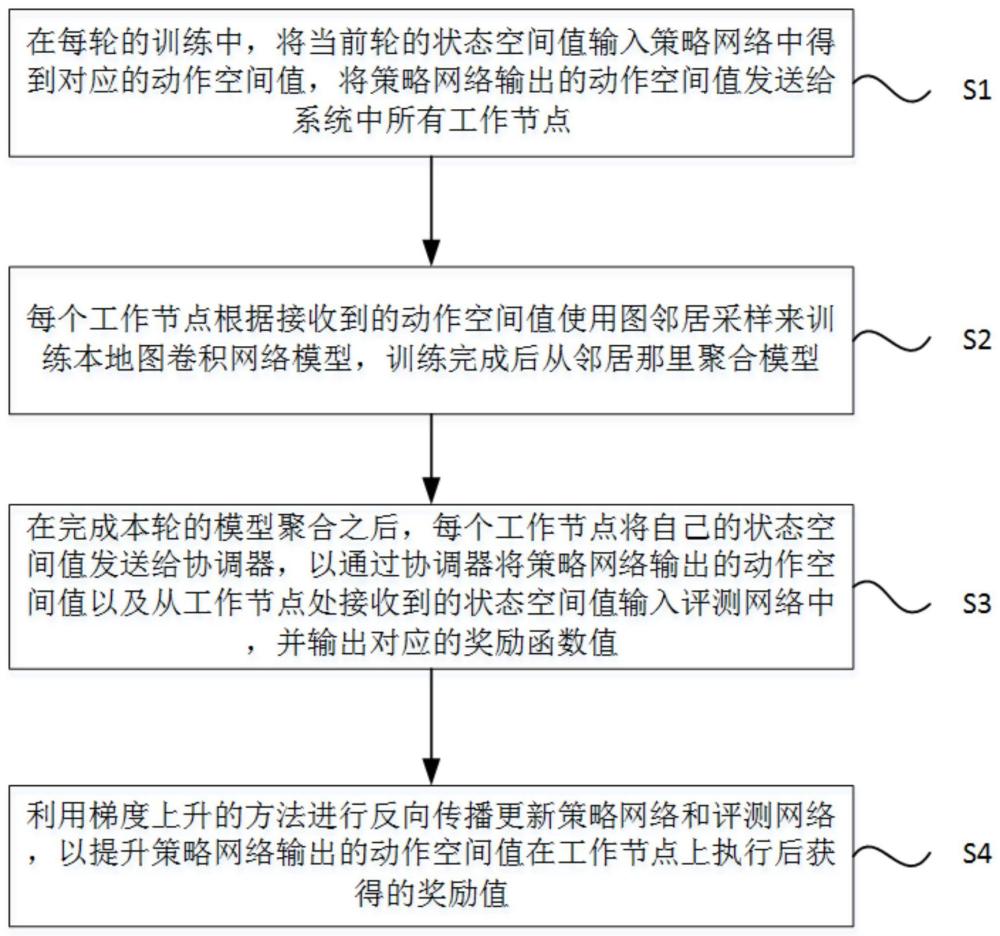
3、在每轮的训练中,将当前轮的状态空间值输入策略网络中得到对应的动作空间值,将策略网络输出的动作空间值发送给系统中所有工作节点;
4、每个工作节点根据接收到的动作空间值使用图邻居采样来训练本地图卷积网络模型,训练完成后聚合模型;
5、在完成本轮的模型聚合之后,每个工作节点将自己的状态空间值发送给协调器,以通过协调器将策略网络输出的动作空间值以及从工作节点处接收到的状态空间值输入评测网络中,并输出对应的奖励函数值;
6、利用梯度上升的方法进行反向传播更新策略网络和评测网络,以提升策略网络输出的动作空间值在工作节点上执行后获得的奖励函数值。
7、可选的,所述状态空间包括:
8、每个工作节点的网络带宽、每个工作节点完成一轮训练和模型传输所需的时间、任意两个工作节点间交换图节点嵌入的通信流量、任意两个工作节点的本地模型之间的共识距离以及每个工作节点的本地训练损失。
9、可选的,所述动作空间包括:
10、每个工作节点的图邻居节点采样率和所有工作节点之间通信的网络拓扑。
11、可选的,所述图邻居采样包括内部图邻居采样和外部图邻居采样。
12、可选的,所述奖励函数和模型训练时间、模型共识距离以及训练损失负相关。
13、本发明通过采用强化学习来联合优化网络拓扑和图邻居采样,在图联邦学习训练的过程中为其动态的调整网络拓扑结构和图邻居采样率,在节约网络通信资源和客户端计算资源的同时,保证了分布式模型训练的高效收敛性能,并且尽可能降低系统空闲等待时间,提高了图联邦学习的训练效率。
技术特征:
1.一种基于网络拓扑和图邻居采样联合优化的联邦图学习方法,其特征在于,定义强化学习中的状态空间、动作空间和奖励函数,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述状态空间包括:
3.根据权利要求1所述的方法,其特征在于,所述动作空间包括:
4.根据权利要求1所述的方法,其特征在于,所述图邻居采样包括内部图邻居采样和外部图邻居采样。
5.根据权利要求1所述的方法,其特征在于,所述奖励函数和模型训练时间、模型共识距离以及训练损失负相关。
技术总结
本发明公开了一种基于网络拓扑和图邻居采样联合优化的联邦图学习方法。其中,该方法包括:将当前轮的状态空间值输入策略网络中得到对应的动作空间值,将策略网络输出的动作空间值发送给系统中所有工作节点;每个工作节点根据动作空间值使用图邻居采样来训练本地图卷积网络模型;在完成本轮的模型聚合之后,每个工作节点将自己的状态空间值发送给协调器,协调器动作空间值以及状态空间值输入评测网络中,并输出对应的奖励函数值;利用梯度上升的方法进行反向传播更新策略网络和评测网络。本发明通过采用强化学习算法联合优化优化网络拓扑和图邻居节点采样率,节约网络通信资源和客户端计算资源的同时,能够保证分布式模型训练的高效收敛性能。
技术研发人员:刘建春,王世龙,徐宏力,闫家铭,宫建涛,刘旭东,侯坤
受保护的技术使用者:中国科学技术大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!